A Benchmark Resource for Chemistry-Focused LLM Evaluation
ChemBench is a Resource paper that introduces an automated benchmarking framework for evaluating the chemical knowledge and reasoning abilities of large language models against human expert chemists. The primary contribution is the benchmark corpus itself (2,788 question-answer pairs), the evaluation infrastructure, and the human baseline study that contextualizes model performance. The framework is designed to be extensible and can evaluate any system that returns text, including tool-augmented agents.
Why Chemistry Needs Its Own LLM Benchmark
Existing LLM benchmarks provide poor coverage of chemistry. BigBench contains only 2 of 204 tasks classified as chemistry-related, and the LM Eval Harness contains none. Developers of chemical language models often fall back on tabular property-prediction datasets (MoleculeNet, Therapeutic Data Commons, MatBench), which give a narrow view of chemical capabilities. Prior attempts at chemistry-specific benchmarks based on university entrance exams or automatic text mining have not gained wide acceptance because they cannot be used with black-box or tool-augmented systems, do not cover a broad range of topics and skills, or are not validated by domain experts.
At the same time, LLMs are increasingly used in chemistry: for property prediction, reaction optimization, materials generation, information extraction, and even autonomous experiment execution. Some users (students, general public) may rely on LLMs for safety-critical chemical questions without the expertise to evaluate outputs. Understanding where LLMs succeed and fail in chemistry is therefore both a scientific and a safety question.
ChemBench: Framework Design and Benchmark Corpus
ChemBench addresses these gaps with several design choices that distinguish it from prior work.
Diverse question corpus. The benchmark contains 2,788 question-answer pairs from multiple sources: 1,039 manually generated (from university exams, chemistry olympiads, textbooks, and novel questions) and 1,749 semi-automatically generated (from chemical databases covering GHS pictograms, daily allowed intakes, hazard statements, NMR peak counts, electron counts, IUPAC-SMILES conversions, oxidation states, and point groups). Questions span general, organic, inorganic, physical, analytical, and technical chemistry, among other topics.
Skill-based classification. Each question is annotated with the skills required to answer it: knowledge, reasoning, calculation, intuition, or combinations thereof. Questions are also classified by difficulty level (basic vs. advanced), enabling fine-grained analysis of model capabilities.
Both MCQ and open-ended formats. The corpus includes 2,544 multiple-choice and 244 open-ended questions, reflecting the reality that chemistry education and research involve more than multiple-choice testing.
Semantic annotation. Questions use tagged annotations for molecules ([START_SMILES]...[END_SMILES]), equations, units, and reactions. This allows models with special processing for scientific notation (e.g., Galactica) to handle these modalities appropriately, while remaining compatible with standard text-completion APIs.
Text-completion evaluation. ChemBench operates on text completions rather than raw logits, enabling evaluation of tool-augmented and agentic systems (not just bare models). Parsing uses multi-step regex followed by LLM-based extraction as a fallback.
ChemBench-Mini. A curated 236-question subset balances topic and skill diversity for fast, cost-effective routine evaluations. This subset was also used for the full human baseline study.
Evaluation Setup: Models, Human Experts, and Confidence
Models evaluated
The study evaluated a wide range of leading models, including both open-source and proprietary systems: o1-preview, GPT-4, Claude-3.5 (Sonnet), Llama-3.1-405B-Instruct, and others, as well as the agentic literature-search system PaperQA2. All models used greedy decoding (temperature 0) via API endpoints.
Human baseline
Nineteen chemistry experts participated through a custom web application (chembench.org). Volunteers included 2 post-postdoc researchers, 13 PhD students (with master’s degrees), and 1 bachelor’s holder. The analysis excluded anyone with fewer than 2 years of chemistry experience. For a subset of questions, volunteers were allowed to use external tools (web search, ChemDraw) but not LLMs or other people.
Confidence calibration
Selected top-performing models were prompted to estimate their confidence on a 1-5 ordinal scale (verbalized confidence estimates). This approach captures semantic uncertainty and works with models that do not expose logits.
Key Results: Where LLMs Outperform Chemists and Where They Fail
Overall performance
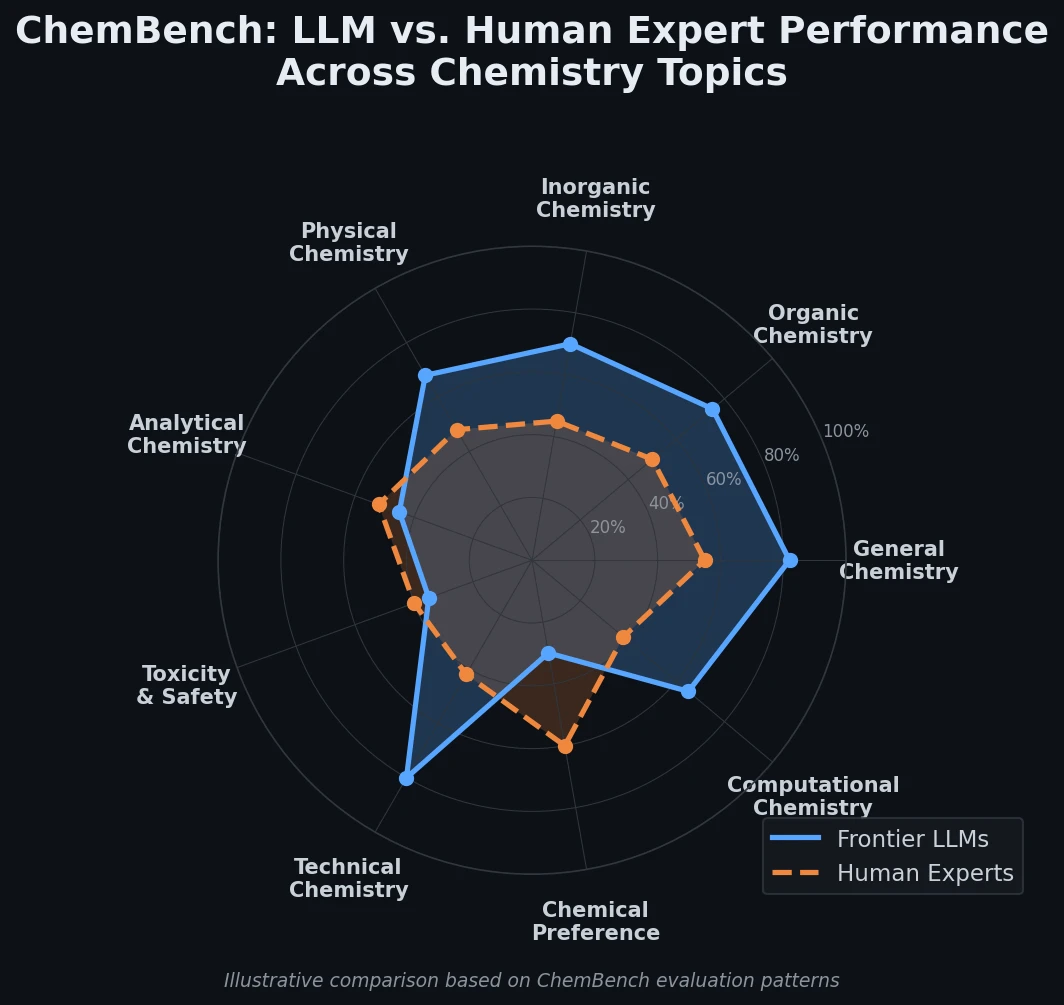
On ChemBench-Mini, the leading model (o1-preview) outperformed the best human expert by nearly a factor of two in overall accuracy. Many other models also exceeded average human performance. Llama-3.1-405B-Instruct achieved performance close to the leading proprietary models, showing that open-source models can be competitive in chemical settings.
Performance varies by topic
While models scored well on general and technical chemistry, they performed poorly on toxicity/safety and analytical chemistry. Predicting the number of NMR signals was particularly difficult (22% correct for o1-preview). This task requires reasoning about molecular symmetry from a SMILES string, which models struggle with compared to humans who can view molecular drawings.
Textbook questions vs. database-derived questions
Models performed better on textbook-inspired questions than on semi-automatically constructed tasks. For example, models could pass the German Chemical Prohibition Ordinance certification exam (71% for GPT-4, 61% for Claude-3.5 Sonnet) while human experts scored only 3% on the sampled subset. This suggests that good textbook question performance does not transfer to tasks requiring deeper reasoning or knowledge outside the training corpus.
Knowledge-intensive limitations
Models struggled with knowledge-intensive questions that required looking up facts in specialized databases (PubChem, Gestis). PaperQA2, which augments LLMs with literature search, could not compensate because the required knowledge lives in specialized databases rather than papers.
Chemical preference judgment
When asked to judge chemical preference (choosing between two molecules in an early virtual screening setting, following the Choung et al. dataset), model performance was often indistinguishable from random guessing, even for models that excelled at other ChemBench tasks. Human chemists showed reasonable inter-rater agreement on the same questions.
Confidence calibration is poor
For most models, verbalized confidence estimates did not correlate meaningfully with actual correctness. GPT-4 reported confidence of 1.0 for a correctly answered safety question but 4.0 for six incorrectly answered ones. Claude-3.5 Sonnet showed slightly better calibration on average but still produced misleading estimates in specific topic areas (e.g., GHS pictogram labeling: average confidence of 2.0 for correct answers vs. 1.83 for incorrect ones).
