InstructMol Framework Overview
Methodological Paper ($\Psi_{\text{Method}}$)
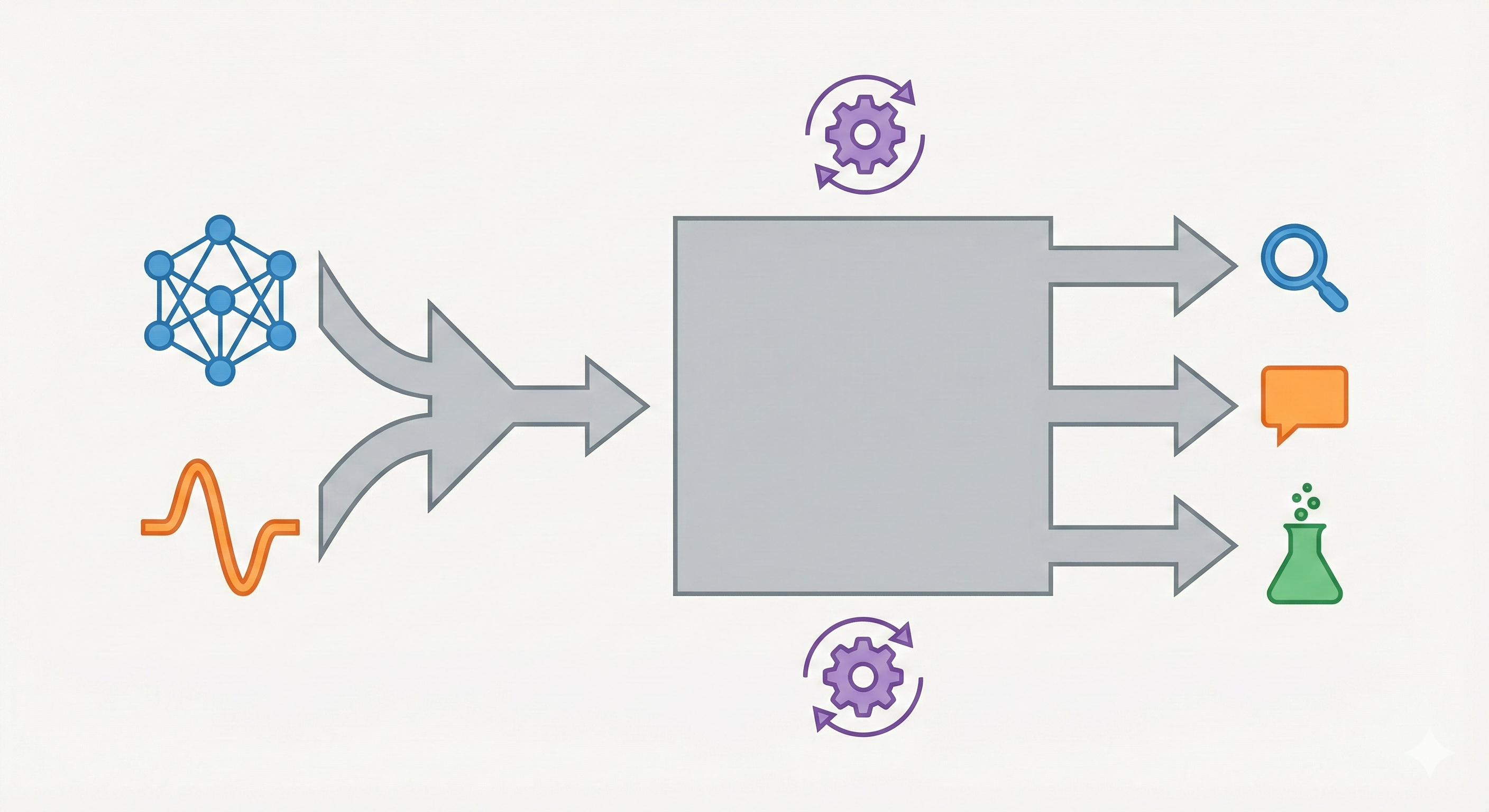
This work proposes InstructMol, a novel multi-modal architecture and training paradigm. It focuses on engineering a system that aligns a pre-trained molecular graph encoder with a general-purpose Large Language Model (LLM). The paper’s primary contribution is the Two-Stage Instruction Tuning strategy (Alignment Pre-training + Task-Specific Tuning) designed to bridge the modality gap between 2D molecular graphs and natural language.
