Notes on recognizing molecular structures from images, covering 35 years of methods: from rule-based vectorization to vision-language models.
A substantial fraction of chemical knowledge is recorded as 2D diagrams in journals, patents, and textbooks. Optical Chemical Structure Recognition (OCSR) is the task of extracting machine-readable molecular representations from those images: strings like SMILES (a compact text encoding of molecular structure) and InChI (a standardized identifier for chemical substances), or molecular graphs that encode atoms as nodes and bonds as edges. For a longer introduction to the field and its motivations, see the What is OCSR? post.
These notes trace the field from its origins in the early 1990s through to current vision-language approaches. Three broad eras give the collection its shape. The rule-based pioneers (1990s to mid-2010s), including tools like OSRA, MolVec, CLiDE, and Imago, vectorized images and applied hand-coded rules to classify bonds and atoms; their brittleness came from the difficulty of encoding every edge case explicitly. The deep learning transition (roughly 2015 to 2020) replaced those hand-coded rules with models that learned recognition patterns from large synthetic datasets, yielding both image-to-sequence architectures (DECIMER, Img2Mol, Image2SMILES) and image-to-graph architectures (MolGrapher, MolScribe). The current vision-language era (2021 onward), with models like MolParser, GTR-Mol-VLM, and Subgrapher, builds on large pretrained vision-language models to improve generalization across diverse diagram styles and chemical notation conventions.
Beyond the core recognition systems, the collection includes review papers, benchmark and competition write-ups (TREC-Chem 2011, CLEF-IP 2012), and notes on specialized sub-tasks: hand-drawn structure recognition, Markush structure detection, and component-level problems like ring and bond parsing.
For orientation, the two survey papers are the best starting points: rajan-ocsr-review-2020 covers the rule-based era and benchmarks the transition period, while musazade-ocsr-review-2022 picks up the thread with deep learning methods.
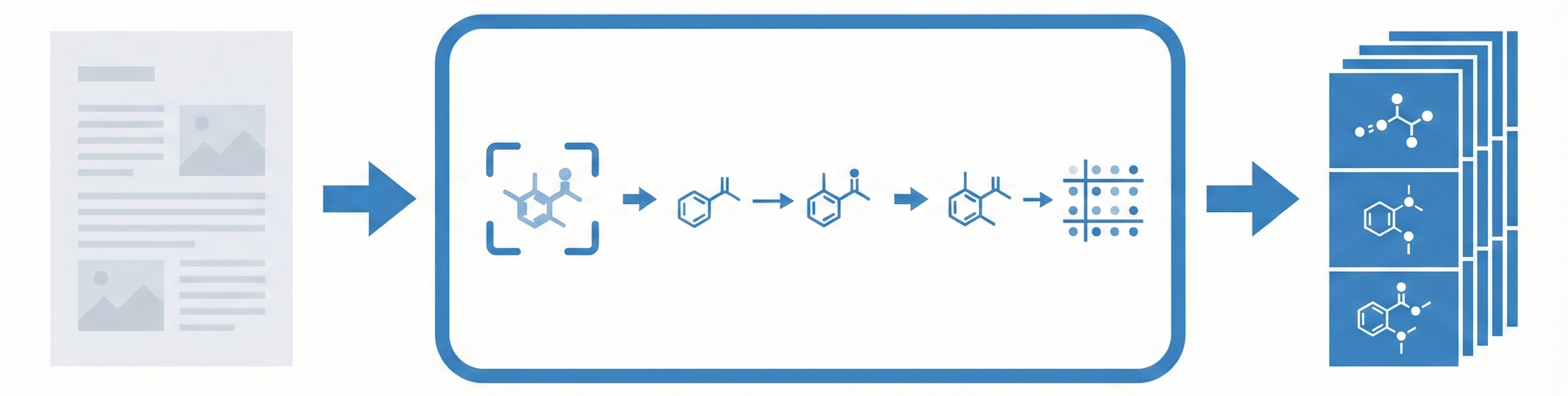
MolMole: Unified Vision Pipeline for Molecule Mining
MolMole unifies molecule detection, reaction parsing, and structure recognition into a single vision-based pipeline, achieving SOTA performance on a newly introduced 550-page benchmark by processing full documents without external layout parsers.
