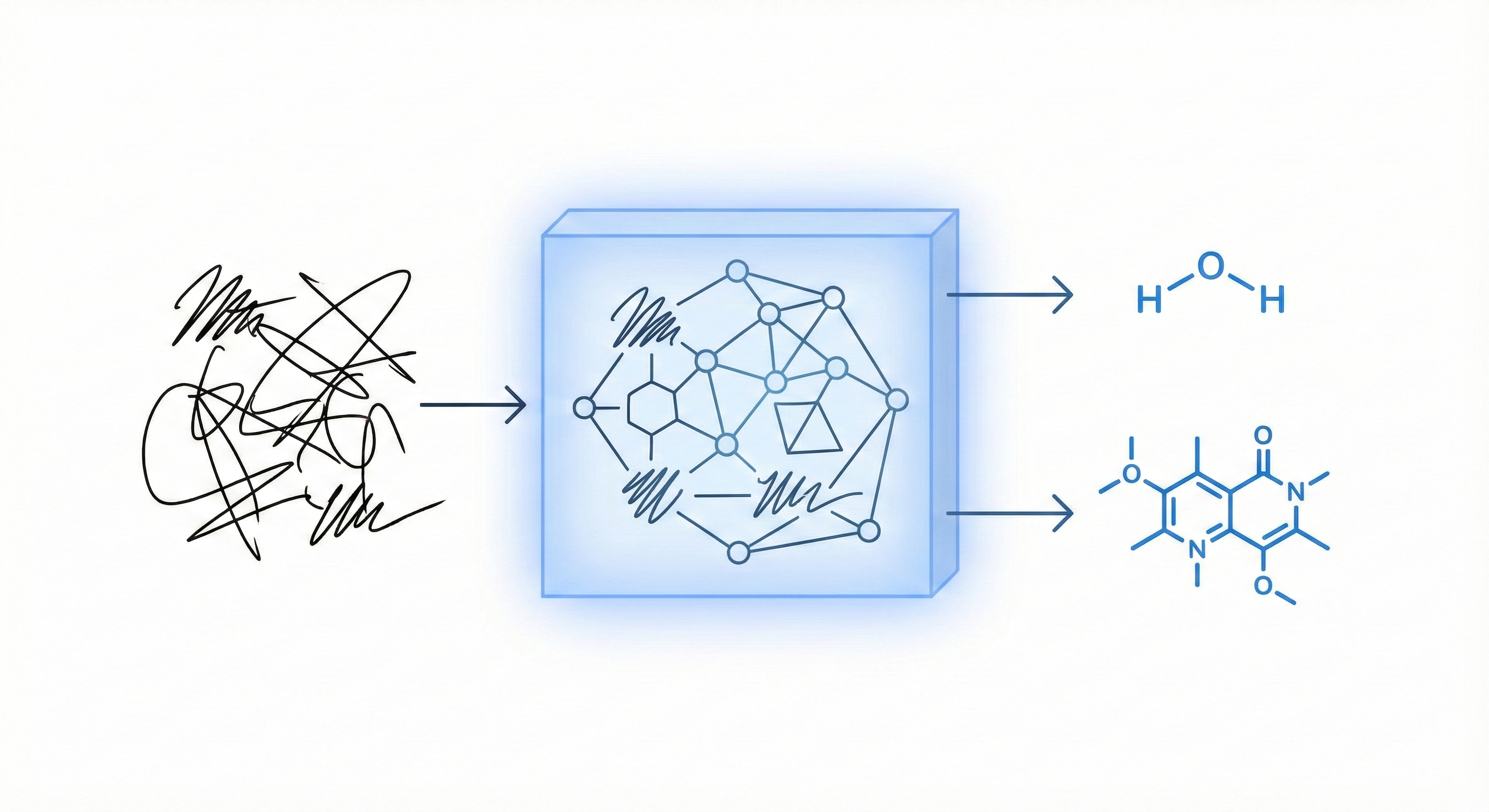
Addressing the Complexity of Handwritten Organic Chemistry
This is a Methodological Paper ($\Psi_{\text{Method}}$) from Microsoft Research Asia that addresses the challenge of recognizing complex 2D organic chemistry structures. By 2009, math expression recognition had seen significant commercial progress, but chemical expression recognition remained less developed.
The specific gap addressed is the geometric complexity of organic formulas. While inorganic formulas typically follow a linear, equation-like structure, organic formulas present complex 2D diagrammatic structures with various bond types and rings. Existing work often relied on strong assumptions (like single-stroke symbols) or failed to handle arbitrary compounds. There was a clear need for a unified solution capable of handling both inorganic and organic domains consistently.
The Chemical Expression Structure Graph (CESG)
The core innovation is a unified statistical framework that processes inorganic and organic expressions within the same pipeline. Key technical novelties include:
- Unified Bond Modeling: Bonds are treated as special symbols. The framework detects “extended bond symbols” (multi-stroke bonds) and splits them into single, double, or triple bonds using corner detection for consistent processing.
- Chemical Expression Structure Graph (CESG): A defined graph representation for generic chemical expressions where nodes represent symbols and edges represent bonds or spatial relations.
- Non-Symbol Modeling: During the symbol grouping phase, the system explicitly models “invalid groups” to reduce over-grouping errors.
- Global Graph Search: Structure analysis is formulated as finding the optimal CESG by searching over a Weighted Direction Graph ($G_{WD}$).
Graph Search and Statistical Validation
The authors validated the framework on a proprietary database of 35,932 handwritten chemical expressions collected from 300 writers.
- Setup: The data was split into roughly 26,000 training and 6,400 testing samples.
- Metric: Recognition accuracy was measured strictly by expression (all symbols and the complete structure must be correct).
- Ablations: The team evaluated the performance contribution of symbol grouping, structure analysis, and full semantic verification.
Recognition Accuracy and Outcomes
The full framework achieved a Top-1 accuracy of 75.4% and a Top-5 accuracy of 83.1%.
- Component Contribution: Structure analysis is the primary bottleneck. Adding it drops the theoretical “perfect grouping” performance from 85.9% to 74.1% (Top-1) due to structural errors.
- Semantic Verification: Checking valence and grammar improved relative accuracy by 1.7%.
The unified framework effectively handles the variance in 2D space for chemical expressions, demonstrating that delayed decision-making (keeping top-N candidates) improves robustness.
Reproducibility Details
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| N/A | N/A | N/A | No public artifacts (code, data, models) were released by the authors. |
Data
The study used a private Microsoft Research Asia dataset, making direct reproduction difficult.
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Total | Proprietary MSRA DB | 35,932 expressions | Written by 300 people |
| Training | Subset | 25,934 expressions | |
| Testing | Subset | 6,398 expressions |
- Content: 2,000 unique expressions from high school/college textbooks.
- Composition: ~25% of samples are organic expressions.
- Vocabulary: 163 symbol classes (elements, digits,
+,↑,%, bonds, etc.).
Algorithms
1. Symbol Grouping (Dynamic Programming)
- Objective: Find the optimal symbol sequence $G_{max}$ maximizing the posterior probability given the ink strokes: $$ G_{max} = \arg\max_{G} P(G | \text{Ink}) $$
- Non-symbol modeling: Iteratively trained models on “incorrect grouping results” to learn to reject invalid strokes.
- Inter-group modeling: Uses Gaussian Mixture Models (GMM) to model spatial relations ($R_j$) between groups.
2. Bond Processing
- Extended Bond Symbol: Recognizes connected strokes (e.g., a messy double bond written in one stroke) as a single “extended” symbol.
- Splitting: Uses Curvature Scale Space (CSS) corner detection to split extended symbols into primitive lines.
- Classification: A Neural Network verifies if the split lines form valid single, double, or triple bonds.
3. Structure Analysis (Graph Search)
- Graph Construction: Builds a Weighted Direction Graph ($G_{WD}$) where nodes are symbol candidates and edges are potential relationships ($E_{c}, E_{nc}, E_{peer}, E_{sub}$).
- Edge Weights: Calculated as the product of observation, spatial, and contextual probabilities:
$$ W(S, O, R) = P(O|S) \times P(\text{Spatial}|R) \times P(\text{Context}|S, R) $$
- Spatial probability uses rectangular control regions and distance functions.
- Contextual probability uses statistical co-occurrence (e.g., ‘C’ often appears with ‘H’).
- Search: Breadth-first search with pruning to find the top-N optimal CESGs.
Models
- Symbol Recognition: Implementation details not specified, but likely HMM or NN based on the era. Bond verification explicitly uses a Neural Network.
- Spatial Models: Gaussian Mixture Models (GMM) are used to model the 9 spatial relations (e.g., Left-super, Above, Subscript).
- Semantic Model: A Context-Free Grammar (CFG) parser is used for final verification (e.g., ensuring digits aren’t reactants).
Evaluation
Evaluation is performed using “Expression-level accuracy”.
| Metric | Value (Top-1) | Value (Top-5) | Notes |
|---|---|---|---|
| Full Framework | 75.4% | 83.1% | |
| Without Semantics | 74.1% | 83.0% | |
| Grouping Only | 85.9% | 95.6% | Theoretical max if structure analysis was perfect |
Paper Information
Citation: Chang, M., Han, S., & Zhang, D. (2009). A Unified Framework for Recognizing Handwritten Chemical Expressions. 2009 10th International Conference on Document Analysis and Recognition, 1345–1349. https://doi.org/10.1109/ICDAR.2009.64
Publication: ICDAR 2009
@inproceedings{changUnifiedFrameworkRecognizing2009,
title = {A {{Unified Framework}} for {{Recognizing Handwritten Chemical Expressions}}},
booktitle = {2009 10th {{International Conference}} on {{Document Analysis}} and {{Recognition}}},
author = {Chang, Ming and Han, Shi and Zhang, Dongmei},
year = 2009,
pages = {1345--1349},
publisher = {IEEE},
address = {Barcelona, Spain},
doi = {10.1109/ICDAR.2009.64}
}