Text-Based Crystal Property Prediction with LLMs
LLM-Prop is a Method paper that proposes using the encoder portion of T5 (a general-purpose language model) fine-tuned on crystal text descriptions to predict physical and electronic properties of crystalline materials. The primary contribution is demonstrating that text-based representations of crystals, generated by Robocrystallographer, can serve as effective inputs for property prediction, outperforming graph neural network (GNN) baselines on several tasks despite using a non-domain-specific pre-trained model with fewer parameters.
Why Text Instead of Crystal Graphs?
Graph neural networks have been the dominant approach for crystal property prediction. Models like CGCNN, MEGNet, and ALIGNN represent crystals as graphs where atoms are nodes and bonds are edges. However, GNNs face several fundamental challenges for crystals:
- Periodicity encoding: Crystals have repetitive unit cell arrangements that are distinct from standard molecular graphs, and GNNs struggle to encode this periodicity efficiently.
- Information incorporation: Critical structural information like bond angles, space group symmetry, and Wyckoff sites is difficult to incorporate into graph representations.
- Expressiveness: Graphs may lack the expressiveness needed to convey complex crystal information relevant to property prediction.
Meanwhile, textual descriptions of crystals (generated by tools like Robocrystallographer) naturally encode space group information, bond geometries, coordination environments, and symmetry details in human-readable form. Despite this richness, text-based approaches for crystal property prediction had been largely unexplored.
Core Innovation: T5 Encoder with Careful Fine-Tuning
The key insight of LLM-Prop is to take a pre-trained encoder-decoder model (T5-small) and discard the decoder entirely, using only the encoder with a linear prediction head. This design has several advantages:
- Cutting the network in half (from ~60M to ~37M parameters) allows processing of longer input sequences
- Longer sequences mean more crystal information can be included
- The encoder-only approach avoids T5’s known weakness at regression in text-to-text format
The framework applies several preprocessing strategies to the crystal text descriptions:
- Stopword removal: Standard English stopwords are removed, except digits and symbols carrying chemical information
- Numerical token replacement: Bond distances are replaced with a
[NUM]token and bond angles with[ANG], reducing sequence length while preserving structural cues - [CLS] token prepending: A classification token is added at the start, and its learned embedding is used as input to the prediction layer
- Label scaling: For regression tasks, targets are normalized using z-score, min-max, or log normalization
The normalization schemes are defined as:
$$ \hat{Y}_{i}(\text{z-score}) = \frac{Y_{i} - \mu}{\sigma} $$
$$ \hat{Y}_{i}(\text{min-max}) = \frac{Y_{i} - Y_{\min}}{Y_{\max} - Y_{\min}} $$
$$ \hat{Y}_{i}(\text{log-norm}) = \log(Y_{i} + 1) $$
The tokenizer is also retrained on the crystal text corpus with a vocabulary size of 32k, and the special tokens [NUM], [ANG], and [CLS] are added to the vocabulary.
Experimental Setup and Baselines
Dataset: TextEdge
The authors collected data from the Materials Project database (as of November 2022), yielding 144,931 crystal structure-description pairs split into 125,098 training, 9,945 validation, and 9,888 test samples. Crystal text descriptions were generated using Robocrystallographer. The dataset covers six prediction tasks:
| Task | Type | Metric |
|---|---|---|
| Band gap (eV) | Regression | MAE (lower is better) |
| Unit cell volume (A^3/cell) | Regression | MAE (lower is better) |
| Formation energy per atom (eV/atom) | Regression | MAE (lower is better) |
| Energy per atom (eV/atom) | Regression | MAE (lower is better) |
| Energy above hull (eV/atom) | Regression | MAE (lower is better) |
| Is-gap-direct | Classification | AUC (higher is better) |
Baselines
Seven baselines were compared:
- GNN-based: CGCNN, MEGNet, ALIGNN, DeeperGATGNN
- Classic ML: XGBoost, Random Forest (on Robocrystallographer features)
- Text-based: MatBERT (domain-specific pre-trained BERT, ~110M parameters)
All models were trained and evaluated on the same dataset splits for fair comparison. GNN models were retrained on the new data rather than using results from older, smaller Materials Project versions.
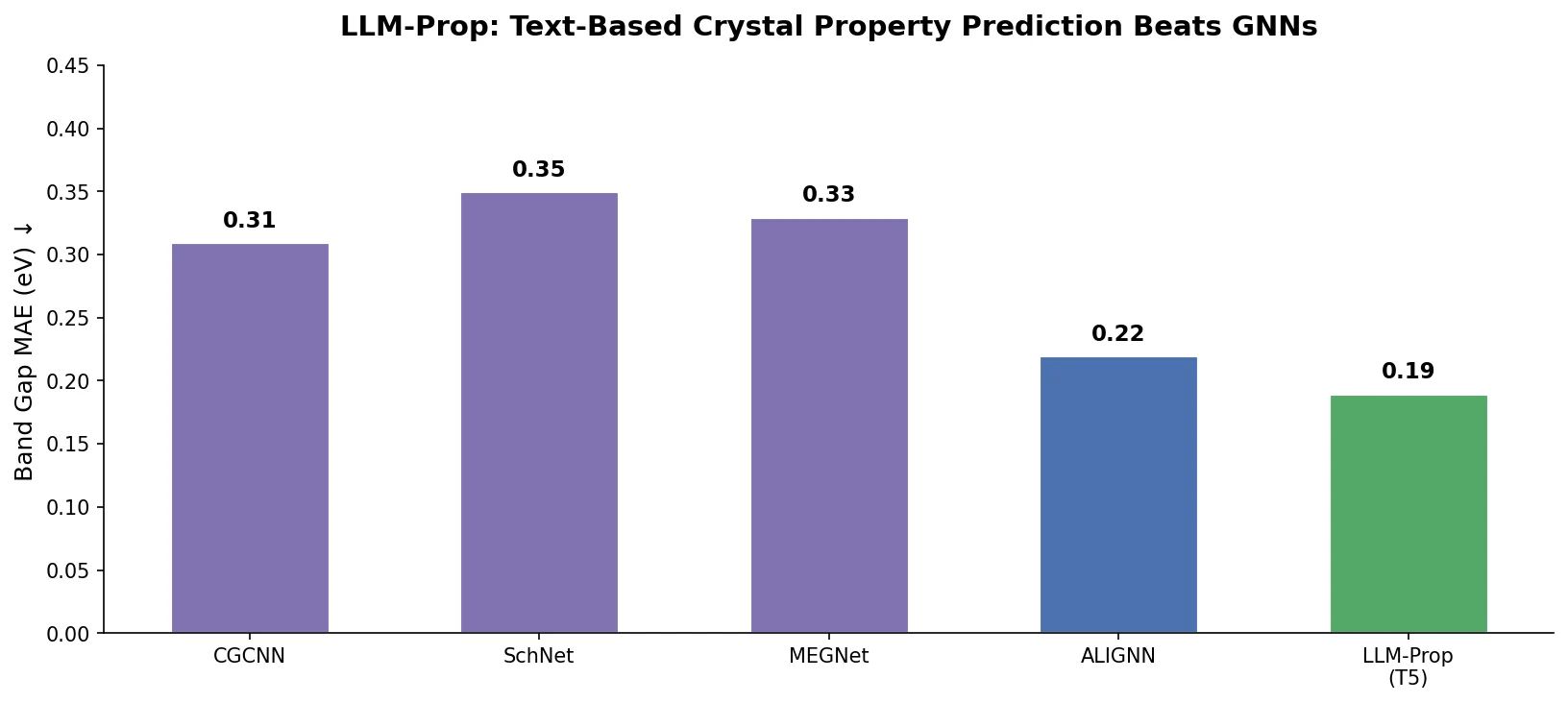
Main Results: LLM-Prop vs. GNN Baselines
When using crystal text descriptions as input, LLM-Prop achieved:
| Model | Band gap (eV) | Volume (A^3/cell) | FEPA (eV/atom) | EPA (eV/atom) | Ehull (eV/atom) | Is-gap-direct (AUC) |
|---|---|---|---|---|---|---|
| CGCNN | 0.293 | 188.834 | 0.046 | 0.082 | 0.040 | 0.830 |
| MEGNet | 0.304 | 297.948 | 0.077 | 0.056 | 0.051 | N/A |
| ALIGNN | 0.250 | 129.580 | 0.027 | 0.059 | 0.028 | 0.678 |
| DeeperGATGNN | 0.291 | 111.857 | 0.081 | 0.116 | 0.045 | N/A |
| LLM-Prop (Descr.) | 0.231 | 39.252 | 0.056 | 0.067 | 0.047 | 0.857 |
LLM-Prop outperformed the best GNN baseline (ALIGNN) by approximately 8% on band gap prediction, 65% on volume prediction, and 3% on band gap classification (Is-gap-direct). For formation energy per atom, energy per atom, and energy above hull, ALIGNN retained an advantage.
LLM-Prop vs. MatBERT
LLM-Prop also outperformed MatBERT (a domain-specific pre-trained BERT) across all tasks despite having roughly 3x fewer parameters. The table below shows the best result for each model across the three input preprocessing strategies (w/ Numbers, w/o Numbers, w/ [NUM]&[ANG]):
| Model | Band gap (eV) | Volume (A^3/cell) | FEPA (eV/atom) | EPA (eV/atom) | Ehull (eV/atom) | Is-gap-direct (AUC) |
|---|---|---|---|---|---|---|
| MatBERT (best) | 0.258 | 54.969 | 0.071 | 0.098 | 0.050 | 0.722 |
| LLM-Prop (best) | 0.231 | 39.138 | 0.056 | 0.067 | 0.047 | 0.857 |
Note: LLM-Prop’s best band gap (0.231) comes from the “w/o Numbers” configuration, while the best volume (39.138) comes from “w/ Numbers”. The best Is-gap-direct AUC (0.857) uses the “[NUM]&[ANG]” configuration.
