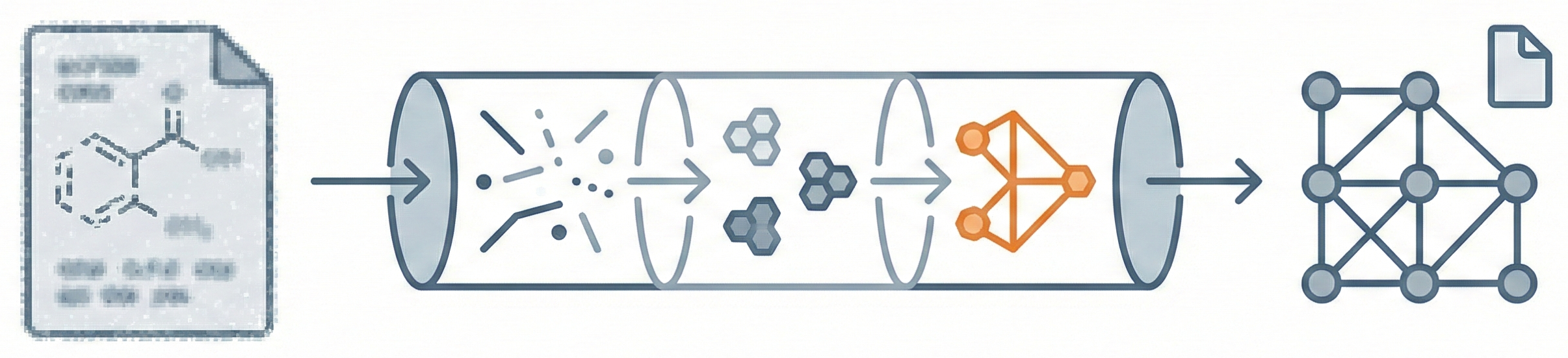
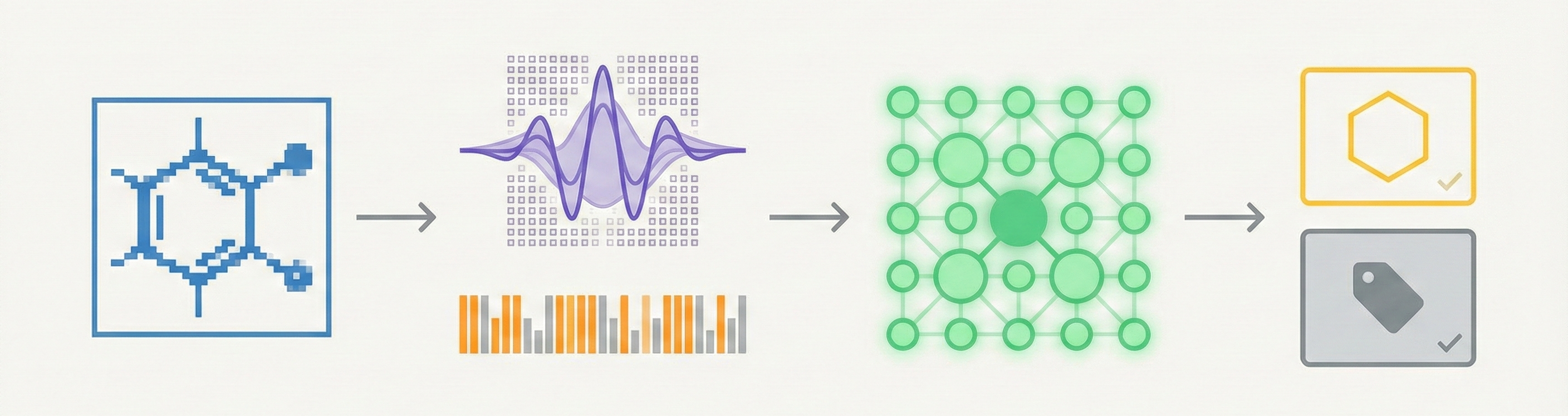
Notes on recognizing molecular structures from images, covering 35 years of methods: from rule-based vectorization to vision-language models.