Bridging Specialist and Generalist Models
Current AI approaches in drug discovery typically fall into two categories. Specialist models deliver high accuracy on specific tasks (such as property prediction) but require extensive labeled datasets and lack conversational adaptability. Conversely, generalist LLMs offer strong reasoning and dialogue capabilities but struggle to natively interpret complex structural data, often relying on brittle 1D text representations of molecules like SMILES.
There is a practical need for a unified “Molecular Assistant” capable of visually interpreting molecular graphs, reasoning about structure in natural language, and adapting across tasks like synthesis planning and property analysis without training from scratch.
Two-Stage Modality Alignment
The core novelty lies in the architecture and the two-stage training pipeline designed to align differing modalities efficiently:
- MoleculeSTM Integration: InstructMol initializes its graph encoder with MoleculeSTM, which is already pre-aligned with text via contrastive learning, facilitating easier downstream alignment.
- Two-Stage Alignment Strategy:
- Stage 1 (Alignment Pre-training): Freezes both the LLM and Graph Encoder; trains only a linear projector using a massive dataset of molecule-description pairs to map graph features into the LLM’s token space.
- Stage 2 (Task-Specific Instruction Tuning): Freezes the Graph Encoder; fine-tunes the Projector and the LLM (using LoRA) on specific downstream tasks. This allows the model to adapt its reasoning capabilities while preserving the structural understanding gained in Stage 1.
Task Evaluation in Drug Discovery
The authors evaluated InstructMol across three distinct categories of drug discovery tasks, comparing it against generalist LLMs (Vicuna, LLaMA, Galactica) and specialist models (ChemBERTa, MolT5):
- Property Prediction:
- Regression: Predicting quantum mechanical properties (HOMO, LUMO, Gap) using the QM9 dataset.
- Classification: Predicting biological activity (BACE, BBBP, HIV) using MoleculeNet.
- Molecule Description Generation: Generating natural language descriptions of molecules using the ChEBI-20 dataset.
- Chemical Reaction Analysis:
- Forward Reaction Prediction: Predicting products from reactants.
- Reagent Prediction: Identifying necessary reagents.
- Retrosynthesis: Suggesting reactants for a given product.
Ablation Studies tested the impact of the projector type (Linear vs. MLP), LLM scale (7B vs 13B), and the necessity of the two-stage training approach.
Core Findings and Limitations
- Improvement Over Baseline Generalists: InstructMol significantly outperformed generalist LLMs (like LLaMA and Galactica) on all tasks, demonstrating the value of incorporating explicit graph modalities.
- Reducing the Gap with Specialists: While InstructMol brings versatile reasoning capabilities, it still trails highly optimized specialist models (such as Uni-Mol and MolT5) on tasks like molecule description generation. This remaining gap likely stems from its reliance on a relatively small alignment pre-training dataset (~264K PubChem pairs) and the information bottleneck of using a simple linear projector, compared to the millions of structures used to train expert foundational models.
- Importance of Alignment: Ablation studies confirmed that skipping Stage 1 (Alignment Pre-training) degraded performance, proving that a dedicated phase for projecting graph features into text space is crucial.
- Limitation: The model struggles with highly imbalanced datasets (e.g., HIV) and complex reaction mixtures where mapping multiple graph tokens to text becomes ambiguous.
Reproducibility Details
Data
The training pipeline utilizes distinct datasets for the two stages. Note: As of the latest repository update, the finely-processed instruction-tuning datasets (e.g., the filtered ~264K PubChem pairs and instruction-formatted subset pairs) are listed as “coming soon”, requiring manual recreation for full reproduction.
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Stage 1 (Alignment) | PubChem | ~264K pairs | Molecule-text pairs. Filtered from 330K for invalid descriptions and overlaps with ChEBI-20 test set. |
| Stage 2 (Prop. Reg.) | QM9 | 362K samples | Quantum mechanics properties (HOMO, LUMO, Gap). |
| Stage 2 (Prop. Class.) | MoleculeNet | 35K samples | BACE, BBBP, HIV datasets. Converted to instruction format (Yes/No answer). |
| Stage 2 (Generation) | ChEBI-20 | 26.5K samples | Molecule description generation. |
| Stage 2 (Reactions) | USPTO | ~380K samples | Combined datasets for Forward (125K), Retrosynthesis (130K), and Reagent (125K) prediction. |
Algorithms
- Two-Stage Training:
- Alignment Pre-training: Updates only the Projector. The objective maximizes the probability of generating the target description token sequence $\mathbf{X}_A$ given the molecule input $\mathbf{X}_M$ and instruction $\mathbf{X}_I$: $$p(\mathbf{X}_A | \mathbf{X}_M, \mathbf{X}_I) = \prod_{i=1}^L p_\theta(x_i | \mathbf{X}_G \parallel \mathbf{X}_S, \mathbf{X}_I, \mathbf{X}_{A,<i})$$
- Instruction Tuning: Updates Projector + LLM (via LoRA) using standard autoregressive language modeling on task-specific instructions. The objective minimizes the negative log-likelihood of generating the target response $R$ of length $L$: $$\mathcal{L}(\theta) = -\sum_{i=1}^L \log p(R_i | I, M, R_{<i}; \theta)$$ where $I$ represents the instruction and $M$ is the multi-modal molecular input.