Ablation Studies
The contribution of each preprocessing strategy was evaluated:
| Configuration | Band gap | Volume | Is-gap-direct (AUC) |
|---|---|---|---|
| LLM-Prop (baseline) | 0.256 | 69.352 | 0.796 |
| + modified tokenizer | 0.247 | 78.632 | 0.785 |
| + label scaling | 0.242 | 44.515 | N/A |
| + [CLS] token | 0.231 | 39.520 | 0.842 |
| + [NUM] token | 0.251 | 86.090 | 0.793 |
| + [ANG] token | 0.242 | 64.965 | 0.810 |
| - stopwords | 0.252 | 56.593 | 0.779 |
| LLM-Prop+all (no space group) | 0.235 | 97.457 | 0.705 |
| LLM-Prop+all | 0.229 | 42.259 | 0.857 |
The [CLS] token provided the single largest improvement across all tasks. Label scaling was critical for volume prediction (reducing MAE from 69.352 to 44.515). Removing space group information from descriptions degraded volume prediction dramatically (from 42.259 to 97.457), confirming that space group symmetry is a key factor.
Data Efficiency and Transfer Learning
LLM-Prop achieved SOTA results on band gap and volume prediction with only about 90k training samples (35k fewer than baselines). For volume prediction specifically, LLM-Prop outperformed all GNN baselines with just 30k training samples.
Transfer learning experiments showed that LLM-Prop transferred well between band gap and volume prediction tasks:
| Model | Volume-to-Band gap (Test) | Band gap-to-Volume (Test) |
|---|---|---|
| CGCNN-transfer | 0.295 | 182.997 |
| ALIGNN-transfer | 0.322 | 136.164 |
| MatBERT-transfer | 0.266 | 54.289 |
| LLM-Prop-transfer | 0.244 | 50.753 |
Key Findings, Limitations, and Future Directions
Key findings:
- Text descriptions of crystals carry rich structural information (space groups, Wyckoff sites, coordination geometries) that is difficult to encode in graphs but naturally expressed in text
- A carefully fine-tuned general-purpose LLM encoder can outperform domain-specific pre-trained models, challenging the assumption that in-domain pre-training is always necessary
- Removing numerical information (bond distances and angles) from descriptions often improves performance, because current LLMs treat numbers as regular tokens without understanding their quantitative meaning
- Longer input sequences correlate with better performance, with 888 tokens as the default maximum on the hardware used
Limitations acknowledged by the authors:
- The origin of LLM-Prop’s performance advantage over GNNs is not fully understood. It remains unclear whether the boost comes from additional structured information in text or from the different data modality itself
- LLM-Prop cannot perform zero-shot predictions since T5 was not pre-trained on materials science data
- The approach depends on Robocrystallographer to generate text descriptions, adding a preprocessing dependency
- Current LLMs’ inability to reason about numerical values limits the use of quantitative information in descriptions
Future directions suggested by the authors include investigating techniques to use CIF files directly as LLM inputs, developing new GNN architectures that incorporate space group and Wyckoff site information, and further exploring which information in crystal descriptions contributes most to each property prediction task.
Reproducibility Details
Data
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Training/Eval | TextEdge | 144,931 crystals | From Materials Project (Nov 2022), text generated by Robocrystallographer |
| Training split | TextEdge | 125,098 | Random split |
| Validation split | TextEdge | 9,945 | Random split |
| Test split | TextEdge | 9,888 | Random split |
Algorithms
- Optimizer: Adam with one-cycle learning rate scheduler
- Learning rate: 1e-3 for LLM-Prop, 5e-5 for MatBERT
- Dropout: 0.2 for LLM-Prop, 0.5 for MatBERT
- Batch size: 64 (888 tokens) or 16 (2000 tokens) for LLM-Prop
- Epochs: 200-300 depending on task
- Loss: MAE for regression, BCE for classification
- Evaluation: MAE for regression, AUC for classification
- Each model run 5 times on test set, averaged MAE reported
Models
- Base model: T5-small encoder (~60M parameters total, ~37M after discarding decoder and adding prediction head)
- Vocabulary size: 32k (retrained tokenizer)
- Max input tokens: 888 (default) or 2000
- Special tokens: [CLS], [NUM], [ANG]
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| LLM-Prop | Code | MIT | Official implementation |
| TextEdge + Checkpoints | Dataset + Model | Not specified | Benchmark dataset and trained model checkpoints |
Hardware
- GPUs: NVIDIA RTX A6000
- Training time: ~40 minutes per epoch for LLM-Prop
- Inference: ~1 minute for 10,000 materials on one GPU
Paper Information
Citation: Rubungo, A. N., Arnold, C. B., Rand, B. P., & Dieng, A. B. (2025). LLM-Prop: predicting the properties of crystalline materials using large language models. npj Computational Materials, 11, 186. https://doi.org/10.1038/s41524-025-01536-2
@article{rubungo2025llmprop,
title={LLM-Prop: predicting the properties of crystalline materials using large language models},
author={Rubungo, Andre Niyongabo and Arnold, Craig B. and Rand, Barry P. and Dieng, Adji Bousso},
journal={npj Computational Materials},
volume={11},
number={1},
pages={186},
year={2025},
publisher={Nature Publishing Group},
doi={10.1038/s41524-025-01536-2}
}