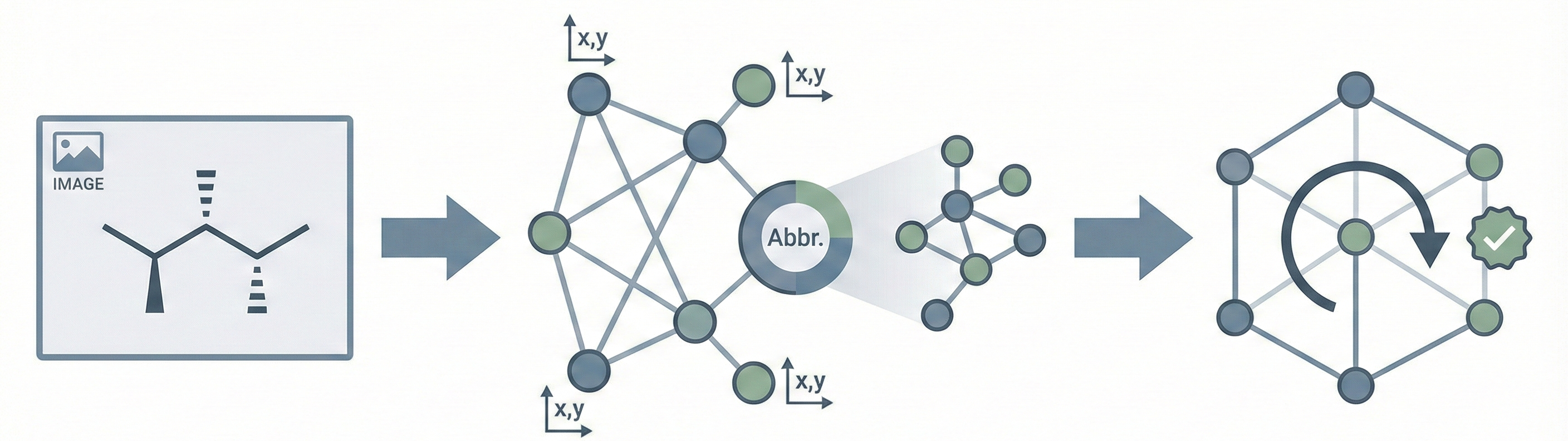
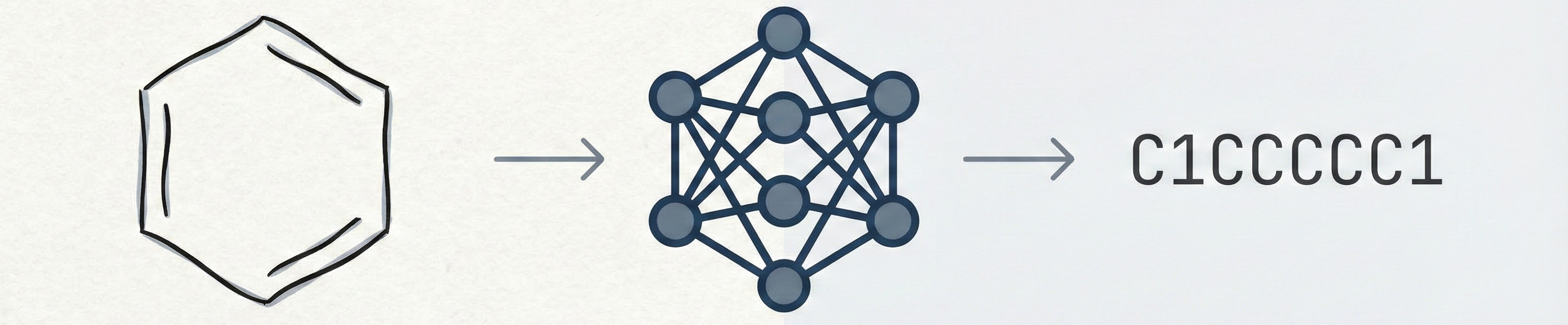
MolScribe reformulates molecular recognition as an image-to-graph generation task, explicitly predicting atom coordinates and bonds to better handle stereochemistry and abbreviated structures compared to image-to-SMILES baselines.
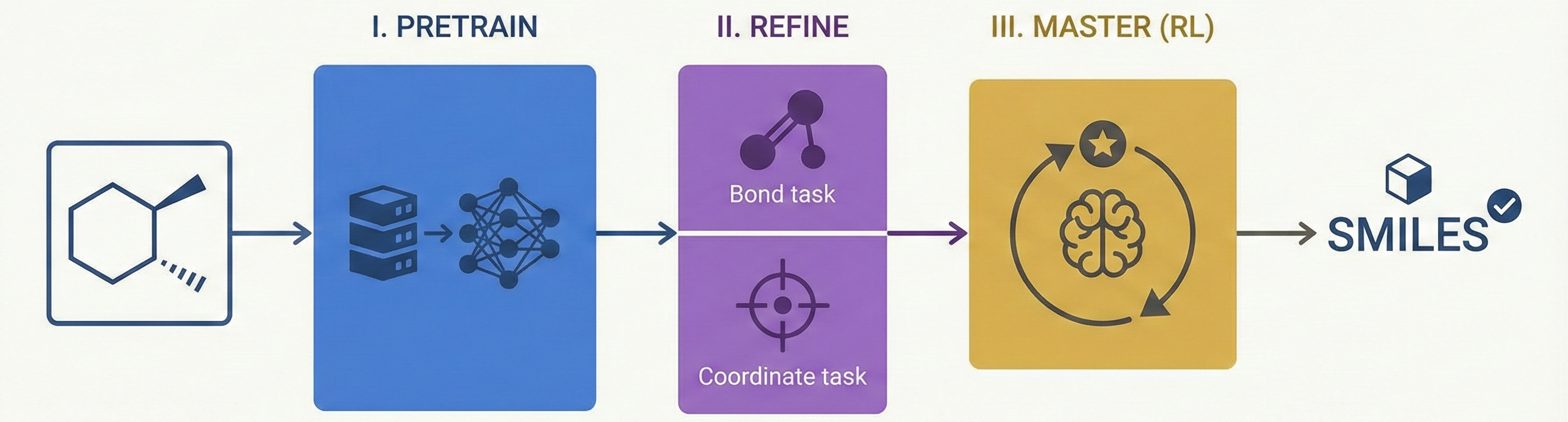
MolSight: OCSR with RL and Multi-Granularity Learning
MolSight introduces a three-stage training paradigm for Optical Chemical Structure Recognition (OCSR), utilizing large-scale pretraining, multi-granularity fine-tuning with auxiliary bond and coordinate prediction tasks, and reinforcement learning (GRPO) to achieve state-of-the-art performance in recognizing complex stereochemical structures like chiral centers and cis-trans isomers.
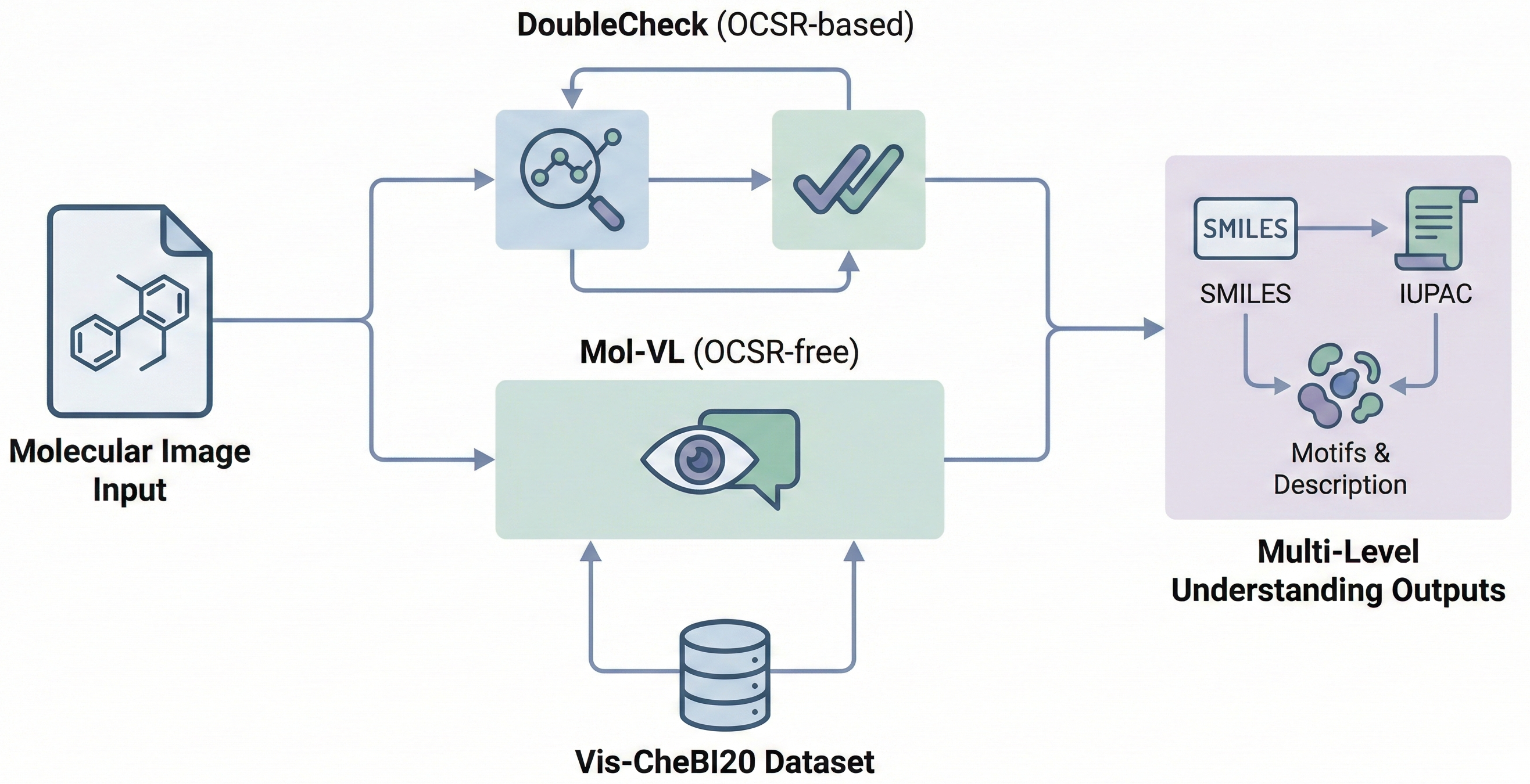
Proposes the ‘Optical Chemical Structure Understanding’ (OCSU) task to translate molecular images into multi-level descriptions (motifs, IUPAC, SMILES). Introduces the Vis-CheBI20 dataset and two paradigms: DoubleCheck (OCSR-based) and Mol-VL (OCSR-free).
Proposes Ring-Free Language (RFL) to hierarchically decouple molecular graphs into skeletons, rings, and branches, solving issues with 1D serialization of complex 2D structures. Introduces the Molecular Skeleton Decoder (MSD) to progressively predict these components, achieving state-of-the-art results on handwritten and printed chemical structures.
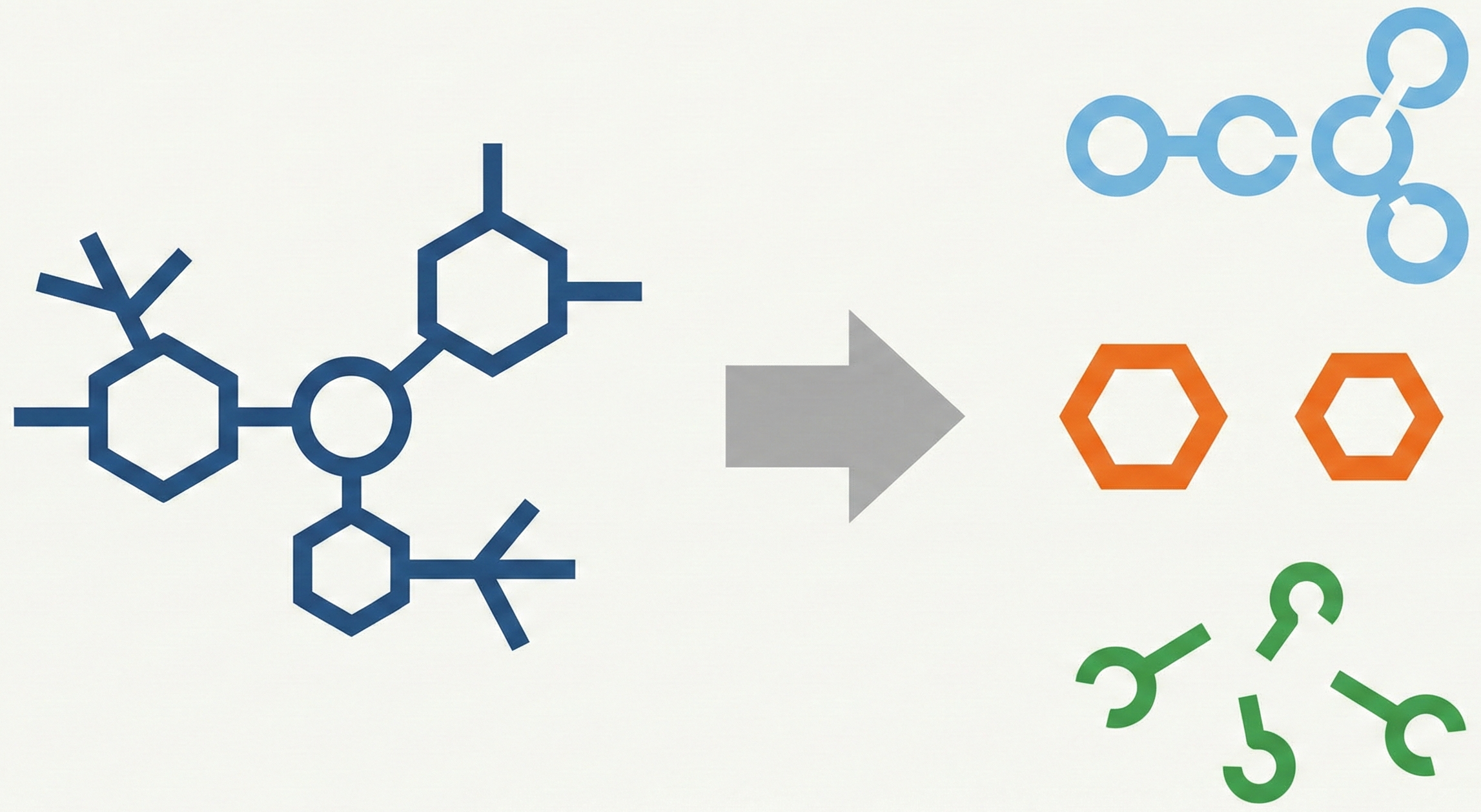
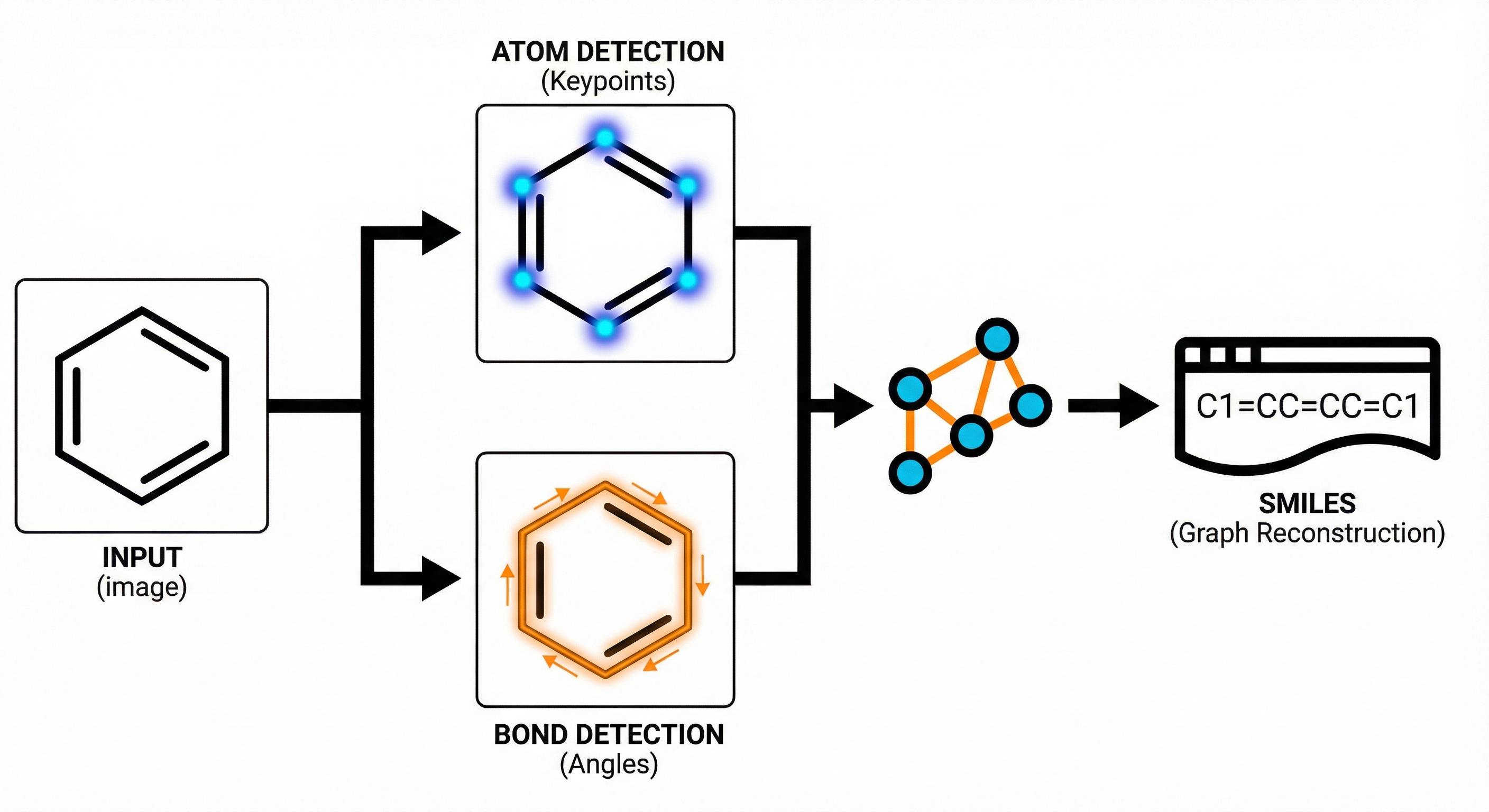
ABC-Net reformulates molecular image recognition as a keypoint detection problem. By predicting atom/bond centers and properties via a single Fully Convolutional Network, it achieves >94% accuracy with high data efficiency.
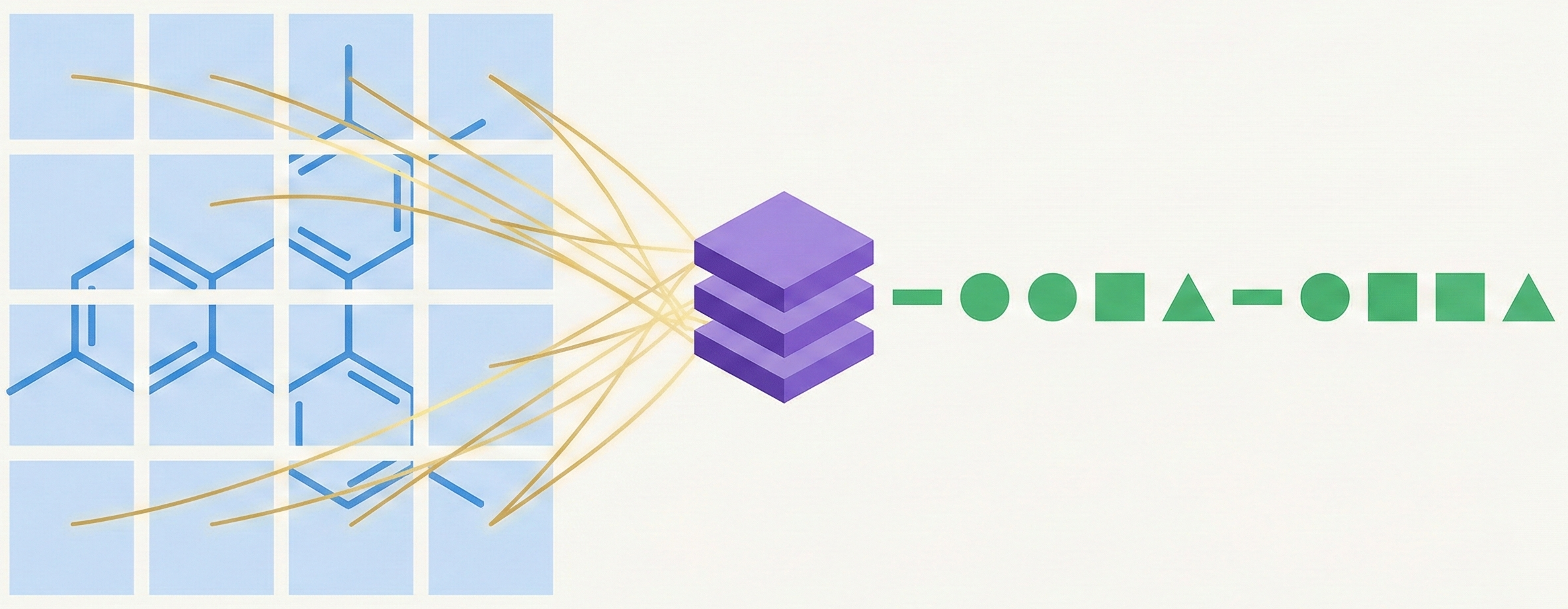
Proposes a CNN-LSTM architecture that treats chemical structure recognition as an image captioning task. Introduces a robust synthetic data generation pipeline with augmentation, degradation, and background addition to train models that generalize to hand-drawn inputs without seeing real data during pre-training.
DECIMER 1.0: Transformers for Chemical Image Recognition
DECIMER 1.0 introduces a Transformer-based architecture coupled with EfficientNet-B3 to solve Optical Chemical Structure Recognition. By leveraging the robust SELFIES representation and scaling training to over 35 million molecules, it achieves state-of-the-art accuracy on synthetic benchmarks, offering an open-source solution for mining chemical data from legacy literature.
End-to-End Transformer for Molecular Image Captioning
This paper introduces a convolution-free, end-to-end transformer model for molecular image translation. By replacing CNN encoders with Vision Transformers, it achieves superior performance on noisy datasets compared to ResNet-LSTM baselines.
Handwritten Chemical Structure Recognition with RCGD
Proposes a Random Conditional Guided Decoder (RCGD) and a Structure-Specific Markup Language (SSML) to handle the ambiguity and complexity of handwritten chemical structure recognition, validated on a new benchmark dataset (EDU-CHEMC) with 50,000 handwritten images.
This paper introduces ICMDT, a Transformer-based architecture for molecular translation (image-to-InChI). By enhancing the TNT block to fuse pixel, small patch, and large patch embeddings, the model achieves superior accuracy on the Bristol-Myers Squibb dataset compared to CNN-RNN and standard Transformer baselines.
This paper proposes an end-to-end deep learning architecture that translates chemical images directly into molecular graphs using a ResNet-Transformer encoder and a graph-aware decoder. It addresses the limitations of SMILES-based approaches by effectively handling non-atomic symbols (abbreviations) and varying drawing styles found in scientific literature.