Paper Information
Citation: Kim, E., Lee, D., Kwon, Y., Park, M. S., & Choi, Y.-S. (2021). Valid, Plausible, and Diverse Retrosynthesis Using Tied Two-Way Transformers with Latent Variables. Journal of Chemical Information and Modeling, 61, 123-133.
Publication: Journal of Chemical Information and Modeling, 2021
Additional Resources:
@article{kim2021valid,
title={Valid, Plausible, and Diverse Retrosynthesis Using Tied Two-Way Transformers with Latent Variables},
author={Kim, Eunji and Lee, Dongseon and Kwon, Youngchun and Park, Min Sik and Choi, Youn-Suk},
journal={Journal of Chemical Information and Modeling},
volume={61},
pages={123--133},
year={2021},
publisher={ACS Publications},
doi={10.1021/acs.jcim.0c01074}
}
Bridging Forward and Backward Reaction Prediction
This is a Method paper that addresses three key limitations of template-free retrosynthesis models: invalid SMILES outputs, chemically implausible predictions, and lack of diversity in reactant candidates. The solution combines three techniques: (1) cycle consistency checks using a paired forward reaction transformer, (2) parameter tying between the forward and backward transformers, and (3) multinomial latent variables with a learned prior to capture multiple reaction pathways.
Three Problems in Template-Free Retrosynthesis
Template-free retrosynthesis models cast retrosynthesis as a sequence-to-sequence translation problem (product SMILES to reactant SMILES). While these models avoid the cost of hand-coded reaction templates, they suffer from:
- Invalid SMILES: predicted reactant strings that contain grammatical errors and cannot be parsed into molecules
- Implausibility: predicted reactants that are valid molecules but cannot actually synthesize the target product
- Lack of diversity: beam search produces duplicate or near-duplicate candidates, reducing the number of useful suggestions
Prior work addressed these individually (SCROP adds a syntax corrector for validity, Chen et al. use latent variables for diversity), but this paper tackles all three simultaneously.
Model Architecture
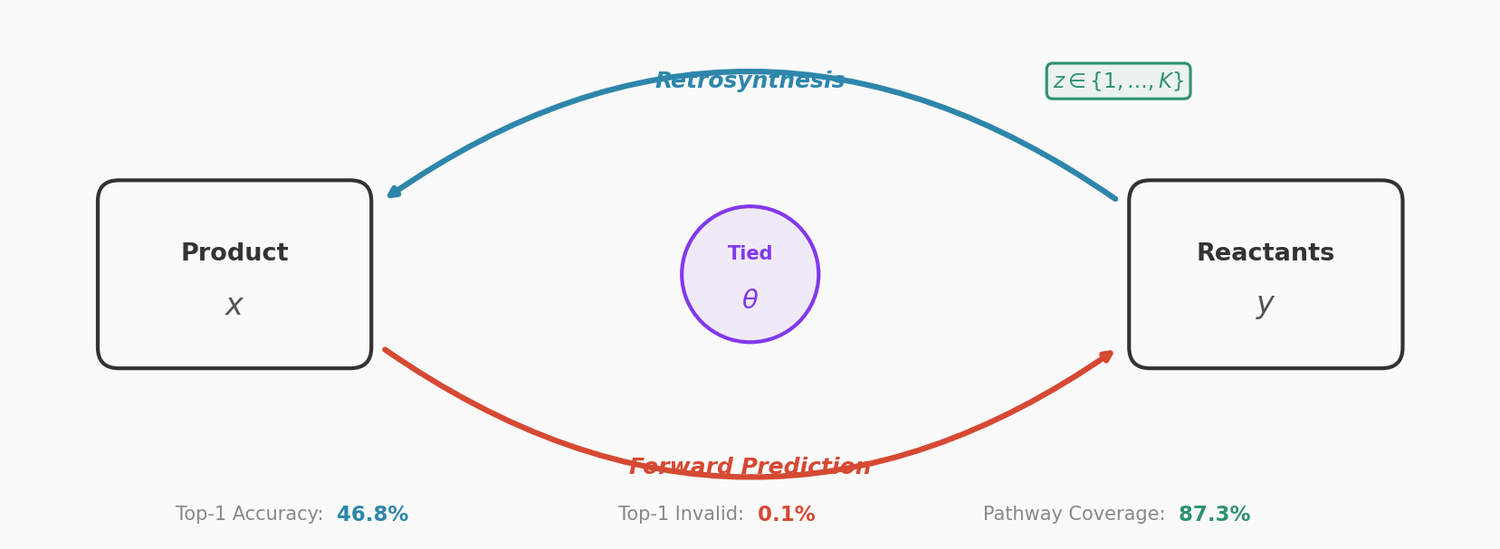
Tied Two-Way Transformers
The model pairs a retrosynthesis transformer $p(y|z, x)$ (product to reactants) with a forward reaction transformer $p(\tilde{x}|z, y)$ (reactants to product). Both use the standard encoder-decoder transformer architecture with 6 layers, 8 attention heads, and 256-dimensional embeddings.
The key architectural innovation is aggressive parameter tying: the two transformers share the entire encoder and all decoder parameters except layer normalization. This means the two-transformer system has approximately the same parameter count as a single transformer (17.5M vs. 17.4M). The shared parameters force the model to learn bidirectional reaction patterns from both forward and backward training data simultaneously, improving grammar learning and reducing invalid outputs.
