Contribution and Paper Type
Method. The paper proposes a novel architectural framework (ABC-Net) for Optical Chemical Structure Recognition (OCSR). It reformulates the problem from image captioning (sequence generation) to keypoint estimation (pixel-wise detection), backed by ablation studies on noise and comparative benchmarks against state-of-the-art tools.
Motivation for Keypoint-Based OCSR
- Inefficiency of Rule-Based Methods: Traditional tools (OSRA, MolVec) rely on hand-coded rules that are brittle, require domain expertise, and fail to handle the wide variance in molecular drawing styles.
- Data Inefficiency of Captioning Models: Recent Deep Learning approaches (like DECIMER, Img2mol) treat OCSR as image captioning (Image-to-SMILES). This is data-inefficient because canonical SMILES require learning traversal orders, necessitating millions of training examples.
- Goal: To create a scalable, data-efficient model that predicts graph structures directly by detecting atomic/bond primitives.
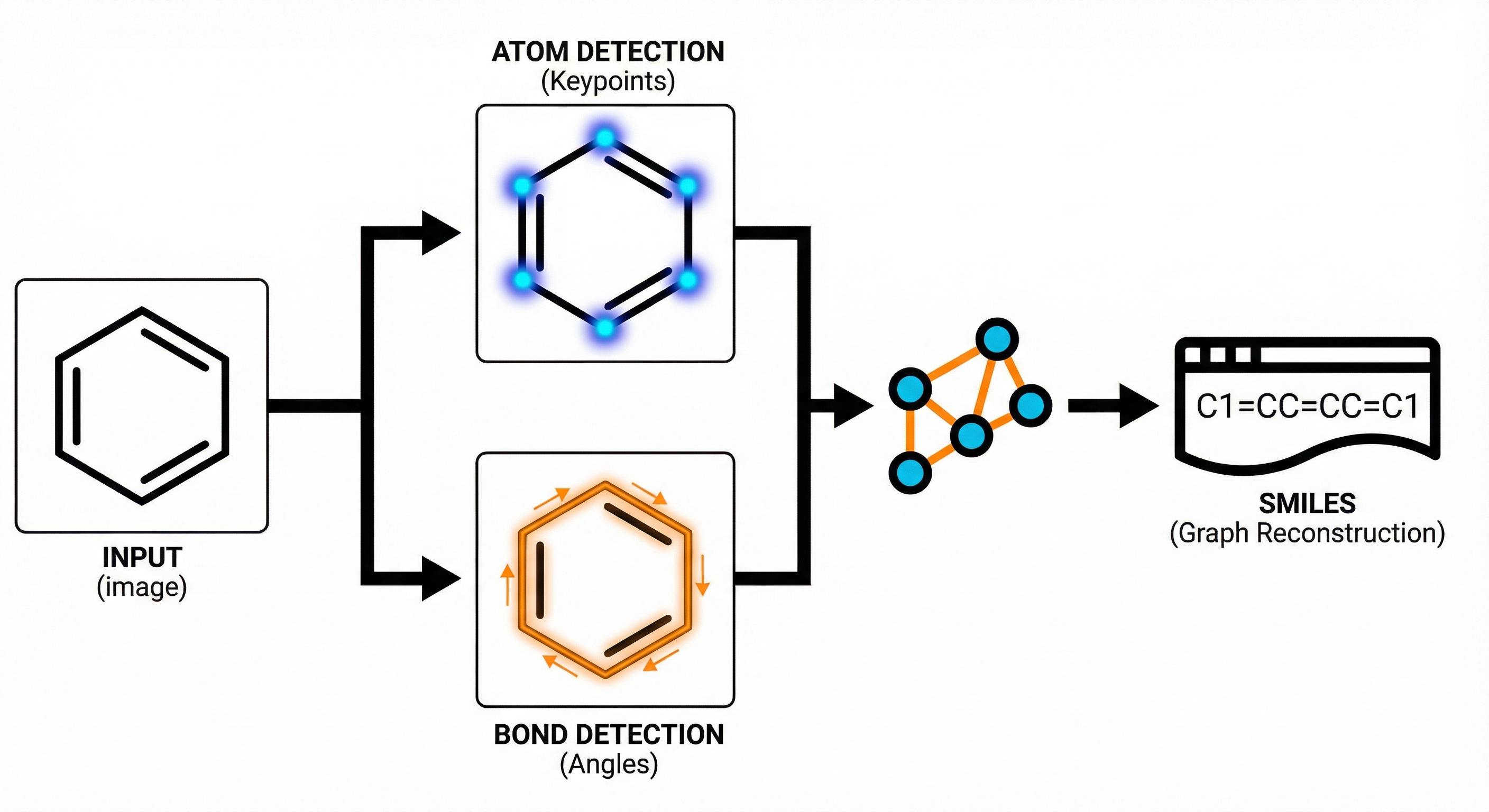
ABC-Net’s Divide-and-Conquer Architecture
- Divide-and-Conquer Strategy: ABC-Net breaks the problem down into detecting atom centers and bond centers as independent keypoints.
- Keypoint Estimation: A Fully Convolutional Network (FCN) generates heatmaps for object centers. This is inspired by computer vision techniques like CornerNet and CenterNet.
- Angle-Based Bond Detection: To handle overlapping bonds, the model classifies bond angles into 60 distinct bins ($0-360°$) at detected bond centers, allowing separation of intersecting bonds.
- Implicit Hydrogen Prediction: The model explicitly predicts the number of implicit hydrogens for heterocyclic atoms to resolve ambiguity in dearomatization.
Experimental Setup and Synthetic Data
- Dataset Construction: Synthetic dataset of 100,000 molecules from ChEMBL, rendered using two different engines (RDKit and Indigo) to ensure style diversity.
- Baselines: Compared against two rule-based methods (MolVec, OSRA) and one deep learning method (Img2mol).
- Robustness Testing: Evaluated on the external UOB dataset (real-world images) and synthetic images with varying levels of salt-and-pepper noise (up to $p=0.6$).
- Data Efficiency: Analyzed performance scaling with training set size (10k to 160k images).
Results, Generalization, and Noise Robustness
- Superior Accuracy: ABC-Net achieved 94-98% accuracy across all test sets (Table 1), outperforming MolVec (12-45% on synthetic data, ~83% on UOB), OSRA (26-62% on synthetic, ~82% on UOB), and Img2mol (78-93% on non-stereo subsets).
- Generalization: On the external UOB benchmark, ABC-Net achieved >95% accuracy, whereas the deep learning baseline (Img2mol) dropped to 78.2%, indicating better generalization.
- Data Efficiency: The model reached ~95% performance with only 80,000 training images, requiring roughly an order of magnitude less data than captioning-based models like Img2mol (which use millions of training examples).
- Noise Robustness: Performance remained stable (<2% drop) with noise levels up to $p=0.1$. Even at extreme noise ($p=0.6$), Tanimoto similarity remained high, suggesting the model recovers most substructures even when exact matches fail.
Limitations
- Drawing style coverage: The synthetic training data covers only styles available through RDKit and Indigo renderers. Many real-world styles (e.g., hand-drawn structures, atomic group abbreviations) are not represented.
- No stereo baseline from Img2mol: The Img2mol comparison only covers non-stereo subsets because stereo results were not available from the original Img2mol paper.
- Scalability to large molecules: Molecules with more than 50 non-hydrogen atoms are excluded from the dataset, and performance on such large structures is untested.
Reproducibility Details
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| ABC-Net Repository | Code | Apache-2.0 | Official implementation. Missing requirements.txt and pre-trained weights. |
Reproducibility Status: Partially Reproducible. The code is provided, but key components like the pre-trained weights, exact training environment dependencies, and the generated synthetic datasets are missing from the open-source release, making exact reproduction difficult.
Data
The authors constructed a synthetic dataset because labeled pixel-wise OCSR data is unavailable.
- Source: ChEMBL database
- Filtering: Excluded molecules with >50 non-H atoms or rare atom types/charges (<1000 occurrences).
- Sampling: 100,000 unique SMILES selected such that every atom type/charge appears in at least 1,000 compounds.
- Generation: Images generated via RDKit and Indigo libraries.
- Augmentation: Varied bond thickness, label mode, orientation, and aromaticity markers.
- Resolution: $512 \times 512$ pixels.
- Noise: Salt-and-pepper noise added during training ($P$ = prob of background flip, $Q = 50P$).
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Training | ChEMBL (RDKit/Indigo) | 80k | 8:1:1 split (Train/Val/Test) |
| Evaluation | UOB Dataset | ~5.7k images | External benchmark from Univ. of Birmingham |
Algorithms
1. Keypoint Detection (Heatmaps)
Down-sampling: Input $512 \times 512$ → Output $128 \times 128$ (stride 4).
Label Softening: To handle discretization error, ground truth peaks are set to 1, first-order neighbors to 0.95, others to 0.
Loss Function: Penalty-reduced pixel-wise binary focal loss (variants of CornerNet loss). The loss formulation is given as:
$$ L_{det} = - \frac{1}{N} \sum_{x,y} \begin{cases} (1 - \hat{A}_{x,y})^{\alpha} \log(\hat{A}_{x,y}) & \text{if } A_{x,y} = 1 \\ (1 - A_{x,y}) (\hat{A}_{x,y})^{\alpha} \log(1 - \hat{A}_{x,y}) & \text{otherwise} \end{cases} $$
- $\alpha=2$ (focal parameter). The $(1 - A_{x,y})$ term reduces the penalty for first-order neighbors of ground truth locations.
- Property classification losses use a separate focal parameter $\beta=2$ with weight balancing: classes with <10% frequency are weighted 10x.
2. Bond Direction Classification
- Angle Binning: $360°$ divided into 60 intervals.
- Inference: A bond is detected if the angle probability is a local maximum and exceeds a threshold.
- Non-Maximum Suppression (NMS): Required for opposite angles (e.g., $30°$ and $210°$) representing the same non-stereo bond.
3. Multi-Task Weighting
- Uses Kendall’s uncertainty weighting to balance 8 different loss terms (atom det, bond det, atom type, charge, H-count, bond angle, bond type, bond length).
Models
Architecture: ABC-Net (Custom U-Net / FCN)
- Input: $512 \times 512 \times 1$ (Grayscale).
- Contracting Path: 5 steps. Each step has conv-blocks + $2 \times 2$ MaxPool.
- Expansive Path: 3 steps. Transpose-Conv upsampling + Concatenation (Skip Connections).
- Heads: Separate $1 \times 1$ convs for each task map (Atom Heatmap, Bond Heatmap, Property Maps).
- Output Dimensions:
- Heatmaps: $(1, 128, 128)$
- Bond Angles: $(60, 128, 128)$
- Pre-trained Weights: Not included in the public GitHub repository. The paper’s availability statement mentions code and training datasets but not weights.
Evaluation
Metrics:
- Detection: Precision & Recall (Object detection level).
- Regression: Mean Absolute Error (MAE) for bond lengths.
- Structure Recovery:
- Accuracy: Exact SMILES match rate.
- Tanimoto: ECFP similarity (fingerprint overlap).
| Metric | ABC-Net | Img2mol (Baseline) | Notes |
|---|---|---|---|
| Accuracy (UOB) | 96.1% | 78.2% | Non-stereo subset |
| Accuracy (Indigo) | 96.4% | 89.5% | Non-stereo subset |
| Tanimoto (UOB) | 0.989 | 0.953 | Higher substructure recovery |
Hardware
- Training Configuration: 15 epochs, Batch size 64.
- Optimization: Adam Optimizer. LR $2.5 \times 10^{-4}$ (first 5 epochs) → $2.5 \times 10^{-5}$ (last 10).
- Repetition: Every experiment was repeated 3 times with random dataset splitting; mean values are reported.
- Compute: High-Performance Computing Center of Central South University. Specific GPU model not listed.
Paper Information
Citation: Zhang, X.-C., Yi, J.-C., Yang, G.-P., Wu, C.-K., Hou, T.-J., & Cao, D.-S. (2022). ABC-Net: A divide-and-conquer based deep learning architecture for SMILES recognition from molecular images. Briefings in Bioinformatics, 23(2), bbac033. https://doi.org/10.1093/bib/bbac033
Publication: Briefings in Bioinformatics 2022
Additional Resources:
Citation
@article{zhangABCNetDivideandconquerBased2022,
title = {ABC-Net: A Divide-and-Conquer Based Deep Learning Architecture for {SMILES} Recognition from Molecular Images},
author = {Zhang, Xiao-Chen and Yi, Jia-Cai and Yang, Guo-Ping and Wu, Cheng-Kun and Hou, Ting-Jun and Cao, Dong-Sheng},
journal = {Briefings in Bioinformatics},
volume = {23},
number = {2},
pages = {bbac033},
year = {2022},
publisher = {Oxford University Press},
doi = {10.1093/bib/bbac033}
}