Paper Information
Citation: Wang, R., Ji, Y., Li, Y., & Lee, S.-T. (2025). Dual-Path Global Awareness Transformer for Optical Chemical Structure Recognition. The Journal of Physical Chemistry Letters, 16(50), 12787-12795. https://doi.org/10.1021/acs.jpclett.5c03057
Publication: The Journal of Physical Chemistry Letters 2025
Additional Resources:
Contribution Type: Deep Learning Method for OCSR
This is a Method paper ($\Psi_{\text{Method}}$).
The classification is based on the proposal of a novel deep learning architecture (DGAT) designed to address specific limitations in existing Optical Chemical Structure Recognition (OCSR) systems. The contribution is validated through rigorous benchmarking against external baselines (DeepOCSR, DECIMER, SwinOCSR) and ablation studies that isolate the impact of the new modules.
Motivation: Addressing Global Context Loss
Existing multimodal fusion methods for OCSR suffer from limited awareness of global context.
- Problem: Models often generate erroneous sequences when processing complex motifs, such as rings or long chains, due to a disconnect between local feature extraction and global structural understanding.
- Gap: Current architectures struggle to capture the “fine-grained differences between global and local features,” leading to topological errors.
- Practical Need: Accurate translation of chemical images to machine-readable sequences (SMILES/SELFIES) is critical for materials science and AI-guided chemical research.
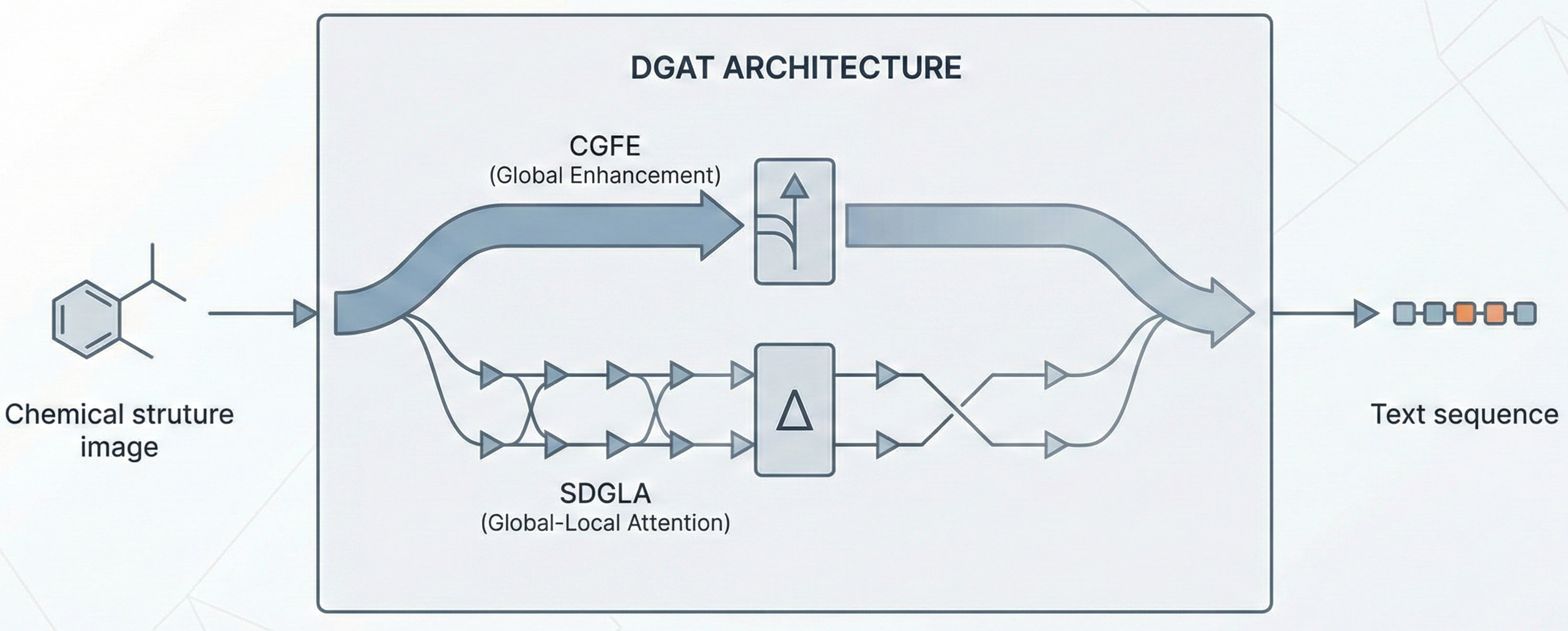
Core Innovation: Dual-Path Global Awareness Transformer
The authors propose the Dual-Path Global Awareness Transformer (DGAT), which redesigns the decoder with two novel mechanisms to better handle global context:
Cascaded Global Feature Enhancement (CGFE): This module bridges cross-modal gaps by emphasizing global context. It concatenates global visual features with sequence features and processes them through a Cross-Modal Assimilation MLP and an Adaptive Alignment MLP to align multimodal representations. The feature enhancement conceptually computes:
$$ f_{\text{enhanced}} = \text{MLP}{\text{align}}(\text{MLP}{\text{assimilate}}([f_{\text{global}}, f_{\text{seq}}])) $$
Sparse Differential Global-Local Attention (SDGLA): A module that dynamically captures fine-grained differences between global and local features. It uses sequence features (embedded with global info) as queries, while utilizing local and global visual features as keys/values in parallel attention heads to generate initial multimodal features.