Multinomial Latent Variables
A discrete latent variable $z \in \{1, \ldots, K\}$ is introduced to capture multiple reaction modes. Each latent value conditions a different decoding path, encouraging diverse reactant predictions. The decoder initializes with a latent-class-specific start token (e.g., “<CLS2>”) and then decodes autoregressively.
The prior $p(z|x)$ is a learned multinomial distribution parametrized by a two-layer feed-forward network with tanh activation, taking the mean-pooled encoder output as input. This learned prior outperforms the uniform prior used by Chen et al., producing a smaller trade-off between top-1 and top-10 accuracy as $K$ increases.
Training with Hard EM
Since the latent variable $z$ is unobserved during training, the model is trained with the online hard-EM algorithm. The loss function is:
$$\mathcal{L}(\theta) = \mathbb{E}_{(x,y) \sim \text{data}} \left[ \min_{z} \mathcal{L}_h(x, y, z; \theta) \right]$$
where $\mathcal{L}_h = -(\log p(z|x) + \log p(y|z,x) + \log p(\tilde{x}=x|z,y))$. The E-step selects the best $z$ for each training pair (with dropout disabled), and the M-step updates parameters given the complete data.
Inference with Cycle Consistency Reranking
At inference, the model: (1) generates $K$ sets of beam search hypotheses from the retrosynthesis transformer (one per latent value), (2) scores each candidate with the forward reaction transformer for cycle consistency $p(\tilde{x}=x|z,y)$, and (3) reranks candidates by the full likelihood $p(z|x) \cdot p(y|z,x) \cdot p(\tilde{x}=x|z,y)$. This pushes chemically plausible predictions to higher ranks.
Results on USPTO-50K
All results are averaged over 5 random seeds with beam size 10.
| Model | Top-1 Acc. | Top-5 Acc. | Top-10 Acc. | Top-1 Invalid | Top-10 Invalid |
|---|---|---|---|---|---|
| Liu-LSTM | 37.4% | 57.0% | 61.7% | 12.2% | 22.0% |
| SCROP | 43.7% | 65.2% | 68.7% | 0.7% | 2.3% |
| Lin-TF | 42.0% | 71.3% | 77.6% | 2.2% | 7.8% |
| Base transformer | 44.3% | 68.4% | 72.7% | 1.7% | 12.1% |
| Proposed ($K$=5) | 46.8% | 73.5% | 78.5% | 0.1% | 2.6% |
The proposed model achieves a +3.1% top-1 accuracy improvement over the best previous template-free method and reduces top-1 invalid rate to 0.1%.
Ablation Analysis
The ablation study isolates the contribution of each component:
- Base+CC (cycle consistency only): reranks candidates to improve top-1/3/5 accuracy and validity, but top-10 stays the same since the candidate set is unchanged. Parameter count doubles (34.8M).
- Base+PT (parameter tying only): improves accuracy and validity at all top-$k$ levels with negligible parameter increase. Parameter tying during training improves the retrosynthesis transformer itself, even without cycle consistency at inference.
- Proposed ($K$=1): combines tying with cycle consistency reranking.
- Proposed ($K$=5): adds latent diversity, further improving top-10 accuracy (+2.2%) and reducing top-10 invalid rate (from 10.2% to 2.6%).
Diversity: Unique Rate
As $K$ increases from 1 to 5, the unique molecule rate among 10 predictions rises substantially, confirming that latent modeling produces more diverse candidates. The learned prior reduces the top-1/top-10 accuracy trade-off compared to Chen et al.’s uniform prior.
Results on In-House Multi-Pathway Dataset
The in-house dataset (162K reactions from Reaxys) contains multiple ground-truth reactions per product, enabling direct evaluation of pathway diversity through coverage (proportion of ground-truth pathways correctly predicted in the top-10 candidates).
| Model | Top-1 Acc. | Top-10 Acc. | Unique Rate | Coverage |
|---|---|---|---|---|
| Base | 64.2% | 91.6% | 76.1% | 84.4% |
| Proposed | 66.0% | 92.8% | 93.2% | 87.3% |
The proposed model covers 87.3% of ground-truth reaction pathways on average, compared to 84.4% for the baseline. The unique rate jumps from 76.1% to 93.2%, confirming that the latent variables effectively encourage diverse predictions.
Limitations
The model uses SMILES string representation, which linearizes molecules and does not exploit the inherently rich chemical graph structure. Graph-based retrosynthesis models (e.g., GraphRetro at 63.8% top-1) substantially outperform template-free string-based models. The USPTO-50K dataset provides only one ground-truth pathway per product, making diversity evaluation limited on this benchmark. The in-house dataset is not publicly available. The model also does not predict reaction conditions (solvents, catalysts, temperature) or reagents.
Reproducibility
| Artifact | Type | License | Notes |
|---|---|---|---|
| ejklike/tied-twoway-transformer | Code | Not specified | Training and inference code |
Data: USPTO-50K dataset (public, 50K reactions from USPTO patents). In-house dataset (162K reactions from Reaxys, not publicly available).
Hardware: 4 NVIDIA Tesla M40 GPUs. Checkpoints saved every 5000 steps, last 5 averaged.
Training: Adam optimizer ($\beta$ = 0.9, 0.98), initial learning rate 2 with 8000 warm-up steps, dropout 0.3, gradient accumulation over 4 batches. Label smoothing set to 0.
Inference: Beam size 10, generating 10 candidates per product.