This group covers models that go beyond a single molecular representation by jointly learning from multiple modalities. These models enable capabilities that unimodal encoders cannot, including text-guided molecular retrieval, cross-modal captioning, and joint property prediction across chemical and biological domains.
| Paper | Year | Modalities | Key Idea |
|---|---|---|---|
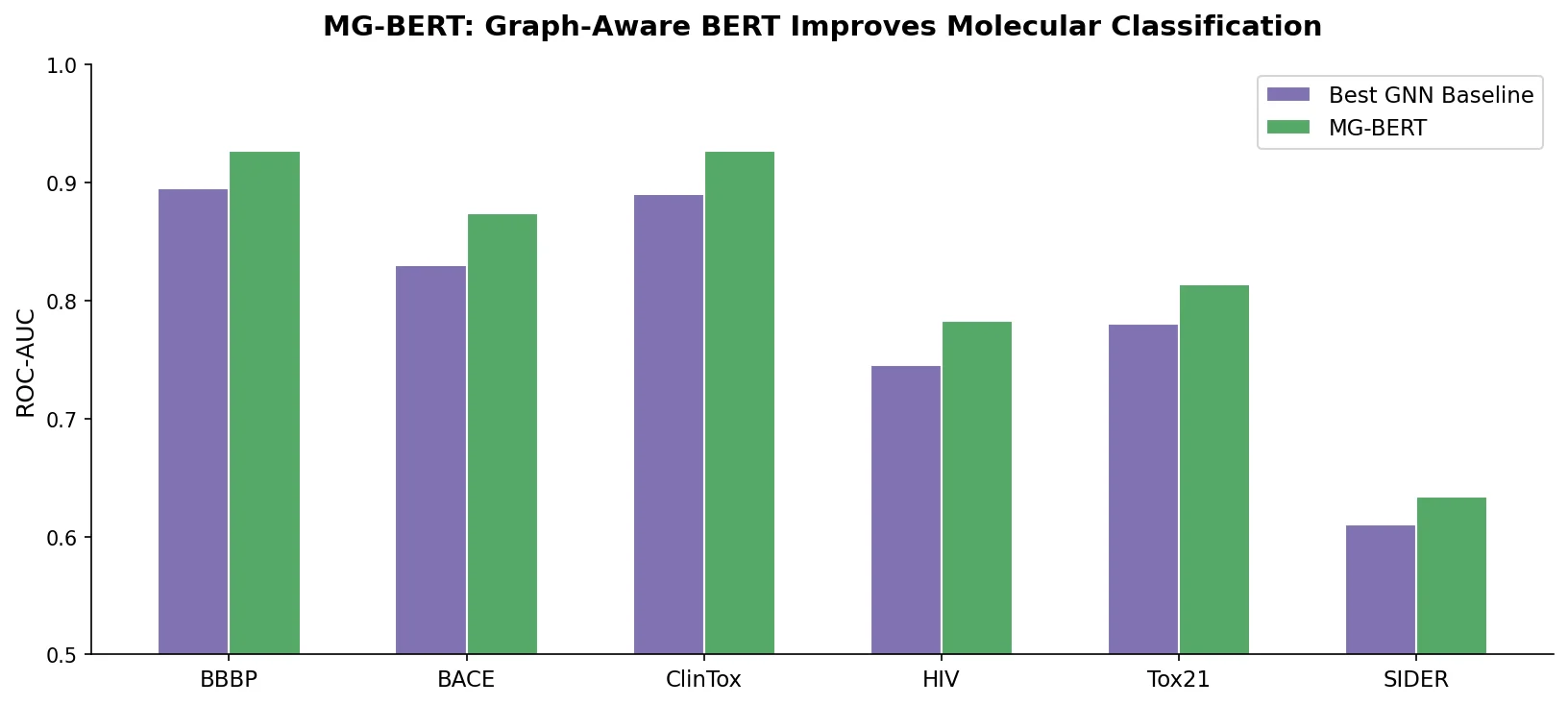
| MG-BERT | 2021 | Graph + SMILES | GNN message passing integrated with BERT pretraining |
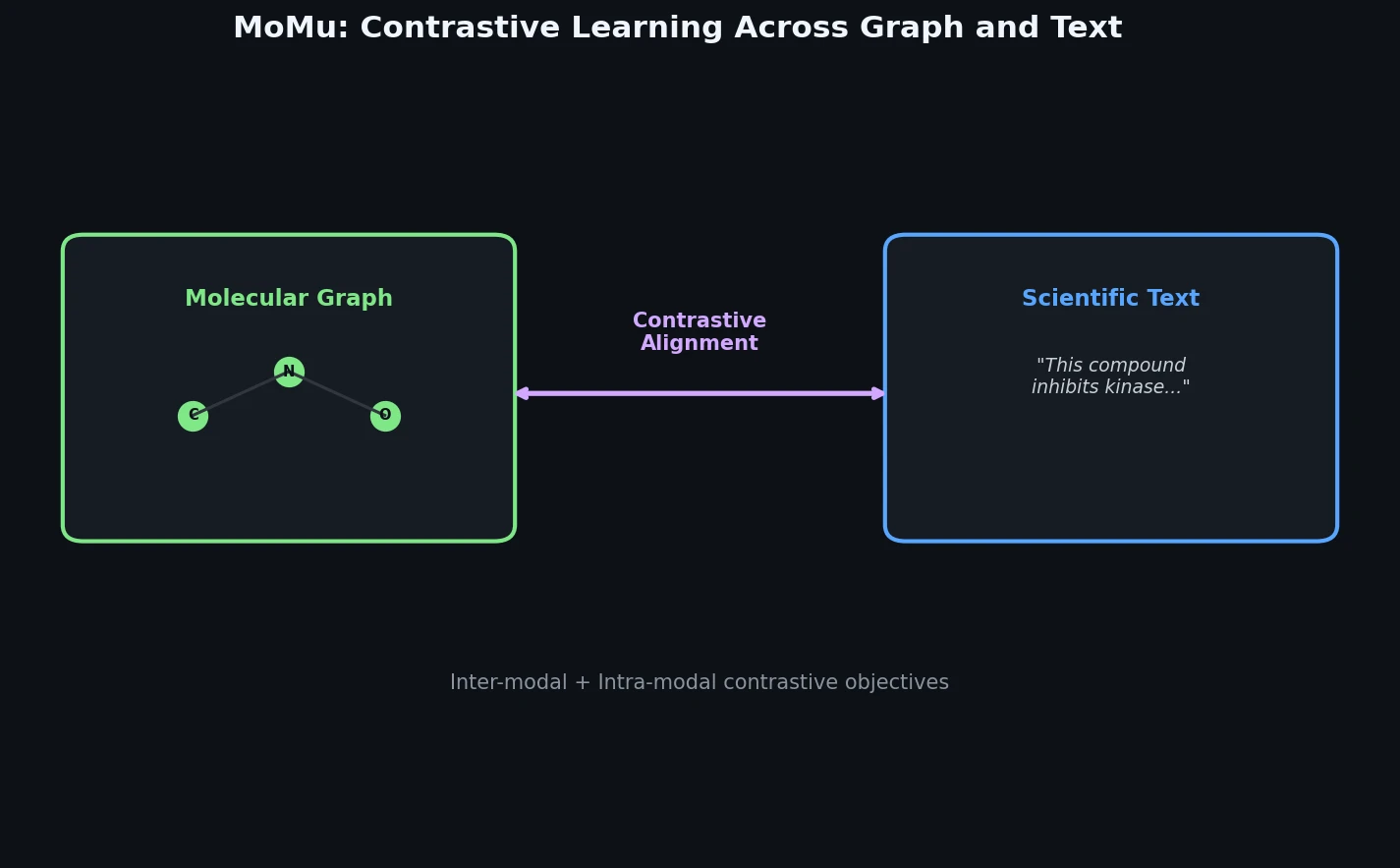