Scaling and molecular complexity
Model performance correlated with model size, consistent with observations in other domains. However, performance did not correlate with molecular complexity indicators, suggesting that models may rely on training data proximity rather than genuine structural reasoning.
Implications for Chemistry and LLM Development
The authors draw several conclusions from the ChemBench evaluation.
Chemistry education needs rethinking. Since LLMs already outperform average human chemists on many textbook-style questions, the value of rote memorization and problem-solving in chemistry curricula is diminishing. Critical reasoning and evaluation of model outputs become more important skills.
Breadth vs. depth matters. Model performance varies widely across topics and question types, even within a single topic. Aggregate scores can mask significant weaknesses in safety-critical areas.
Better human-model interaction is needed. Poor confidence calibration means users cannot trust models’ self-reported uncertainty. Developing better uncertainty estimation for chemical LLMs is an important direction.
Room for improvement through specialized data. Training on specialized chemical databases (rather than just papers) and integrating domain-specific tools could address the knowledge-intensive gaps identified by ChemBench.
Open science framework. ChemBench is designed for extensibility: new models can be added by contributors, and the leaderboard is publicly accessible. The use of a BigBench-compatible canary string helps prevent test set contamination in future training corpora.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Evaluation | ChemBench (full corpus) | 2,788 Q-A pairs | 1,039 manual + 1,749 semi-automatic |
| Evaluation | ChemBench-Mini | 236 questions | Curated diverse subset; used for human baseline |
| Chemical preference | Choung et al. dataset | 1,000 sampled pairs | From original 5,000+ dataset |
All benchmark data is publicly available on GitHub and archived on Zenodo.
Algorithms
Evaluation uses greedy decoding (temperature 0) for all models. Parsing is multi-step: regex extraction of answer environments and enumeration letters/numbers, word-to-number conversion, and LLM-based fallback parsing (Claude-3.5 Sonnet). Confidence estimates are verbalized on an ordinal 1-5 scale.
Models
The paper evaluates multiple models including o1-preview, GPT-4, Claude-3.5 (Sonnet), Llama-3.1-405B-Instruct, Galactica, and PaperQA2. Model weights are not released (the contribution is the benchmark, not a model).
Evaluation
| Metric | Scope | Notes |
|---|---|---|
| Accuracy (% correct) | Per question, per topic, overall | Strict: partially correct = incorrect |
| Confidence calibration | Ordinal 1-5 scale | Verbalized, not logit-based |
| Human comparison | 19 experts on ChemBench-Mini | Tools allowed for subset |
Hardware
Not applicable; the benchmark is designed for API-based evaluation. Cost context: Liang et al. report >US$10,000 for a single HELM evaluation, motivating ChemBench-Mini.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| ChemBench Code & Data | Code + Dataset | MIT | Framework and benchmark corpus |
| ChemBench Zenodo Archive | Dataset | MIT | Version v0.2.0, archived |
| ChemBench Web App | Code | MIT | Human baseline survey application |
| ChemBench Leaderboard | Other | N/A | Public model leaderboard |
Paper Information
Citation: Mirza, A., Alampara, N., Kunchapu, S., Ríos-García, M., Emoekabu, B., Krishnan, A., … & Jablonka, K. M. (2025). A framework for evaluating the chemical knowledge and reasoning abilities of large language models against the expertise of chemists. Nature Chemistry, 17(7), 1027-1034. https://doi.org/10.1038/s41557-025-01815-x
@article{mirza2025chembench,
title={A framework for evaluating the chemical knowledge and reasoning abilities of large language models against the expertise of chemists},
author={Mirza, Adrian and Alampara, Nawaf and Kunchapu, Sreekanth and R{\'\i}os-Garc{\'\i}a, Marti{\~n}o and Emoekabu, Benedict and Krishnan, Aswanth and Gupta, Tanya and Schilling-Wilhelmi, Mara and Okereke, Macjonathan and Aneesh, Anagha and Asgari, Mehrdad and Eberhardt, Juliane and Elahi, Amir Mohammad and Elbeheiry, Hani M. and Gil, Mar{\'\i}a Victoria and Glaubitz, Christina and Greiner, Maximilian and Holick, Caroline T. and Hoffmann, Tim and Ibrahim, Abdelrahman and Klepsch, Lea C. and K{\"o}ster, Yannik and Kreth, Fabian Alexander and Meyer, Jakob and Miret, Santiago and Peschel, Jan Matthias and Ringleb, Michael and Roesner, Nicole C. and Schreiber, Johanna and Schubert, Ulrich S. and Stafast, Leanne M. and Wonanke, A. D. Dinga and Pieler, Michael and Schwaller, Philippe and Jablonka, Kevin Maik},
journal={Nature Chemistry},
volume={17},
number={7},
pages={1027--1034},
year={2025},
publisher={Springer Nature},
doi={10.1038/s41557-025-01815-x}
}