- LoRA (Low-Rank Adaptation): Applied to the LLM in Stage 2. Rank $r=64$, Scaling $\alpha=16$.
- Optimization: AdamW optimizer. Learning rate starts at 2e-3 (Stage 1) and 8e-5 (Stage 2) with cosine decay. Warm-up ratio 0.03.
Models
Note: The official repository currently lists the final fine-tuned InstructMol weights as “coming soon.” Consequently, one must fine-tune the components using the provided scripts. Base model weights (Vicuna-7B and MoleculeSTM) are publicly available via Hugging Face.
- Graph Encoder ($f_g$):
- Architecture: Graph Isomorphism Network (GIN) with 5 layers.
- Hidden Dimension: 300.
- Initialization: MoleculeSTM checkpoint (pre-trained via contrastive learning).
- Status: Frozen during Stage 2.
- LLM:
- Base: Vicuna-v1.3-7B.
- Status: Frozen in Stage 1; LoRA fine-tuned in Stage 2.
- Projector:
- Architecture: Linear Layer.
- Function: Maps node-level graph representation $Z_G \in \mathbb{R}^{N \times d}$ to the LLM’s word embedding space dimensions.
Evaluation
- Metric Libraries: RDKit for validity/fingerprints, standard NLP libraries for BLEU/ROUGE.
- Reaction Metrics: Fingerprint Tanimoto Similarity (FTS), Exact Match, Levenshtein distance, and validity (via RDKit).
- Description Metrics: BLEU-2, BLEU-4, ROUGE-1, ROUGE-2, ROUGE-L, METEOR.
Hardware
- Compute: 4 x NVIDIA RTX A6000 (48GB VRAM).
- Training Time:
- Stage 1: 5 epochs.
- Stage 2: 20-50 epochs (Description Generation), 10 epochs (Properties/Reactions).
- Batch Size: 128 for both stages.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| InstructMol (GitHub) | Code | Apache 2.0 (code), CC BY-NC 4.0 (data) | Training/evaluation scripts provided; fine-tuned weights listed as “coming soon” |
| Vicuna-7B v1.3 | Model | Non-commercial (LLaMA license) | Base LLM; must be downloaded separately |
| MoleculeSTM | Model | MIT | Pre-trained graph encoder checkpoint |
Paper Information
Citation: Cao, H., Liu, Z., Lu, X., Yao, Y., & Li, Y. (2025). InstructMol: Multi-Modal Integration for Building a Versatile and Reliable Molecular Assistant in Drug Discovery. Proceedings of the 31st International Conference on Computational Linguistics, 354-379.
Publication: COLING 2025
@inproceedings{caoInstructMolMultiModalIntegration2025,
title = {{{InstructMol}}: {{Multi-Modal Integration}} for {{Building}} a {{Versatile}} and {{Reliable Molecular Assistant}} in {{Drug Discovery}}},
shorttitle = {{{InstructMol}}},
booktitle = {Proceedings of the 31st {{International Conference}} on {{Computational Linguistics}}},
author = {Cao, He and Liu, Zijing and Lu, Xingyu and Yao, Yuan and Li, Yu},
editor = {Rambow, Owen and Wanner, Leo and Apidianaki, Marianna and {Al-Khalifa}, Hend and Eugenio, Barbara Di and Schockaert, Steven},
year = 2025,
month = jan,
pages = {354--379},
publisher = {Association for Computational Linguistics},
address = {Abu Dhabi, UAE},
abstract = {The rapid evolution of artificial intelligence in drug discovery encounters challenges with generalization and extensive training, yet Large Language Models (LLMs) offer promise in reshaping interactions with complex molecular data. Our novel contribution, InstructMol, a multi-modal LLM, effectively aligns molecular structures with natural language via an instruction-tuning approach, utilizing a two-stage training strategy that adeptly combines limited domain-specific data with molecular and textual information. InstructMol showcases substantial performance improvements in drug discovery-related molecular tasks, surpassing leading LLMs and significantly reducing the gap with specialists, thereby establishing a robust foundation for a versatile and dependable drug discovery assistant.}
}
Additional Resources: