Notes on recognizing molecular structures from images, covering 35 years of methods: from rule-based vectorization to vision-language models.
A substantial fraction of chemical knowledge is recorded as 2D diagrams in journals, patents, and textbooks. Optical Chemical Structure Recognition (OCSR) is the task of extracting machine-readable molecular representations from those images: strings like SMILES (a compact text encoding of molecular structure) and InChI (a standardized identifier for chemical substances), or molecular graphs that encode atoms as nodes and bonds as edges. For a longer introduction to the field and its motivations, see the What is OCSR? post.
These notes trace the field from its origins in the early 1990s through to current vision-language approaches. Three broad eras give the collection its shape. The rule-based pioneers (1990s to mid-2010s), including tools like OSRA, MolVec, CLiDE, and Imago, vectorized images and applied hand-coded rules to classify bonds and atoms; their brittleness came from the difficulty of encoding every edge case explicitly. The deep learning transition (roughly 2015 to 2020) replaced those hand-coded rules with models that learned recognition patterns from large synthetic datasets, yielding both image-to-sequence architectures (DECIMER, Img2Mol, Image2SMILES) and image-to-graph architectures (MolGrapher, MolScribe). The current vision-language era (2021 onward), with models like MolParser, GTR-Mol-VLM, and Subgrapher, builds on large pretrained vision-language models to improve generalization across diverse diagram styles and chemical notation conventions.
Beyond the core recognition systems, the collection includes review papers, benchmark and competition write-ups (TREC-Chem 2011, CLEF-IP 2012), and notes on specialized sub-tasks: hand-drawn structure recognition, Markush structure detection, and component-level problems like ring and bond parsing.
For orientation, the two survey papers are the best starting points: rajan-ocsr-review-2020 covers the rule-based era and benchmarks the transition period, while musazade-ocsr-review-2022 picks up the thread with deep learning methods.
Image2SMILES: Transformer OCSR with Synthetic Data Pipeline
A Transformer-based system for optical chemical structure recognition introducing a comprehensive data generation pipeline (FG-SMILES, Markush structures, visual contamination) achieving 79% accuracy on real-world images, outperforming rule-based systems like OSRA.
MICER: Molecular Image Captioning with Transfer Learning
MICER treats optical chemical structure recognition as an image captioning task, leveraging transfer learning with a fine-tuned ResNet encoder and attention-based LSTM decoder to convert molecular images into SMILES strings, significantly outperforming rule-based and previous deep learning methods.
MolMiner: Deep Learning OCSR with YOLOv5 Detection
