Contribution: A 100% Robust Representation for ML
This is a Method paper that introduces a new molecular string representation designed specifically for machine learning applications.
Motivation: The Invalidity Bottleneck
When neural networks generate molecules using SMILES notation, a huge fraction of output strings are invalid: either syntax errors or chemically impossible structures. This was a fundamental bottleneck: if your generative model produces a large fraction of invalid molecules, you are wasting computational effort and severely limiting chemical space exploration.
Novelty: A Formal Grammar Approach
The authors’ key insight was using a formal grammar approach (specifically, a Chomsky type-2, context-free grammar with self-referencing functions) where each symbol is interpreted based on chemical context. The “state of the derivation” tracks available valence bonds, preventing impossible structures like a carbon with five single bonds.
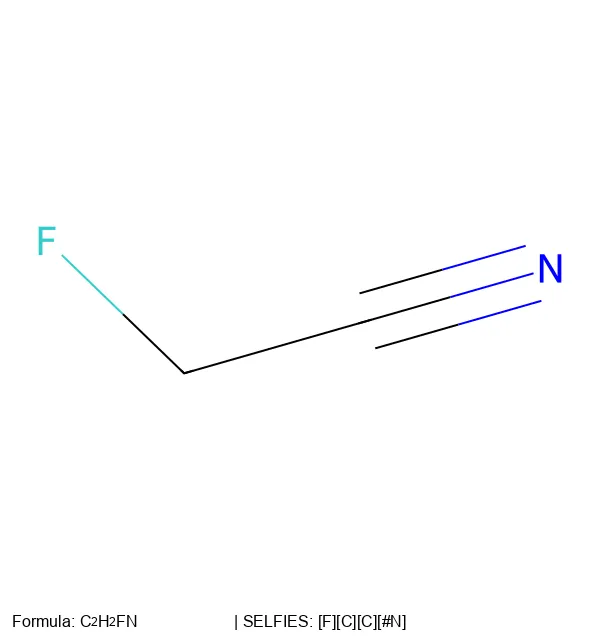
For example, generating 2-Fluoroethenimine (FC=C=N) follows a state derivation where each step restricts the available valency for the next element:
$$ \mathbf{X}_0 \xrightarrow{[F]} \text{F } \mathbf{X}_1 \xrightarrow{[=C]} \text{FC } \mathbf{X}_3 \xrightarrow{[=C]} \text{FC=C } \mathbf{X}_2 \xrightarrow{[\#N]} \text{FC=C=N} $$
This approach guarantees 100% validity: every SELFIES string corresponds to a valid molecule, and every valid molecule can be represented.
Methodology & Experiments: Validating Robustness
The authors ran several experiments to demonstrate SELFIES’ robustness:
Random Mutation Test
They took the SELFIES and SMILES representations of MDMA and introduced random changes:
- SMILES: After just one random mutation, only 9.9% of strings remained valid (dropping to 1.1% after three mutations).
- SELFIES: 100% of mutated strings still represented valid molecules (though different from the original).
This empirical difference demonstrates why SELFIES is well suited for evolutionary algorithms and genetic programming approaches to molecular design, where random mutations of strings are a core operation.
Generative Model Performance
The real test came with actual machine learning models. The authors trained Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) on both representations:
VAE Results:
- SMILES-based VAE: Large invalid regions scattered throughout the latent space
- SELFIES-based VAE: Every point in the continuous latent space mapped to a valid molecule
- The SELFIES model encoded over 100 times more diverse molecules
GAN Results:
- Best SMILES GAN: 18.6% diverse, valid molecules
- Best SELFIES GAN: 78.9% diverse, valid molecules
Evaluation Metrics:
- Validity: Percentage of generated strings representing valid molecular structures
- Diversity: Number of unique valid molecules produced
- Reconstruction Accuracy: How well the autoencoder reproduced input molecules
Scalability Test
The authors showed SELFIES works beyond toy molecules by successfully encoding and decoding all 72 million molecules from the PubChem database (with fewer than 500 SMILES characters per molecule), demonstrating practical applicability to real chemical databases.
Results & Conclusions: Chemical Space Exploration
Key Findings:
- SELFIES achieves 100% validity guarantee: every string represents a valid molecule
- SELFIES-based VAEs encode over 100x more diverse molecules than SMILES-based models
- SELFIES-based GANs produce 78.9% diverse valid molecules vs. 18.6% for SMILES GANs
- Successfully validated on all 72 million PubChem molecules
Limitations Acknowledged:
- No standardization or canonicalization method at time of publication
- The initial grammar covered only small biomolecules; extensions for stereochemistry, ions, polyvalency, and full periodic table coverage were planned
- Requires community testing and adoption
Impact:
This work demonstrated that designing ML-native molecular representations could enable new approaches in drug discovery and materials science. SELFIES was subsequently evaluated as an alternative input representation to SMILES in ChemBERTa, a transformer pretrained on molecular strings for property prediction, where it performed comparably to SMILES on the Tox21 benchmark, though the comparison was limited to a single task.
Reproducibility Details
Data
The machine learning experiments used two distinct datasets:
- QM9 (134k molecules): Primary training dataset for VAE and GAN models
- PubChem (72M molecules): Used only to test representation coverage and scalability; not used for model training
Models
The VAE implementation included:
- Latent space: 241-dimensional with Gaussian distributions
- Input encoding: One-hot encoding of SELFIES/SMILES strings
- Full architectural details (encoder/decoder structures, layer types) provided in Supplementary Information
Algorithms
The authors found GAN performance was highly sensitive to hyperparameter selection:
- Searched 200 different hyperparameter configurations to achieve the reported 78.9% diversity
- Specific optimizers, learning rates, and training duration detailed in Supplementary Information
- Full rule generation algorithm provided in Table 2
Evaluation
All models evaluated on:
- Validity rate: Percentage of syntactically and chemically valid outputs
- Diversity: Count of unique valid molecules generated
- Reconstruction accuracy: Fidelity of autoencoder reconstruction (VAEs only)
Hardware
- Training performed on the SciNet supercomputing infrastructure.
- The paper does not specify GPU types or training times.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| SELFIES GitHub Repository | Code | Apache-2.0 | Official implementation; has evolved significantly since the original paper |
Replication Resources
Complete technical replication is highly accessible due to the paper being published open-access in Machine Learning: Science and Technology. It primarily requires:
- The full rule generation algorithm (Table 2 in paper)
- Code: https://github.com/aspuru-guzik-group/selfies
- Supplementary Information for complete architectural and hyperparameter specifications
Note: The modern SELFIES library has evolved significantly since this foundational paper, addressing many of the implementation challenges identified by the authors.
Paper Information
Citation: Krenn, M., Häse, F., Nigam, A., Friederich, P., & Aspuru-Guzik, A. (2020). Self-referencing embedded strings (SELFIES): A 100% robust molecular string representation. Machine Learning: Science and Technology, 1(4), 045024. https://doi.org/10.1088/2632-2153/aba947
Publication: Machine Learning: Science and Technology, 2020
@article{Krenn_2020,
doi = {10.1088/2632-2153/aba947},
url = {https://doi.org/10.1088%2F2632-2153%2Faba947},
year = 2020,
month = {aug},
publisher = {{IOP} Publishing},
volume = {1},
number = {4},
pages = {045024},
author = {Mario Krenn and Florian H{\"{a}}se and AkshatKumar Nigam and Pascal Friederich and Alan Aspuru-Guzik},
title = {Self-referencing embedded strings ({SELFIES}): A 100{\%} robust molecular string representation},
journal = {Machine Learning: Science and Technology}
}
Additional Resources: