Paper Information
Citation: Ouyang, H., Liu, W., Tao, J., et al. (2024). ChemReco: automated recognition of hand-drawn carbon-hydrogen-oxygen structures using deep learning. Scientific Reports, 14, 17126. https://doi.org/10.1038/s41598-024-67496-7
Publication: Scientific Reports 2024
Additional Resources:
Research Contribution & Classification
This is a Methodological Paper ($\Psi_{\text{Method}}$) with a significant Resource ($\Psi_{\text{Resource}}$) component.
- Method: The primary contribution is “ChemReco,” a specific deep learning pipeline (EfficientNet + Transformer) designed to solve the Optical Chemical Structure Recognition (OCSR) task for hand-drawn images. The authors conduct extensive ablation studies on architecture and data mixing ratios to validate performance.
- Resource: The authors explicitly state that “the primary focus of this paper is constructing datasets” due to the scarcity of hand-drawn molecular data. They introduce a comprehensive synthetic data generation pipeline involving RDKit modifications and image degradation to create training data.
Motivation: Digitizing Hand-Drawn Chemical Sketches
Hand-drawing is the most intuitive method for chemists and students to record molecular structures. However, digitizing these drawings into machine-readable formats (like SMILES) usually requires time-consuming manual entry or specialized software.
- Gap: Existing OCSR tools and rule-based methods often fail on hand-drawn sketches due to diverse writing styles, poor image quality, and the absence of labeled data.
- Application: Automated recognition enables efficient chemical research and allows for automatic grading in educational settings.
Core Innovation: Synthetic Pipeline and Hybrid Architecture
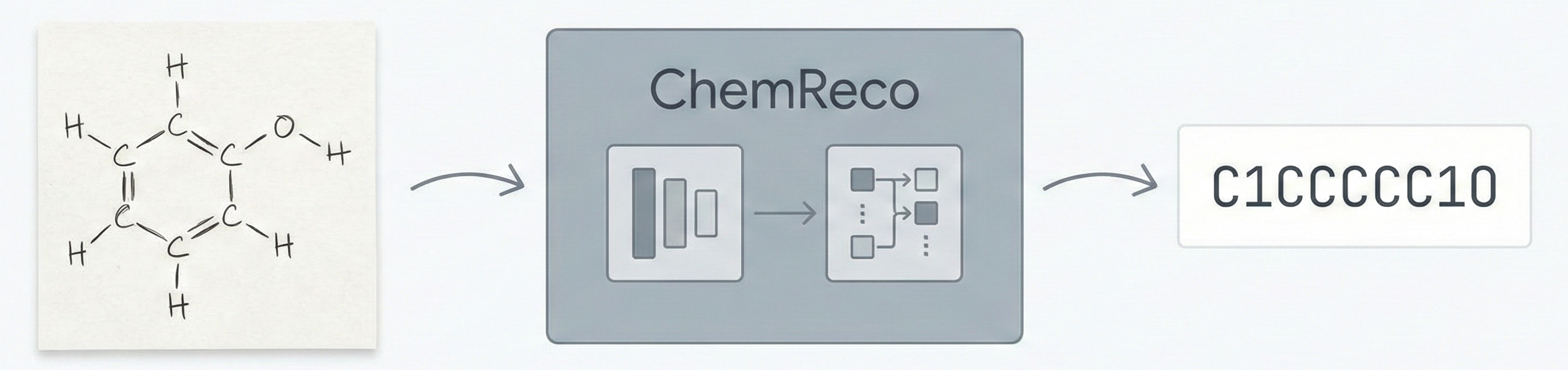
The paper introduces ChemReco, an end-to-end system for recognizing C-H-O structures. Key novelties include:
- Synthetic Data Pipeline: A multi-stage generation method that modifies RDKit source code to randomize bond/angle parameters, followed by OpenCV-based augmentation, degradation, and background addition to simulate realistic hand-drawn artifacts.
- Architectural Choice: The specific application of EfficientNet (encoder) combined with a Transformer (decoder) for this domain, which the authors demonstrate outperforms the more common ResNet+LSTM baselines.
- Hybrid Training Strategy: Finding that a mix of 90% synthetic and 10% real data yields optimal performance, superior to using either dataset alone.
Methodology & Ablation Studies
The authors performed a series of ablation studies and comparisons:
- Synthesis Ablation: Evaluated the impact of each step in the generation pipeline (RDKit only $\rightarrow$ Augmentation $\rightarrow$ Degradation $\rightarrow$ Background) on validation loss and accuracy.
- Dataset Size Ablation: Tested model performance when trained on synthetic datasets ranging from 100,000 to 1,000,000 images.
- Real/Synthetic Ratio: Investigated the optimal mixing ratio of real hand-drawn images to synthetic images (0:100, 10:90, 50:50, 90:10, 100:0).
