Latest-generation OCSR approaches built on pretrained vision-language models for improved generalization across diagram styles.
The most recent wave of OCSR methods builds on large pretrained vision-language models, using their broad visual understanding to generalize across diverse chemical diagram styles and notation conventions. GTR-CoT introduces graph-traversal chain-of-thought reasoning to guide recognition. MolParser uses an end-to-end architecture with Extended SMILES. MolNexTR combines ConvNext and ViT in a dual-stream encoder. SubGrapher takes a retrieval-oriented approach through visual fingerprinting of functional groups. This group also includes MolParser-7M, currently the largest OCSR dataset, and OCSU, which extends the task beyond structure prediction to multi-level molecular description.
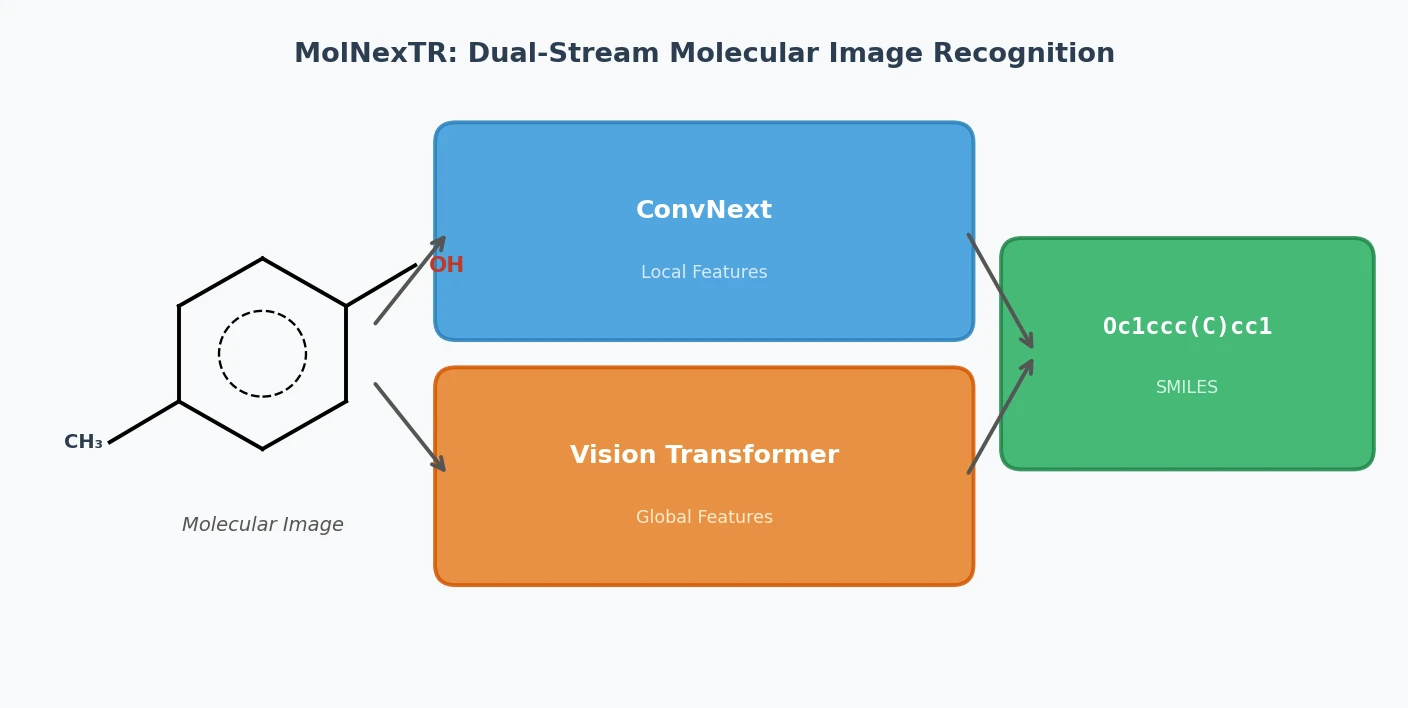
MolNexTR: A Dual-Stream Molecular Image Recognition
MolNexTR proposes a dual-stream architecture combining ConvNext and Vision Transformers to improve molecular image recognition (OCSR). It achieves 81-97% accuracy across diverse benchmarks utilizing simultaneous local and global feature extraction alongside specialized image contamination augmentations.
The MolParser project introduces two key datasets: MolParser-7M, the largest training dataset for Optical Chemical Structure Recognition (OCSR) with 7.7M pairs of images and E-SMILES strings, and WildMol, a new 20k-sample benchmark for evaluating models on challenging real-world data. The training data uniquely combines millions of diverse synthetic molecules with 400,000 manually annotated in-the-wild samples.
A 2025 end-to-end OCSR system addressing both technical and data challenges, introducing MolParser-7M (7M+ image-text pairs) and MolDet (YOLO-based detector) for extracting and recognizing molecular structures from real-world documents with diverse quality and styles.
