Paper Information
Citation: Ibison, P., Jacquot, M., Kam, F., Neville, A. G., Simpson, R. W., Tonnelier, C., Venczel, T., & Johnson, A. P. (1993). Chemical Literature Data Extraction: The CLiDE Project. Journal of Chemical Information and Computer Sciences, 33(3), 338-344. https://doi.org/10.1021/ci00013a010
Publication: J. Chem. Inf. Comput. Sci. 1993
Contribution and Taxonomy
Classification: Method ($\Psi_{\text{Method}}$)
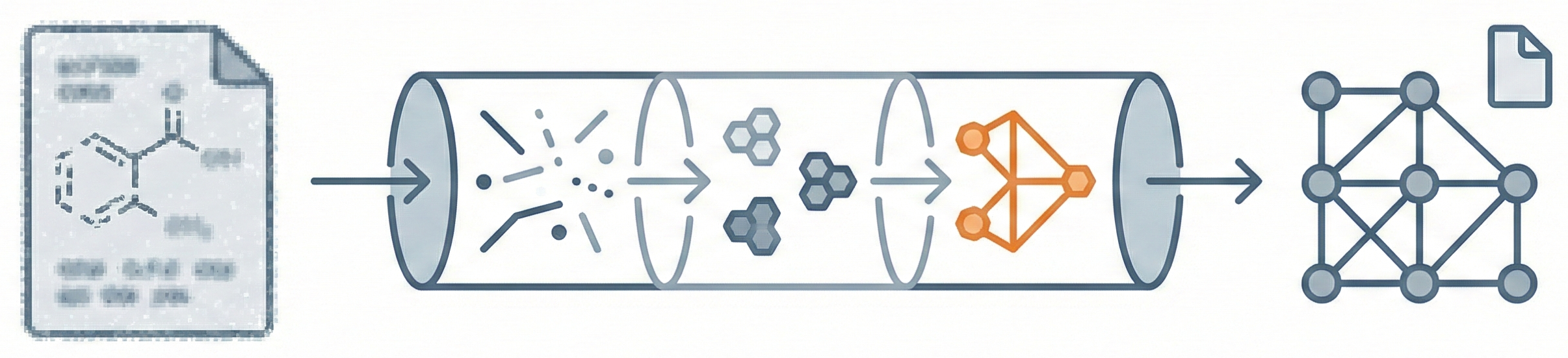
This methodological paper proposes a novel software architecture for Optical Chemical Structure Recognition (OCSR). It details specific algorithms for image segmentation, vectorization, and chemical interpretation, validated through the successful extraction of complex structures from literature.
Motivation: Automating Literature Extraction
The manual creation of chemical reaction databases is a time-consuming and expensive process requiring trained chemists to abstract information from literature. While commercial tools existed for interpreting isolated scanned structures (like Kekulé), there was a lack of systems capable of processing whole pages of journals (including embedded text, reaction schemes, and structures) without significant human intervention.
Core Innovation: A Three-Phase Hybrid Architecture
CLiDE introduces a comprehensive three-phase architecture (Recognition, Grouping, Interpretation) that integrates computer vision with chemical knowledge. Key novelties include:
- Context-Aware Interpretation: The use of an extendable superatom database to resolve ambiguities in chemical text (e.g., expanding “OAc” or “Me” into connection tables).
- Hybrid Primitive Detection: A combination of contour coding for solid lines and a modified Hough transform specifically tuned for detecting dashed chemical bonds.
- Semantic Re-construction: A scoring system for bond-atom association that considers both distance and vector direction to handle poorly drawn structures.
Methodology and Experimental Validation
The authors validated the system on a set of “difficult cases” selected to test specific capabilities. These included:
- Crossing Bonds: Structures where bonds intersect without a central atom (Fig. 9d, 9e).
- Stereochemistry: Identification of wedged, dashed, and wavy bonds.
- Generic Structures: Parsing generic text blocks (e.g., $R^1 = Me$) and performing substitutions.
- Accuracy Estimation: The authors report an approximate 90% recognition rate for distinct characters in literature scans.
Results and Structural Reconstruction
The system successfully generates connection tables (exported as MOLfiles or ChemDraw files) from scanned bitmaps. It effectively distinguishes between graphical primitives (wedges, lines) and text, accurately reconstructing stereochemistry and resolving superatom synonyms (e.g., converting “MeO” to “OMe”). The authors conclude that while character recognition depends heavily on image quality, the graphic primitive recognition is robust for lines above a threshold length.
Reproducibility Details
Data
- Input Format: Binary bitmaps scanned from journal pages.
- Resolution: 300 dpi (generating ~1 MB per page).
- Superatom Database: A lookup table containing ~200 entries. Each entry includes:
- Valency/Charge: Explicit constraints (e.g., “HO” takes 1 bond, “CO2” takes 2).
- Bonding Index: Specifies which letter in the string serves as the attachment point (e.g., letter 2 for “HO”, letters 1 and 2 for “CO2”).
- Sub-Connection Table: The internal atomic representation of the group.
Algorithms
1. Primitive Recognition (Vectorization)
- Contour Coding: Uses the Ahronovitz-Bertier-Habib method to generate interpixel contours (directions N, S, E, W) for connected components.
- Polygonal Approximation: A method similar to Sklansky and Gonzalez breaks contours into “fractions”.
- Rule: Long sides are “straight fractions”; consecutive short sides are “curved fractions”.
- Reconstruction: Parallel fractions are paired to form bond borders. If a border is split (due to noise or crossing lines), the system attempts to merge collinear segments.
- Dash Detection: A modified Hough transform is applied to small connected components. It requires at least three collinear dashes to classify a sequence as a dashed bond.
2. Interpretation Rules
- Bond-Atom Association:
- Candidate Selection: The system identifies $m$ closest bonds for a superatom requiring $n$ connections ($m \ge n$).
- Scoring Function: Connections are selected based on minimizing perpendicular distance (alignment).
- Crossing Bonds: Resolved using rules based on proximity, length, collinearity, and ring membership to distinguish actual crossings from central carbon atoms.
Models
- OCR: A neural network trained on alphanumeric characters.
- Input Representation: Density matrices derived from character bitmaps.
- Post-processing: Unrecognized characters are flagged for manual correction.
Hardware
- Platform: SUN SPARC workstation.
- Scanner: Agfa Focus S 800GS.
- Implementation Language: C++.
Citation
@article{ibisonChemicalLiteratureData1993,
title = {Chemical Literature Data Extraction: {{The CLiDE Project}}},
shorttitle = {Chemical Literature Data Extraction},
author = {Ibison, P. and Jacquot, M. and Kam, F. and Neville, A. G. and Simpson, R. W. and Tonnelier, C. and Venczel, T. and Johnson, A. P.},
year = 1993,
month = may,
journal = {Journal of Chemical Information and Computer Sciences},
volume = {33},
number = {3},
pages = {338--344},
issn = {0095-2338, 1520-5142},
doi = {10.1021/ci00013a010}
}