- Architecture Comparison: Benchmarked four encoder-decoder combinations: ResNet vs. EfficientNet encoders paired with LSTM vs. Transformer decoders.
- Baseline Comparison: Compared results against a related study utilizing a CNN+LSTM framework.
Results & Interpretations
- Best Performance: The EfficientNet + Transformer model trained on a 90:10 synthetic-to-real ratio achieved a 96.90% Exact Match rate on the test set.
- Background Robustness: Adding random backgrounds during training significantly improved accuracy on complex test images (approx. 53% accuracy on background datasets vs 46% without degradation training), preventing the model from overfitting to clean white backgrounds.
- Data Volume: Increasing the synthetic dataset size from 100k to 1M consistently improved accuracy.
- Superiority over Baselines: The model significantly outperformed the cited CNN+LSTM baseline (93% vs 76% on the provided test set).
Reproducibility Details
Data
The study utilizes a combination of collected SMILES data, real hand-drawn images, and generated synthetic images.
- Source Data: SMILES codes collected from PubChem, ZINC, GDB-11, and GDB-13. Filtered for C, H, O atoms and max 1 ring.
- Real Dataset: 670 selected SMILES codes drawn by multiple volunteers, totaling 2,598 images.
- Synthetic Dataset: Generated up to 1,000,000 images using the pipeline below.
- Training Mix: The optimal training set used 1 million images with a 90:10 ratio of synthetic to real images.
| Dataset Type | Source | Size | Notes |
|---|---|---|---|
| Real | Volunteer Drawings | 2,598 images | Used for mixed training and testing |
| Synthetic | Generated | 100k - 1M | Generated via RDKit + OpenCV + Stable Diffusion |
Algorithms
The Synthetic Image Generation Pipeline is critical for reproduction:
- RDKit Modification: Modify source code to introduce random keys, character width, length, and bond angles.
- Augmentation (OpenCV): Apply sequence: Resize ($p=0.5$), Blur ($p=0.4$), Erode/Dilate ($p=0.2$), Distort ($p=0.8$), Flip ($p=0.5$), Affine ($p=0.7$).
- Degradation: Apply sequence: Salt+pepper noise ($p=0.1$), Contrast ($p=0.7$), Sharpness ($p=0.5$), Invert ($p=0.3$).
- Background Addition: Random backgrounds are augmented (Crop, Distort, Flip) and added to the molecular image to prevent background overfitting.
- Diffusion Enhancement: Stable Diffusion (v1-4) is used for image-to-image enhancement to better simulate hand-drawn styles (prompt: “A pencil sketch of [Formula]… without charge distribution”).
Models
The system uses an encoder-decoder architecture:
- Encoder: EfficientNet (pre-trained on ImageNet). The last layer is removed, and features are extracted into a Numpy array.
- Decoder: Transformer. Utilizes self-attention to generate the SMILES sequence. Chosen over LSTM for better handling of long-range dependencies.
- Output: Canonical SMILES string.
Evaluation
The standard performance metrics for sequence generation and recognition align precisely with their chosen evaluations. The model predictions $\hat{y}$ are compared against ground truth sequences $y$ of length $N$.
- Primary Metric: Exact Match (EM). A strict binary evaluation verifying if the complete generated SMILES perfectly replicates the original target string: $$ \text{EM} = \frac{1}{N} \sum_{i=1}^{N} \mathbb{1}[\hat{y}_i = y_i] $$
- Other Metrics: Levenshtein Distance measures edit-level character proximity, while the Tanimoto coefficient evaluates structural similarity based on chemical fingerprints, both monitored strictly during validation ablation runs.
| Metric | Value | Baseline (CNN+LSTM) | Notes |
|---|---|---|---|
| Exact Match | 96.90% | 76% | Tested on the provided test set |
Hardware
- CPU: Intel(R) Xeon(R) Gold 6130 (40 GB RAM).
- GPU: NVIDIA Tesla V100 (32 GB video memory).
- Framework: PyTorch 1.9.1.
- Training Configuration:
- Optimizer: Adam (learning rate 1e-4).
- Batch size: 32.
- Epochs: 100.
Citation
@article{ouyangChemRecoAutomatedRecognition2024,
title = {ChemReco: Automated Recognition of Hand-Drawn Carbon--Hydrogen--Oxygen Structures Using Deep Learning},
author = {Ouyang, Hengjie and Liu, Wei and Tao, Jiajun and Luo, Yanghong and Zhang, Wanjia and Zhou, Jiayu and Geng, Shuqi and Zhang, Chengpeng},
journal = {Scientific Reports},
volume = {14},
number = {1},
pages = {17126},
year = {2024},
publisher = {Nature Publishing Group},
doi = {10.1038/s41598-024-67496-7}
}