GTR-CoT: Graph Traversal Chain-of-Thought for Molecules
A 2025 Vision-Language Model for OCSR that uses graph traversal chain-of-thought reasoning and a two-stage SFT plus GRPO training scheme to handle both printed molecules (including chemical abbreviations like Ph and Et) and hand-drawn structures, achieving strong performance on the new MolRec-Bench benchmark.
SubGrapher: Visual Fingerprinting of Chemical Structures
SubGrapher introduces a visual fingerprinting approach to Optical Chemical Structure Recognition that detects functional groups directly from images, enabling chemical database searches without full structure reconstruction and handling complex patent images including Markush structures.
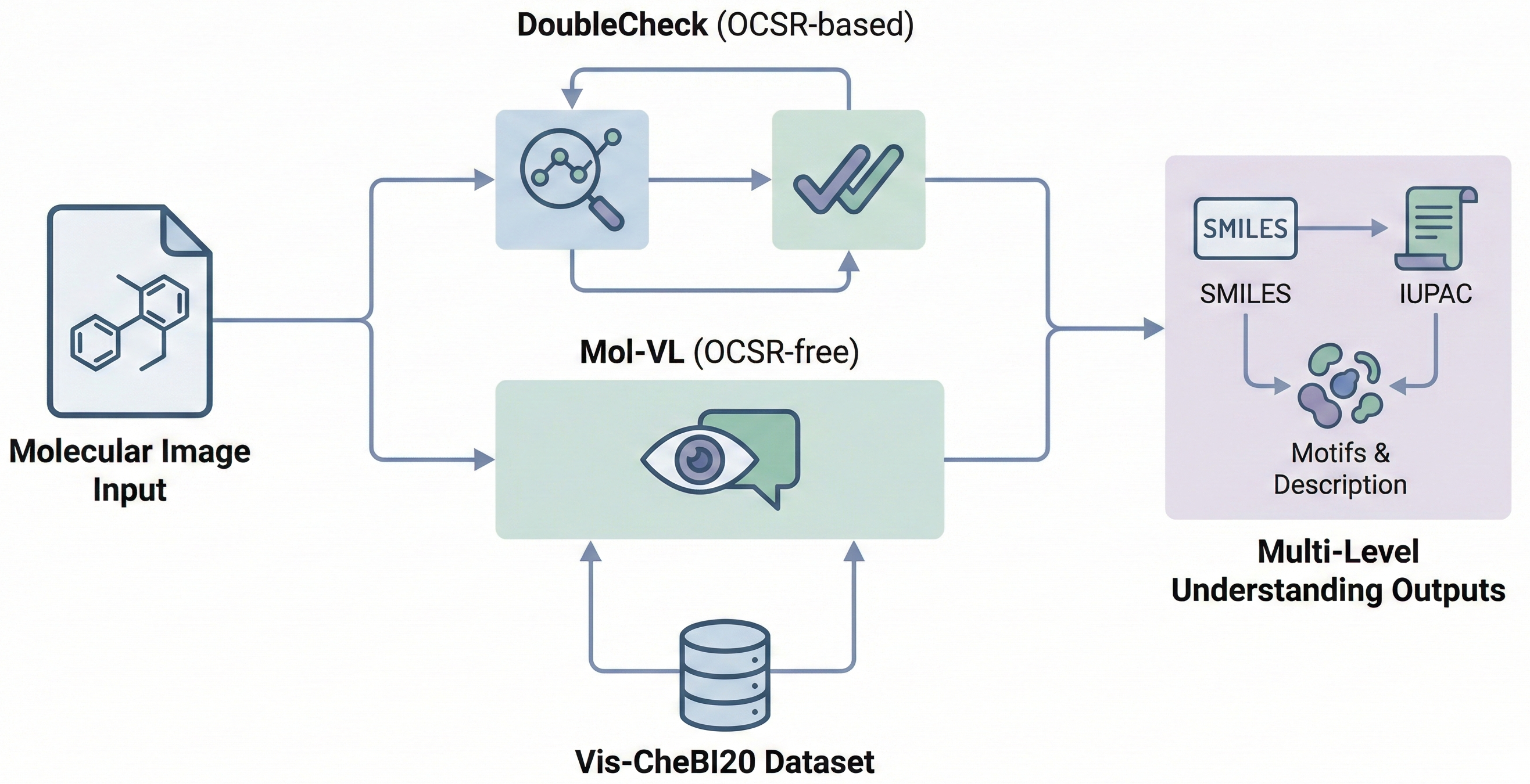
OCSU: Optical Chemical Structure Understanding (2025)
Proposes the ‘Optical Chemical Structure Understanding’ (OCSU) task to translate molecular images into multi-level descriptions (motifs, IUPAC, SMILES). Introduces the Vis-CheBI20 dataset and two paradigms: DoubleCheck (OCSR-based) and Mol-VL (OCSR-free).