Paper Information
Citation: Eberhard, A., Neumann, G., & Friederich, P. (2026). Graph Recognition via Subgraph Prediction. arXiv preprint arXiv:2601.15133. https://arxiv.org/abs/2601.15133
Publication: arXiv 2026
A General Framework for Visual Graph Recognition
GraSP (Graph Recognition via Subgraph Prediction) addresses a fundamental limitation in image-to-graph methods: existing solutions are task-specific and do not transfer between domains. Whether the task is OCSR, scene graph recognition, music notation parsing, or road network extraction, each domain has developed independent solutions despite solving the same conceptual problem of extracting a graph from an image.
The key insight is that graph recognition can be reformulated as sequential subgraph prediction using a binary classifier, sidestepping two core difficulties of using graphs as neural network outputs:
- Graph isomorphism: An uncolored graph with $n$ nodes has $n!$ equivalent representations, making direct output comparison intractable
- Compositional outputs: Nodes, edges, and features are interdependent, so standard i.i.d. loss functions are insufficient
Sequential Subgraph Prediction as an MDP
GraSP formulates graph recognition as a Markov Decision Process. Starting from an empty graph, the method iteratively expands the current graph by adding one edge at a time (connecting either a new node or two existing nodes). At each step, a binary classifier predicts whether each candidate successor graph is a subgraph of the target graph shown in the image.
The critical observation is that the optimal value function $V^{\pi^*}$ satisfies:
$$V^{\pi^*}(\mathcal{G}_t | \mathcal{I}) = 1 \iff \mathcal{G}t \subseteq \mathcal{G}{\mathcal{I}}$$
This means the value function reduces to a subgraph membership test, which can be learned as a binary classifier rather than requiring reinforcement learning. Greedy decoding then suffices: at each step, select any successor that the classifier predicts is a valid subgraph, and terminate when the classifier indicates the current graph is complete.
This formulation decouples decision (what to add) from generation (in what order), making the same model applicable across different graph types without modification.
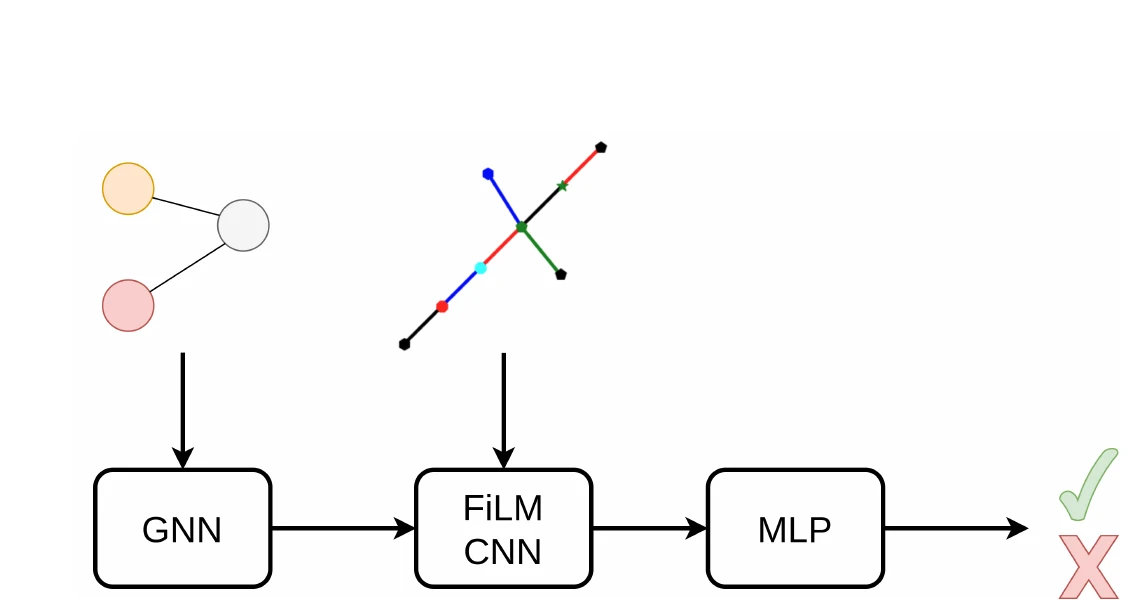
Architecture: GNN + FiLM-Conditioned CNN
The architecture has three components:
GNN encoder: A Message Passing Neural Network processes the candidate subgraph, producing a graph embedding. Messages are constructed as concatenations of source node features, target node features, and connecting edge features.
FiLM-conditioned CNN: A ResNet-v2 processes the image, with FiLM layers placed after every normalization layer within each block. The graph embedding conditions the image processing, producing a joint graph-image representation.
MLP classification head: Takes the conditioned image embedding plus a binary terminal flag (indicating whether this is a termination check) and predicts subgraph membership.
The model uses only 7.25M parameters. Group Normalization is used in the CNN (8 groups per layer), Layer Normalization in the GNN and MLP.
Training via Streaming Data Generation
Training uses a streaming architecture rather than a fixed dataset:
- For each iteration, a target graph $\mathcal{G}_T$ is sampled and rendered as an image
- Positive samples are generated by deleting edges that do not disconnect the graph (yielding valid subgraphs)
- Negative samples are generated by expanding successor states and checking via approximate subgraph matching
- Two FIFO buffers (one for positives, one for negatives), each holding up to 25,000 images, maintain diverse and balanced mini-batches of 1024 samples
- Training uses the RAdam optimizer with a cosine learning rate schedule (warmup over 50M samples, cycle of 250M samples) on 4 A100 GPUs with a 24h budget
Synthetic Benchmarks on Colored Trees
GraSP is evaluated on increasingly complex synthetic tasks involving colored tree graphs:
- Small trees (6-9 nodes): Tasks with varying numbers of node colors (1, 3, 5) and edge colors (1, 3, 5). The model works well across all configurations, with simpler tasks (fewer colors) converging faster.
- Larger trees (10-15 nodes): The same trends hold but convergence is slower due to increased structural complexity.
- Out-of-distribution generalization: Models trained on 6-9 node trees show zero-shot generalization to 10-node trees, indicating learned patterns are size-independent.
OCSR Evaluation on QM9
For the real-world OCSR evaluation, GraSP is applied to QM9 molecular images (grayscale, no stereo-bonds) with a 10,000-molecule held-out test set:
| Method | Accuracy |
|---|---|
| OSRA | 45.61% |
| GraSP | 67.51% |
| MolGrapher | 88.36% |
| DECIMER | 92.08% |
GraSP does not match state-of-the-art OCSR tools, but the authors emphasize that the same model architecture and training procedure transfers directly from synthetic tree tasks to molecular graphs with no task-specific modifications. The only domain knowledge incorporated is a simple chemistry rule: not extending nodes that already have degree four.
The method highlights the practical advantage of decoupling decision from generation. Functional groups can be represented at different granularities (as single nodes to reduce trajectory depth, or expanded to reduce trajectory breadth) without changing the model.
Reproducibility
| Artifact | Type | License | Notes |
|---|---|---|---|
| GraSP Code | Code | Unknown | Official implementation with pre-trained models |
The repository includes pre-trained models and example trajectories for interactive exploration. Training requires 4 A100 GPUs with a 24h time budget. The QM9 dataset used for OCSR evaluation is publicly available. No license file is included in the repository.
Limitations and Future Directions
- Finite type assumption: The current framework assumes a finite set of node and edge types, limiting applicability to open-vocabulary tasks like scene graph recognition
- Scaling to large graphs: For very large graphs, the branching factor of successor states becomes expensive. Learned filters to prune irrelevant successor states could help
- OCSR performance gap: While GraSP demonstrates transferability, it falls short of specialized OCSR tools that use domain-specific encodings (SMILES) or pixel-level supervision
- Modality extension: The framework could extend beyond images to other input modalities, such as vector embeddings of graphs