Notes on recognizing molecular structures from images, covering 35 years of methods: from rule-based vectorization to vision-language models.
A substantial fraction of chemical knowledge is recorded as 2D diagrams in journals, patents, and textbooks. Optical Chemical Structure Recognition (OCSR) is the task of extracting machine-readable molecular representations from those images: strings like SMILES (a compact text encoding of molecular structure) and InChI (a standardized identifier for chemical substances), or molecular graphs that encode atoms as nodes and bonds as edges. For a longer introduction to the field and its motivations, see the What is OCSR? post.
These notes trace the field from its origins in the early 1990s through to current vision-language approaches. Three broad eras give the collection its shape. The rule-based pioneers (1990s to mid-2010s), including tools like OSRA, MolVec, CLiDE, and Imago, vectorized images and applied hand-coded rules to classify bonds and atoms; their brittleness came from the difficulty of encoding every edge case explicitly. The deep learning transition (roughly 2015 to 2020) replaced those hand-coded rules with models that learned recognition patterns from large synthetic datasets, yielding both image-to-sequence architectures (DECIMER, Img2Mol, Image2SMILES) and image-to-graph architectures (MolGrapher, MolScribe). The current vision-language era (2021 onward), with models like MolParser, GTR-Mol-VLM, and Subgrapher, builds on large pretrained vision-language models to improve generalization across diverse diagram styles and chemical notation conventions.