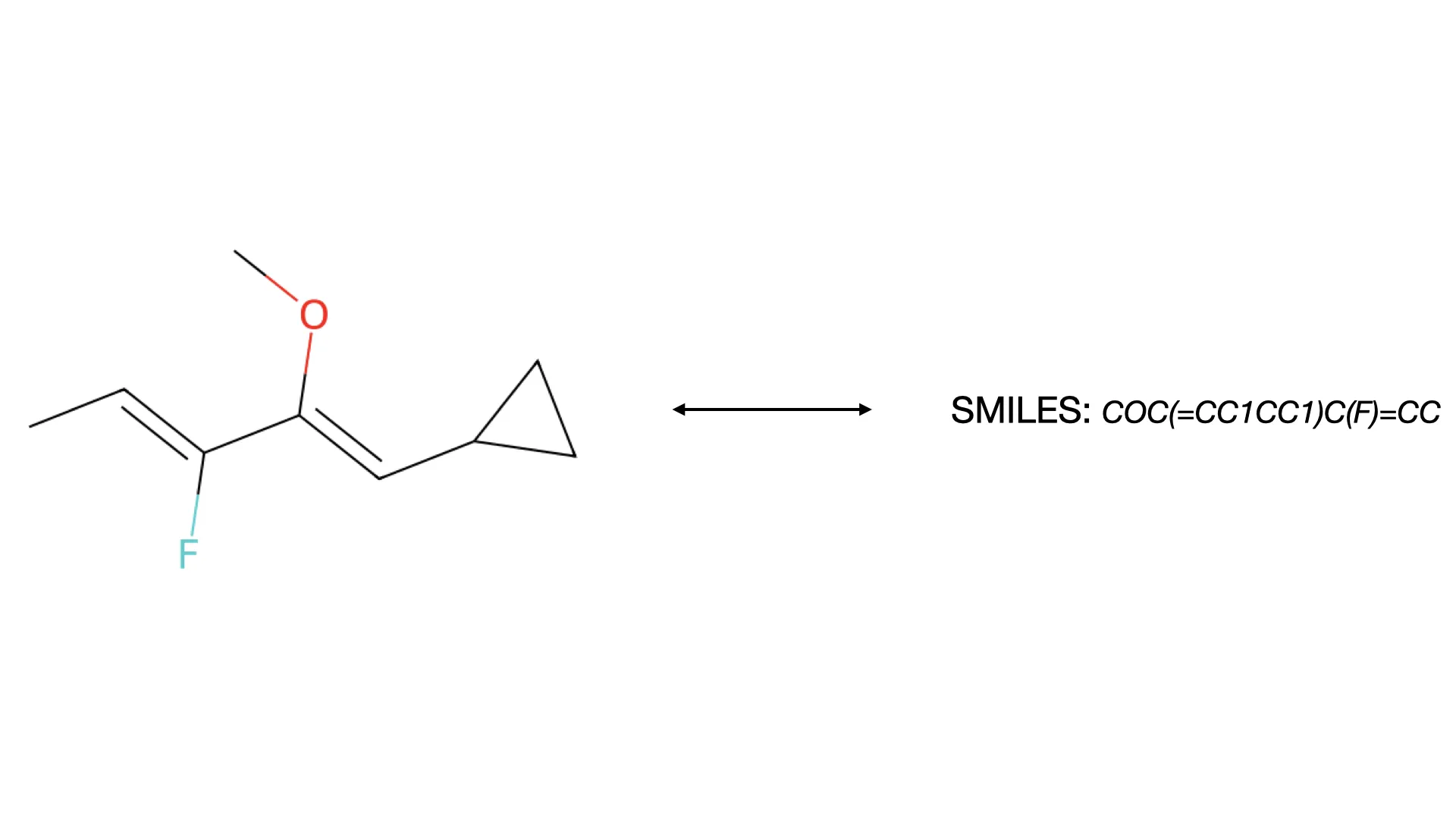
A substantial fraction of chemical knowledge is recorded as 2D diagrams in journals, patents, and textbooks. Optical Chemical Structure Recognition (OCSR) is the task of extracting machine-readable molecular representations from those images: strings like SMILES (a compact text encoding of molecular structure) and InChI (a standardized identifier for chemical substances), or molecular graphs that encode atoms as nodes and bonds as edges. For a longer introduction to the field and its motivations, see the What is OCSR? post.
These notes trace the field from its origins in the early 1990s through to current vision-language approaches. Three broad eras give the collection its shape. The rule-based pioneers (1990s to mid-2010s), including tools like OSRA, MolVec, CLiDE, and Imago, vectorized images and applied hand-coded rules to classify bonds and atoms; their brittleness came from the difficulty of encoding every edge case explicitly. The deep learning transition (roughly 2015 to 2020) replaced those hand-coded rules with models that learned recognition patterns from large synthetic datasets, yielding both image-to-sequence architectures (DECIMER, Img2Mol, Image2SMILES) and image-to-graph architectures (MolGrapher, MolScribe). The current vision-language era (2021 onward), with models like MolParser, GTR-Mol-VLM, and Subgrapher, builds on large pretrained vision-language models to improve generalization across diverse diagram styles and chemical notation conventions.
Beyond the core recognition systems, the collection includes review papers, benchmark and competition write-ups (TREC-Chem 2011, CLEF-IP 2012), and notes on specialized sub-tasks: hand-drawn structure recognition, Markush structure detection, and component-level problems like ring and bond parsing.
For orientation, the two survey papers are the best starting points: rajan-ocsr-review-2020 covers the rule-based era and benchmarks the transition period, while musazade-ocsr-review-2022 picks up the thread with deep learning methods.
Chemical Literature Data Extraction: The CLiDE Project
The CLiDE project presents a foundational architecture for Optical Chemical Structure Recognition (OCSR). It details a three-phase pipeline to convert bitmapped journal pages into chemically significant connection tables, handling complex features like stereochemistry.
This 2003 paper introduces a machine vision approach for extracting chemical metadata from raster images. By using Gabor wavelets for feature extraction and Kohonen networks for classification, it distinguishes between chemical and non-chemical images, as well as ring and non-ring systems, without requiring high-resolution inputs.
This paper presents ChemReader, a fully automated optical structure recognition tool that converts raster images of chemical diagrams into machine-readable formats. It introduces a modified Hough transform for bond detection and a chemical spell checker that improves OCR accuracy from 66% to 87%.
This 1990 paper presents an early OCR pipeline for converting hand-drawn or printed chemical structures into connectivity tables. It introduces novel sweeping algorithms for graph perception and a matrix-based feature extraction method for character recognition.
An early method paper (AAAI ‘07) proposing a multi-stage sketch recognition pipeline. It introduces a domain verification step that uses chemical rules to refine ink parsing, achieving a 27% error reduction over geometric-only baselines.
IMG2SMI: Translating Molecular Structure Images to SMILES
A 2021 image-to-text approach treating OCSR as an image captioning task. It uses Transformers with SELFIES representation to convert molecular structure diagrams into SMILES strings, unlocking visual chemical knowledge from scientific literature.
This 1992 paper introduces Kekulé, one of the first complete Optical Chemical Structure Recognition (OCSR) systems. It details a pipeline integrating raster-to-vector conversion, neural network-based OCR, and rule-based logic to convert printed chemical diagrams into connection tables.
A comprehensive categorization of OCSR methods, organizing techniques by their fundamental approach: deep learning, traditional ML, and rule-based systems.
This paper describes an early prototype system that digitizes chemical structure diagrams from scanned documents. It employs a multi-stage pipeline involving convex bounding polygon extraction, vectorization, and rule-based heuristics to generate MDL Molfiles.
This paper presents OSRA, the first open-source utility for converting graphical chemical structures from documents into machine-readable formats (SMILES/SD). It outlines a pipeline combining existing image processing tools with custom heuristics for bond and atom detection, establishing a foundation for accessible chemical information extraction.
This methodological paper proposes a comprehensive pipeline to digitize chemical structure images. It achieves 97% reconstruction accuracy on benchmarks by combining a topology-preserving vectorizer with a chemical knowledge validation module.
GTR-CoT: Graph Traversal Chain-of-Thought for Molecules
A 2025 Vision-Language Model for OCSR that uses graph traversal chain-of-thought reasoning to handle chemical abbreviations (Ph, Et, etc.) that break existing systems, achieving state-of-the-art performance by training on data where abbreviations are preserved.