| MoMu | 2022 | Graph + text | Contrastive pre-training bridging molecular graphs and natural language |
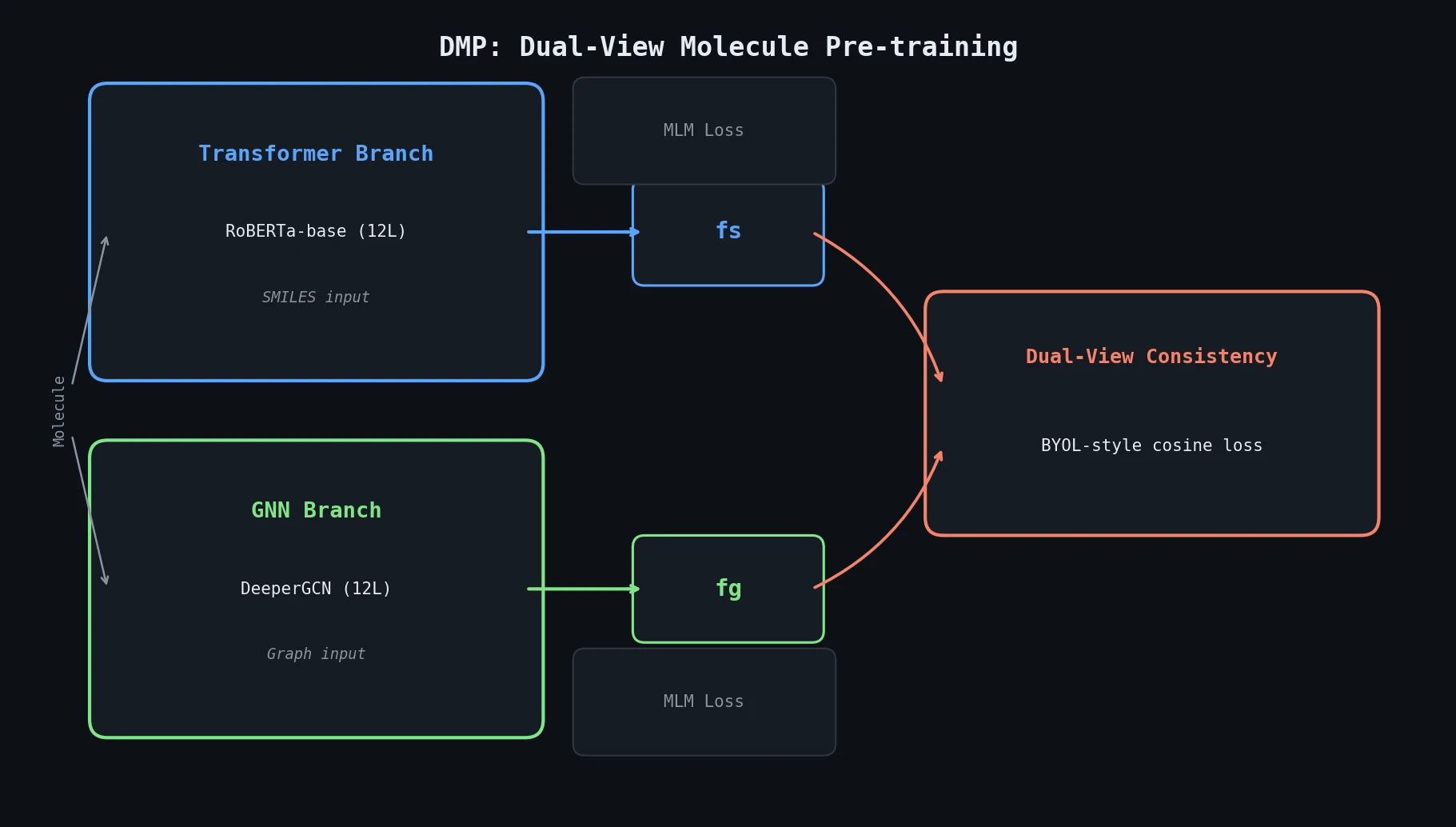
| DMP | 2023 | SMILES + graph | Dual-view consistency learning over SMILES and GNN encoders |
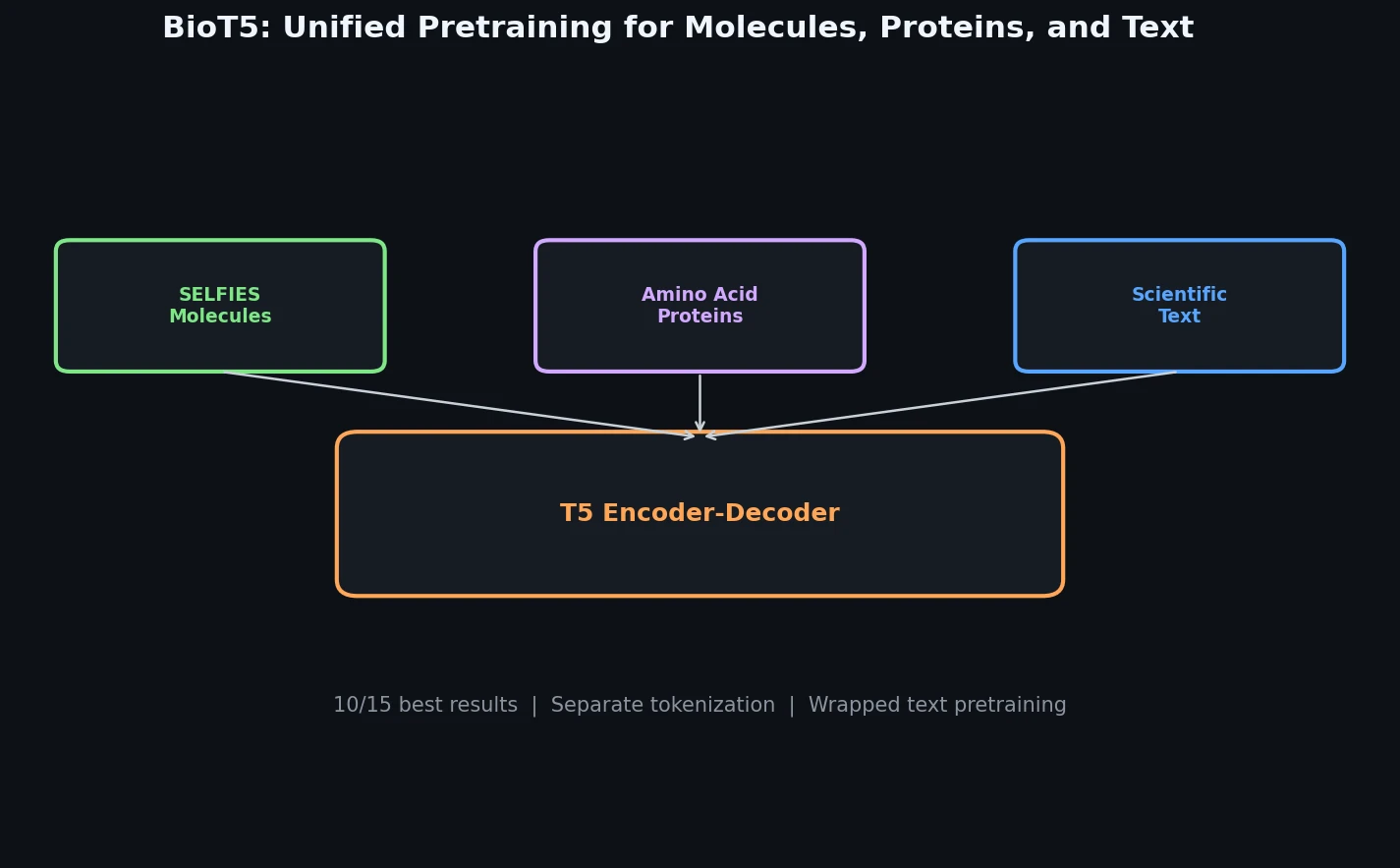
| BioT5 | 2023 | Molecule + protein + text | T5 model for cross-modal biology and chemistry |
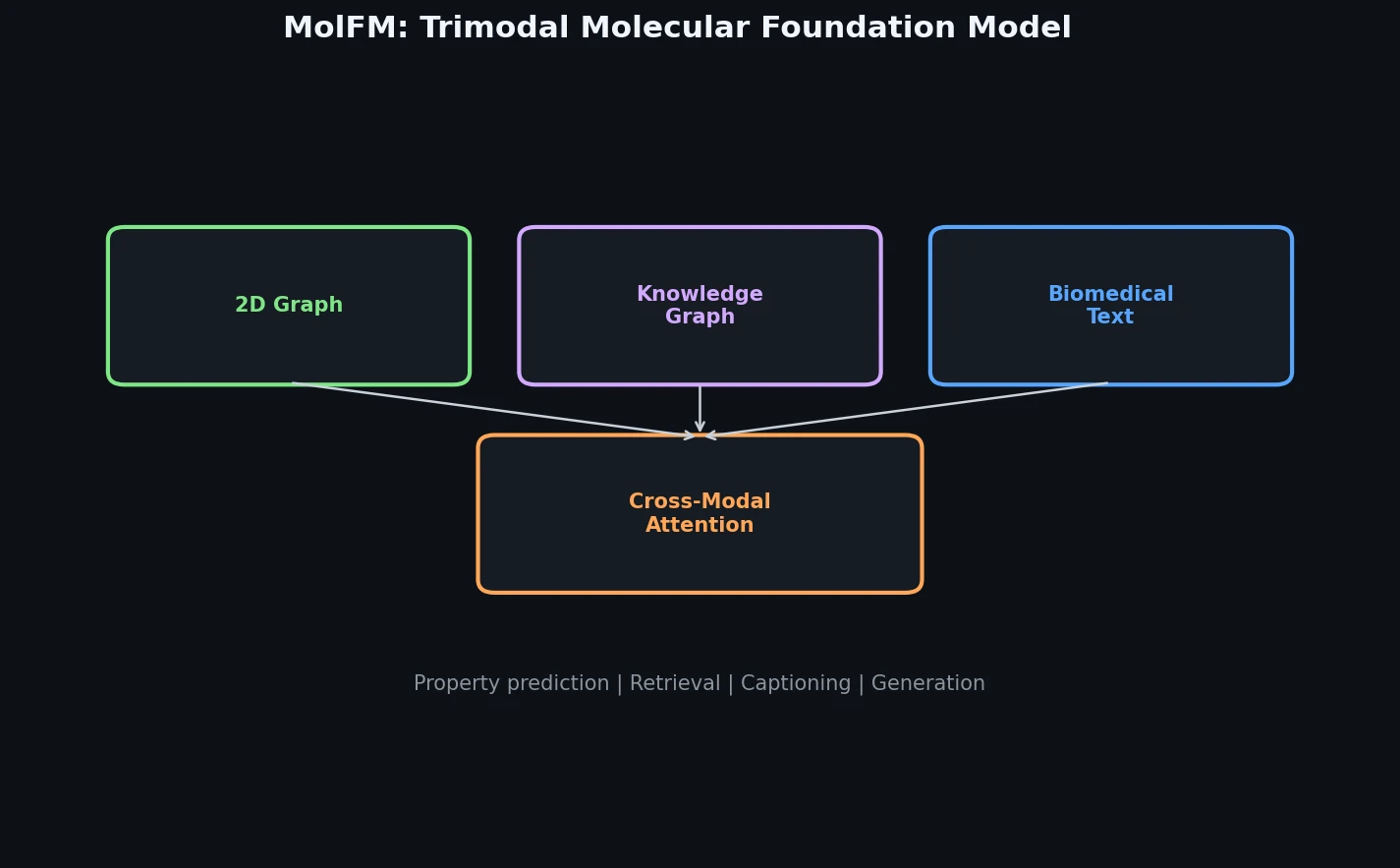
| MolFM | 2023 | Graph + text + KG | Trimodal fusion of graphs, text, and knowledge graphs |
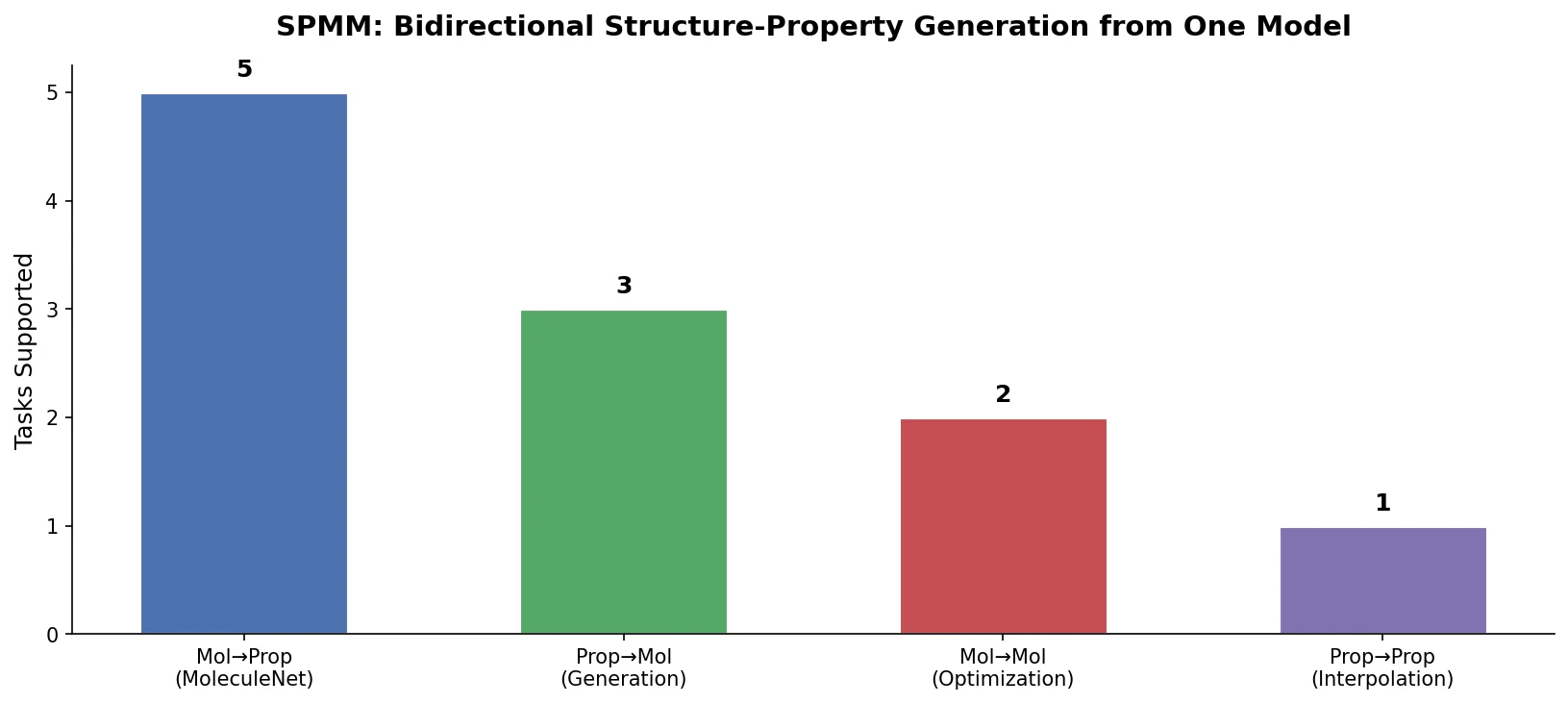
| SPMM | 2024 | Structure + properties | Bidirectional