Beyond the core recognition systems, the collection includes review papers, benchmark and competition write-ups (TREC-Chem 2011, CLEF-IP 2012), and notes on specialized sub-tasks: hand-drawn structure recognition, Markush structure detection, and component-level problems like ring and bond parsing.
For orientation, the two survey papers are the best starting points: rajan-ocsr-review-2020 covers the rule-based era and benchmarks the transition period, while musazade-ocsr-review-2022 picks up the thread with deep learning methods.
MolRec: Chemical Structure Recognition at CLEF 2012
Performance evaluation of MolRec at the CLEF 2012 competition reveals a stark performance gap between simple (95%+ accuracy) and complex molecular structures (46-59% accuracy), providing systematic analysis of rule-based OCSR limitations including touching characters, stereochemistry recognition, and four-way junction failures.
Details the MolRec system for converting chemical diagram images into MOL files using vectorization, geometric rules, and graph construction. Achieved 95% accuracy on 1000 TREC 2011 benchmark images with comprehensive failure analysis of limitations.
SubGrapher: Visual Fingerprinting of Chemical Structures
SubGrapher introduces a visual fingerprinting approach to Optical Chemical Structure Recognition that detects functional groups directly from images, enabling chemical database searches without full structure reconstruction and handling complex patent images including Markush structures.
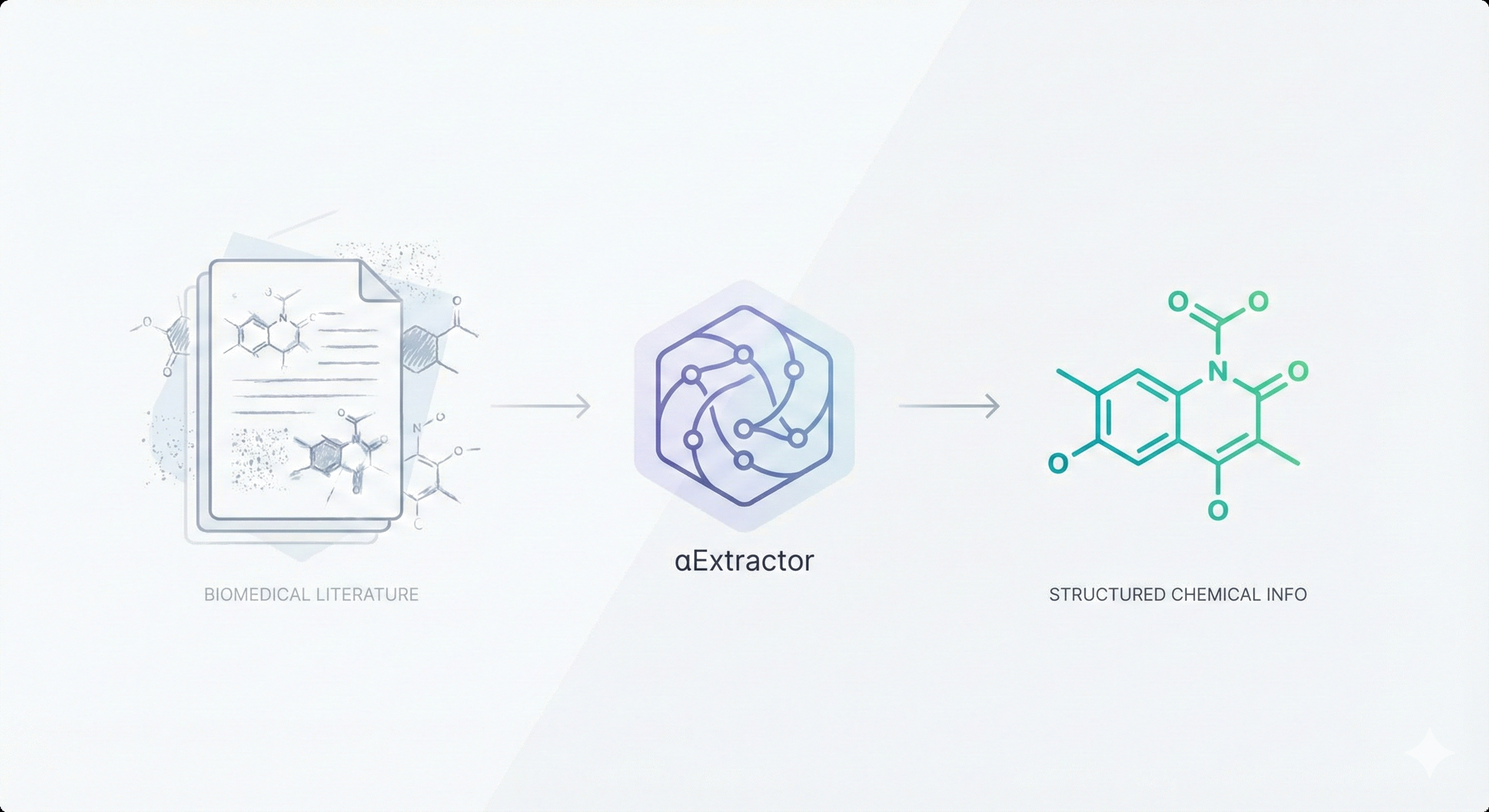
αExtractor: Chemical Info from Biomedical Literature
A 2024 deep learning system for optical chemical structure recognition designed specifically for biomedical literature mining, using ResNet-Transformer architecture to handle challenging conditions including low-resolution images, noise, distortions, and even hand-drawn molecular diagrams from scientific documents.
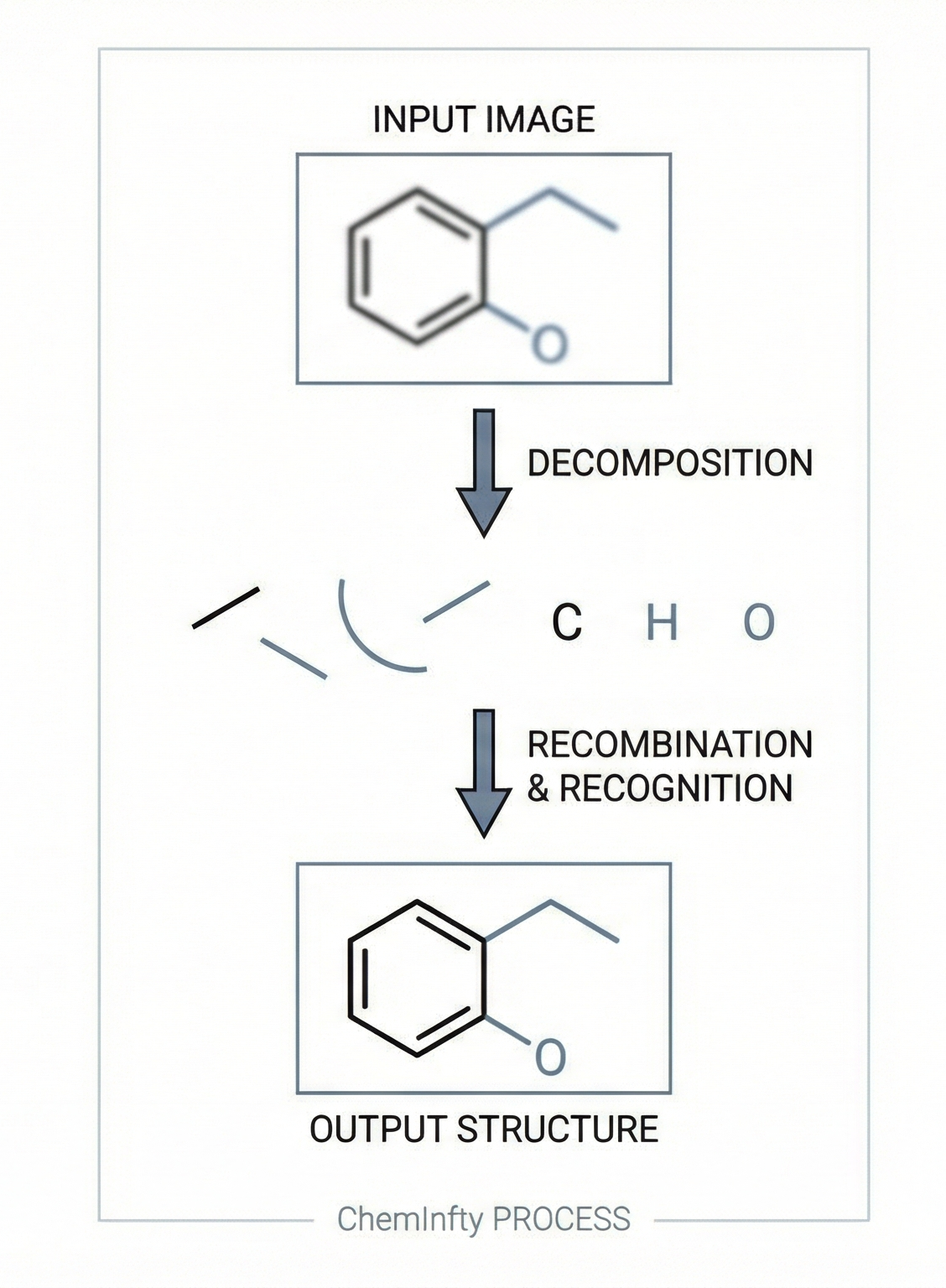
ChemInfty: Chemical Structure Recognition in Patent Images
A 2011 rule-based OCSR system designed specifically for the challenging low-quality images in Japanese patent applications, using segment-based methods to handle pervasive problems like touching characters, merged atom labels with bonds, and broken lines.
MolNexTR proposes a dual-stream architecture combining ConvNext and Vision Transformers to improve molecular image recognition (OCSR). It achieves 81-97% accuracy across diverse benchmarks utilizing simultaneous local and global feature extraction alongside specialized image contamination augmentations.
The MolParser project introduces two key datasets: MolParser-7M, the largest training dataset for Optical Chemical Structure Recognition (OCSR) with 7.7M pairs of images and E-SMILES strings, and WildMol, a new 20k-sample benchmark for evaluating models on challenging real-world data. The training data uniquely combines millions of diverse synthetic molecules with 400,000 manually annotated in-the-wild samples to significantly enhance model robustness.
A 2024 end-to-end OCSR system addressing both technical and data challenges, introducing MolParser-7M (7M+ image-text pairs) and MolDet (YOLO-based detector) for extracting and recognizing molecular structures from real-world documents with diverse quality and styles.