Experimental Setup and Baselines
The model was evaluated on a newly constructed dataset and compared against five major baselines.
- Baselines: DeepOCSR, DECIMER 1.0, DECIMER V2, SwinOCSR, and MPOCSR.
- Ablation Studies:
- Layer Depth: Tested Transformer depths from 1 to 5 layers; 3 layers proved optimal for balancing gradient flow and parameter sufficiency.
- Beam Size: Tested inference beam sizes 1-5; size 3 achieved the best balance between search depth and redundancy.
- Module Contribution: Validated that removing CGFE results in a drop in structural similarity (Tanimoto), proving the need for pre-fusion alignment.
- Robustness Analysis: Performance broken down by molecule complexity (atom count, ring count, bond count).
- Chirality Validation: Qualitative analysis of attention maps on chiral molecules to verify the model learns stereochemical cues implicitly.
Results and Conclusions
- Performance Over Baselines: DGAT outperformed the MPOCSR baseline across all metrics:
- BLEU-4: 84.0% (+5.3% improvement)
- ROUGE: 90.8% (+1.9% improvement)
- Tanimoto Similarity: 98.8% (+1.2% improvement)
- Exact Match Accuracy: 54.6% (+10.9% over SwinOCSR)
- Chiral Recognition: The model explicitly recognizes chiral centers (e.g., generating
[C@@H1]tokens correctly) based on 2D wedge cues without direct stereochemical supervision. - Limitations: Performance drops for extreme cases, such as molecules with 4+ rings or 4+ double/triple bonds, due to dataset imbalance. The model still hallucinate branches in highly complex topologies.
Reproducibility Details
Data
The training data is primarily drawn from PubChem and augmented to improve robustness.
- Augmentation Strategy: Each sequence generates three images with random rendering parameters.
- Rotation: 0, 90, 180, 270, or random [0, 360)
- Bond Width: 1, 2, or 3 pixels
- Bond Offset: Sampled from 0.08-0.18 (inherited from Image2SMILES)
- CoordGen: Enabled with 20% probability
- Evaluation Set: A newly constructed benchmark dataset was used for final reporting.
Algorithms
- Training Configuration:
- Encoder LR: $5 \x10^{-5}$ (Pretrained ResNet-101)
- Decoder LR: $1 \x10^{-4}$ (Randomly initialized Transformer)
- Optimizer: Implied SGD/Adam (context mentions Momentum 0.9, Weight Decay 0.0001)
- Batch Size: 256
- Inference:
- Beam Search: A beam size of 3 is used. Larger beam sizes (4-5) degraded BLEU/ROUGE scores due to increased redundancy.
Models
- Visual Encoder:
- Backbone: ResNet-101 initialized with ImageNet weights
- Structure: Convolutional layers preserved up to the final module. Classification head removed.
- Pooling: A $7 \x7$ average pooling layer is used to extract global visual features.
- Sequence Decoder:
- Architecture: Transformer-based with CGFE and SDGLA modules.
- Depth: 3 Transformer layers
- Dropout: Not utilized
Evaluation
Performance is reported using sequence-level and structure-level metrics.
| Metric | DGAT Score | Baseline (MPOCSR) | Notes |
|---|---|---|---|
| BLEU-4 | 84.0% | 78.7% | Measures n-gram precision |
| ROUGE | 90.8% | 88.9% | Sequence recall metric |
| Tanimoto | 98.8% | 97.6% | Structural similarity fingerprint |
| Accuracy | 54.6% | 35.7% | Exact structure match rate |
Citation
@article{wang2025dgat,
title={Dual-Path Global Awareness Transformer for Optical Chemical Structure Recognition},
author={Wang, Rui and Ji, Yujin and Li, Youyong and Lee, Shuit-Tong},
journal={The Journal of Physical Chemistry Letters},
volume={16},
number={50},
pages={12787--12795},
year={2025},
doi={10.1021/acs.jpclett.5c03057}
}