Paper Information
Citation: Jurriaans, T., Szarkowska, K., Nalisnick, E., Schwörer, M., Thorne, C., & Akhondi, S. (2023). One Strike, You’re Out: Detecting Markush Structures in Low Signal-to-Noise Ratio Images. arXiv preprint arXiv:2311.14633. https://doi.org/10.48550/arXiv.2311.14633
Publication: arXiv 2023
Additional Resources:
Methodology and Classification
This is a Method paper (Classification: $\Psi_{\text{Method}}$).
It proposes a patch-based classification pipeline to solve a technical failure mode in Optical Chemical Structure Recognition (OCSR). Distinct rhetorical indicators include a baseline comparison (CNN vs. traditional ORB), ablation studies (architecture, pretraining), and a focus on evaluating the filtering efficacy against a known failure mode.
The Markush Structure Challenge
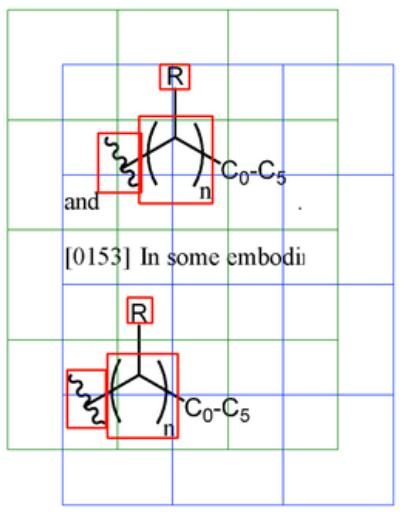
The Problem: Optical Chemical Structure Recognition (OCSR) tools convert 2D images of molecules into machine-readable formats. These tools struggle with “Markush structures,” generic structural templates used frequently in patents that contain variables rather than specific atoms (e.g., $R$, $X$, $Y$).
The Gap: Markush structures are difficult to detect because they often appear as small indicators (a single “R” or variable) within a large image, resulting in a very low Signal-to-Noise Ratio (SNR). Existing OCSR research pipelines typically bypass this by manually excluding these structures from their datasets.
The Goal: To build an automated filter that can identify images containing Markush structures so they can be removed from OCSR pipelines, improving overall database quality without requiring manual data curation.
Patch-Based Classification Pipeline
The core technical contribution is an end-to-end deep learning pipeline tailored for low-SNR chemical images where standard global resizing or cropping fails due to large variations in image resolution and pixel scales.
- Patch Generation: The system slices input images into overlapping patches generated from two offset grids, ensuring that variables falling on boundaries are fully captured in at least one crop.
- Targeted Annotation: The labels rely on pixel-level bounding boxes around Markush indicators, minimizing the noise that would otherwise overwhelm a full-image classification attempt.
- Inference Strategy: During inference, the query image is broken into patches, individually classified, and aggregated entirely using a maximum pooling rule where $X = \max_{i=1}^{n} \{ x_i \}$.
- Evaluation: Provides the first systematic comparison between fixed-feature extraction (ORB + XGBoost) and end-to-end deep learning for this specific domain.
Experimental Setup and Baselines
The authors compared two distinct paradigms on a manually annotated dataset:
Fixed-Feature Baseline: Used ORB (Oriented FAST and Rotated BRIEF) to detect keypoints and match them against a template bank of known Markush symbols. Features (match counts, Hamming distances) were fed into an XGBoost model.
Deep Learning Method: Fine-tuned ResNet18 and Inception V3 models on the generated image patches.
- Ablations: Contrasted pretraining sources, evaluating general domain (ImageNet) against chemistry-specific domain (USPTO images).
- Fine-tuning: Compared full-network fine-tuning against freezing all but the fully connected layers.
To handle significant class imbalance, the primary evaluation metric was the Macro F1 score, defined as:
$$ \text{Macro F1} = \frac{1}{N} \sum_{i=1}^{N} \frac{2 \cdot \text{precision}_i \cdot \text{recall}_i}{\text{precision}_i + \text{recall}_i} $$
Performance Outcomes
CNN vs. ORB: Deep learning architectures outperformed the fixed-feature baseline. The best model (Inception V3 pretrained on ImageNet) achieved an image-level Macro F1 of 0.928, compared to 0.701 (image-level) for the ORB baseline, and a patch-level Macro F1 of 0.917.
The Pretraining Surprise: Counterintuitively, ImageNet pretraining consistently outperformed the domain-specific USPTO pretraining. The authors hypothesize that the filters learned from ImageNet pretraining generalize well outside the ImageNet domain, though why the USPTO-pretrained filters underperform remains unclear.
Full Model Tuning: Unfreezing the entire network yielded higher performance than tuning only the classifier head, indicating that standard low-level visual filters require substantial adaptation to reliably distinguish chemical line drawings.
Limitations and Edge Cases: The best CNN achieved an ROC AUC of 0.97 on the primary patch test set, while the ORB baseline scored 0.81 on the auxiliary dataset (the paper notes these ROC curves are not directly comparable due to different evaluation sets). The aggregation metric ($X = \max \{ x_i \}$) is naive and has not been optimized. Furthermore, the patching approach creates inherent label noise when a Markush indicator is cleanly bisected by a patch edge, potentially forcing the network to learn incomplete visual features.
Reproducibility Details
Data
The study used a primary dataset labeled by domain experts and a larger auxiliary dataset for evaluation.
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Training/Val | Primary Dataset | 272 Images | Manually annotated with bounding boxes for Markush indicators. Split 60/20/20. |
| Evaluation | Auxiliary Dataset | ~5.4k Images | 5117 complete structures, 317 Markush. Used for image-level testing only (no bbox). |
Patch Generation:
- Images are cropped into patches of size 224x224 (ResNet) or 299x299 (Inception).
- Patches are generated from 2 grids offset by half the patch width/height to ensure annotations aren’t lost on edges.
- Labeling Rule: A patch is labeled “Markush” if >50% of an annotation’s pixels fall inside it.
Algorithms
ORB (Baseline):
- Matches query images against a bank of template patches containing Markush indicators.
- Features: Number of keypoints, number of matches, Hamming distance of best 5 matches.
- Classifier: XGBoost trained on these features.
- Hyperparameters: Search over number of features (500-2000) and template patches (50-250).
Training Configuration:
- Framework: PyTorch with Optuna for optimization.
- Optimization: 25 trials per configuration.
- Augmentations: Random perspective shift, posterization, sharpness/blur.
Models
Two main architectures were compared.
| Model | Input Size | Parameters | Pretraining Source |
|---|---|---|---|
| ResNet18 | 224x224 | 11.5M | ImageNet |
| Inception V3 | 299x299 | 23.8M | ImageNet & USPTO |
Best Configuration: Inception V3, ImageNet weights, Full Model fine-tuning (all layers unfrozen).
Evaluation
Primary metric was Macro F1 due to class imbalance.
| Metric | Best CNN (Inception V3) | Baseline (ORB) | Notes |
|---|---|---|---|
| Patch Test F1 | $0.917 \pm 0.014$ | N/A | ORB does not support patch-level |
| Image Test F1 | $0.928 \pm 0.035$ | $0.701 \pm 0.052$ | CNN aggregates patch predictions |
| Aux Test F1 | 0.914 | 0.533 | Evaluation on large secondary dataset |
| ROC AUC | 0.97 | 0.81 |
Hardware
- GPU: Tesla V100-SXM2-16GB
- CPU: Intel Xeon E5-2686 @ 2.30GHz
- RAM: 64 GB
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| GitHub Repository | Code | Apache-2.0 | MSc thesis code: CNN training, ORB baseline, evaluation scripts |
The primary dataset was manually annotated by Elsevier domain experts and is not publicly available. The auxiliary dataset (from Elsevier) is also not public. Pre-trained model weights are not released in the repository.
Citation
@misc{jurriaansOneStrikeYoure2023,
title = {One {{Strike}}, {{You}}'re {{Out}}: {{Detecting Markush Structures}} in {{Low Signal-to-Noise Ratio Images}}},
shorttitle = {One {{Strike}}, {{You}}'re {{Out}}},
author = {Jurriaans, Thomas and Szarkowska, Kinga and Nalisnick, Eric and Schwoerer, Markus and Thorne, Camilo and Akhondi, Saber},
year = 2023,
month = nov,
number = {arXiv:2311.14633},
eprint = {2311.14633},
primaryclass = {cs},
publisher = {arXiv},
doi = {10.48550/arXiv.2311.14633},
archiveprefix = {arXiv}
}