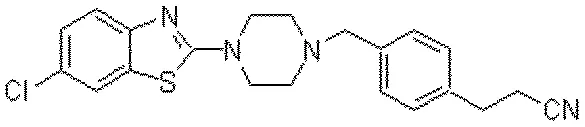The earliest OCSR systems converted raster images into vector primitives (lines, arcs, characters) and applied hand-coded chemical rules to assemble those primitives into molecular graphs. Pioneering tools like Kekulé (1992), CLiDE (1993), and the Contreras system (1990) established the core pipeline: binarize, thin, vectorize, classify atoms and bonds, then compile a connection table. Later systems such as OSRA, ChemReader, and CLiDE Pro refined each stage with better segmentation, chemical spell-checking, and support for superatom labels. The approach dominated the field for over two decades, but brittleness in the face of diverse drawing styles, noisy scans, and edge-case notation ultimately motivated the shift to learned representations.
Optical Recognition of Chemical Graphics
This paper describes an early prototype system that digitizes chemical structure diagrams from scanned documents. It employs a multi-stage pipeline involving convex bounding polygon extraction, vectorization, and rule-based heuristics to generate MDL Molfiles.