alignment of molecular structures and property vectors |
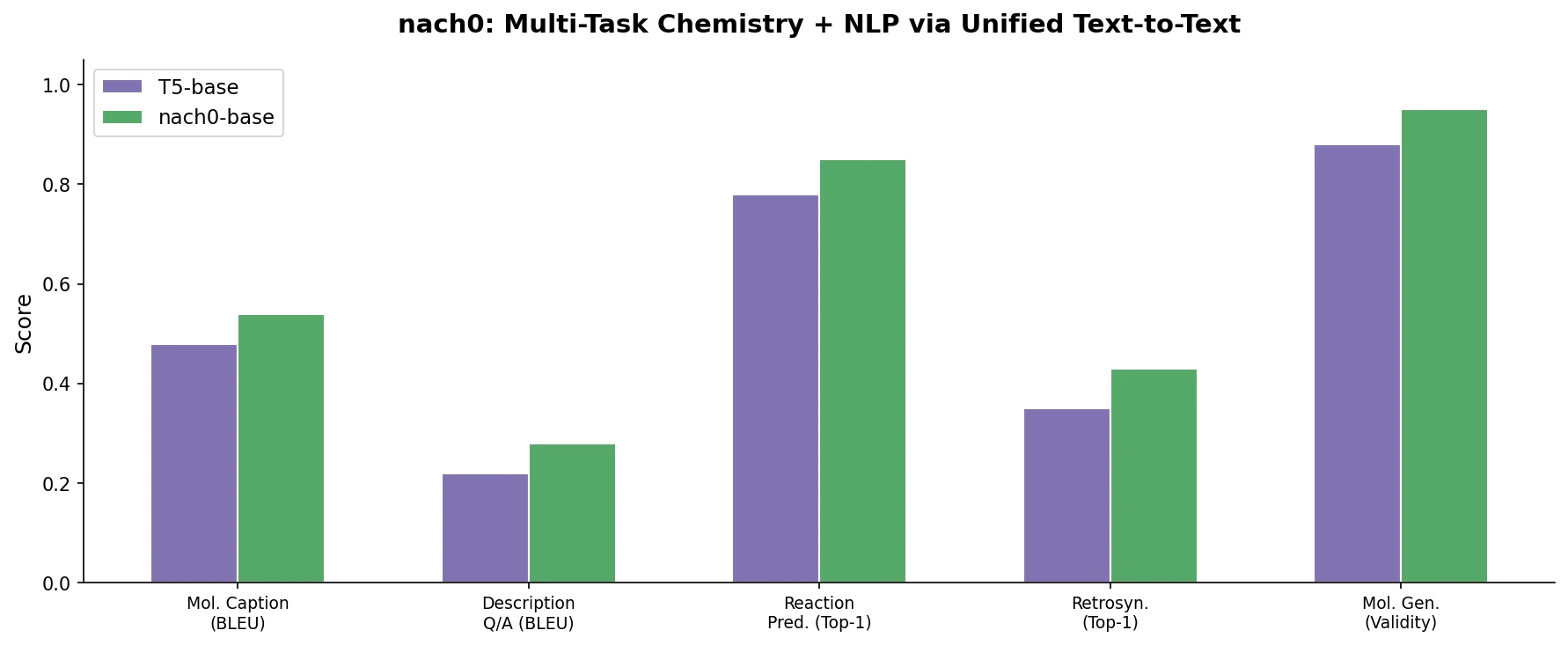
| nach0 | 2024 | SMILES + text + patents | Multi-task instruction tuning over chemistry and NLP |