MolMiner replaces traditional rule-based vectorization with a deep learning object detection pipeline (YOLOv5) to extract chemical structures from PDFs. It achieves state-of-the-art performance on benchmarks and introduces a new real-world dataset of 3,040 images.
One Strike, You're Out: Detecting Markush Structures
Proposes a patch-based image processing pipeline using Inception V3 to filter Markush structures from chemical documents, significantly outperforming traditional fixed-feature (ORB) methods on low-SNR images.
This systematization paper traces the history of OCSR, comparing early rule-based systems like OSRA with modern deep learning approaches like DECIMER. It highlights the shift from image classification to image captioning and identifies critical gaps in dataset standardization and evaluation metrics.
String Representations for Chemical Image Recognition
This methodological study isolates the impact of chemical string representations on image-to-text translation models. It finds that while SMILES offers the highest overall accuracy, SELFIES provides a guarantee of structural validity, offering a trade-off for OCSR tasks.
Proposes an end-to-end architecture replacing standard CNN backbones with Swin Transformer to capture global image context. Introduces Multi-label Focal Loss to handle severe token imbalance in chemical datasets.
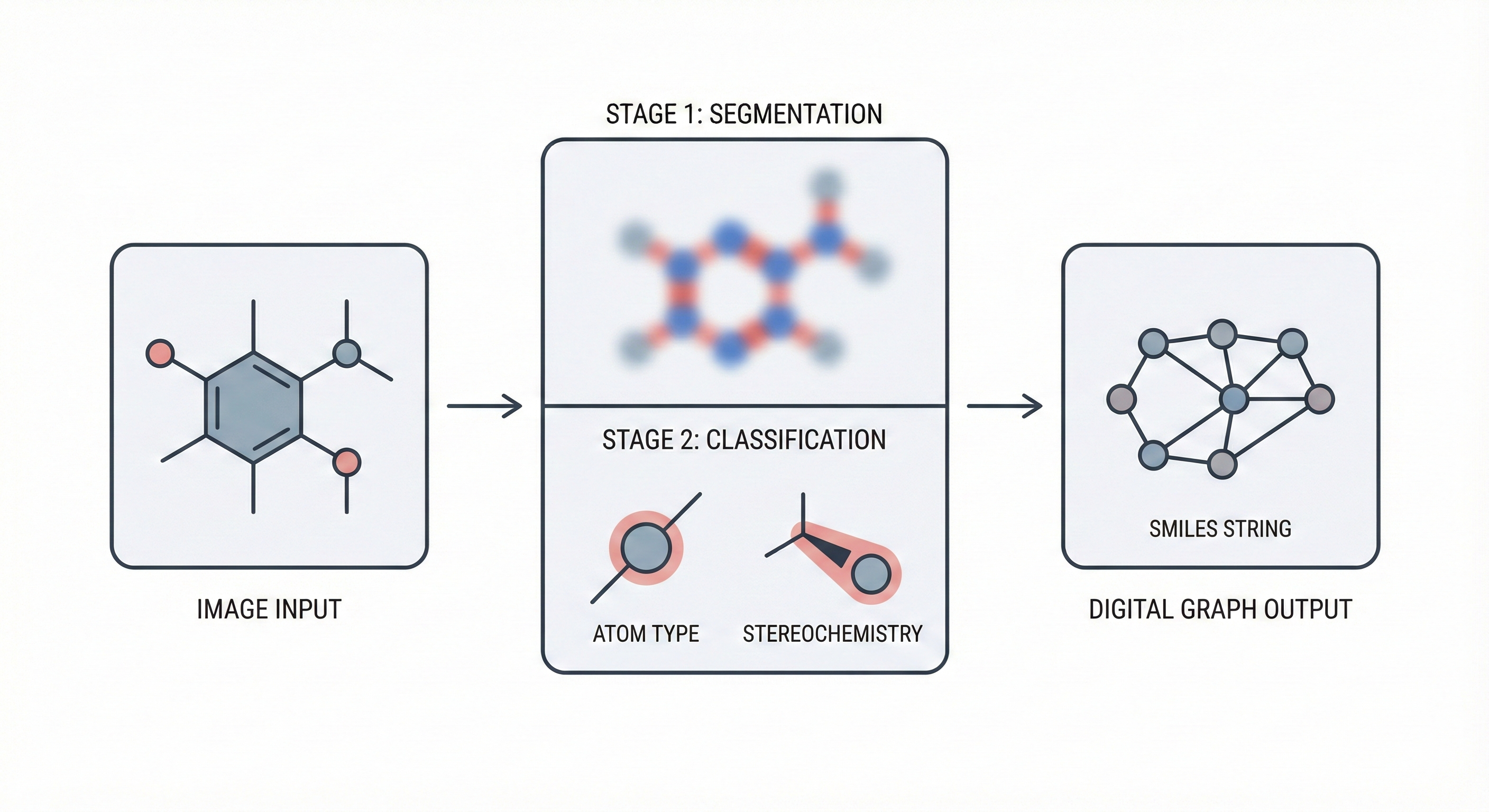
ChemGrapher replaces rule-based chemical OCR with a deep learning pipeline using semantic segmentation to identify atom and bond candidates, followed by specialized classification networks to resolve stereochemistry and bond multiplicity, significantly outperforming OSRA.
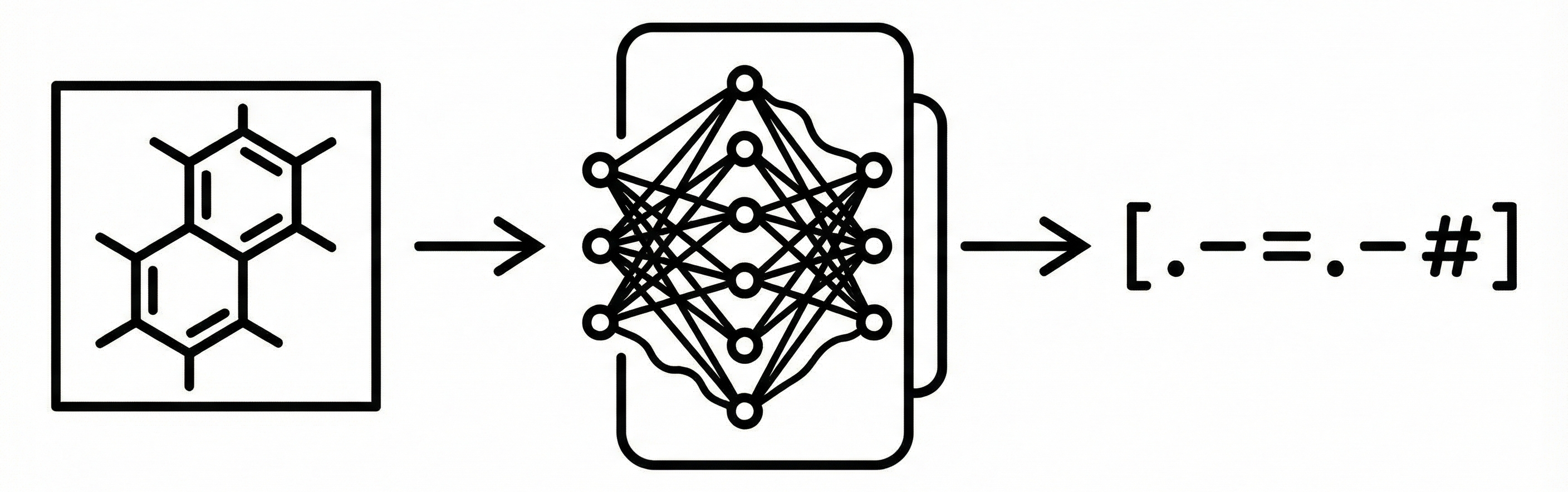
DECIMER: Deep Learning for Chemical Image Recognition
DECIMER adapts the “Show, Attend and Tell” image captioning architecture to translate chemical structure images into SMILES strings. By leveraging massive synthetic datasets generated from PubChem, it demonstrates that deep learning can perform optical chemical recognition without complex, hand-engineered rule systems.
This paper presents a two-stage deep learning pipeline to extract chemical structures from documents and convert them to SMILES strings. By training on large-scale synthetic data, the method overcomes the brittleness of rule-based systems and demonstrates high accuracy even on low-resolution and noisy input images.
Proposes a specialized Classifier-Recognizer architecture that first categorizes rings by heteroatom (S, N, O) and then identifies the specific ring using optimized grid inputs.
Handwritten Chemical Symbol Recognition Using SVMs
A 2013 paper introducing a hybrid recognition system for handwritten chemical symbols on touch devices. Combines Support Vector Machines (SVM) for classification with elastic matching for geometric verification, achieving 89.7% top-1 accuracy on pen-based input for chemical structure drawing applications.