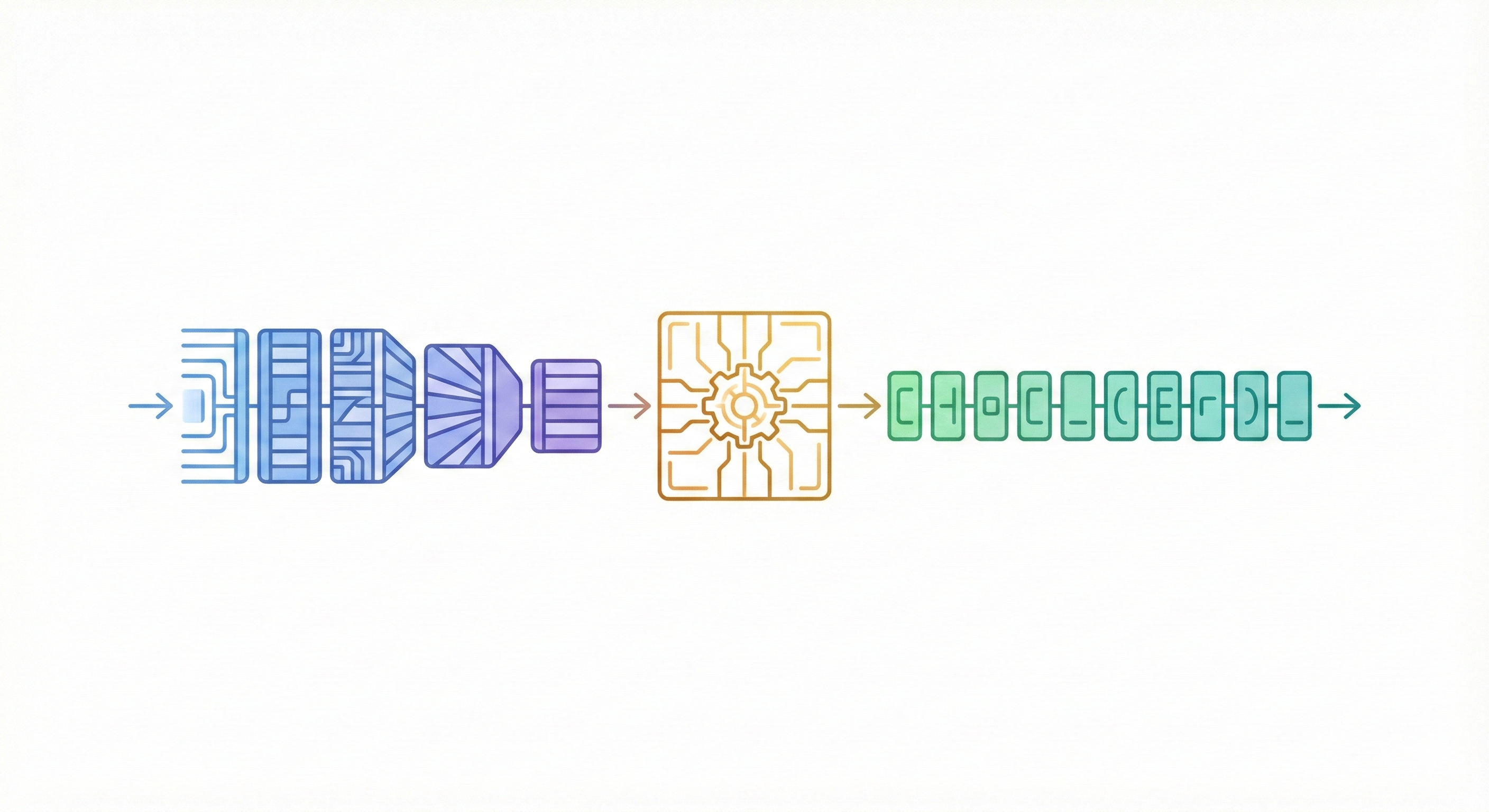
Primary Contribution: A Transformer-Based Method
This is primarily a Method paper. It adapts a specific architecture (Transformer) to a specific task (InChI-to-IUPAC translation) and evaluates its performance against both machine learning and commercial baselines. It also has a secondary Resource contribution, as the trained model and scripts are released as open-source software.
Motivation: The Bottleneck in Algorithmic IUPAC Nomenclature
Generating correct IUPAC names is difficult due to the comprehensive but complex rules defined by the International Union of Pure and Applied Chemistry. Commercial software generates names from structures but remains closed-source with opaque methodologies and frequent inter-package disagreements. Open identifiers like InChI and SMILES lack direct human readability. This creates a need for an open, automated method to generate informative IUPAC names from standard identifiers like InChI, which are ubiquitous in online chemical databases.
Novelty: Treating Chemical Translation as a Character-Level Sequence
The key novelty is treating chemical nomenclature translation as a character-level sequence-to-sequence problem using a Transformer architecture, specifically using InChI as the source language.
- Standard Neural Machine Translation (NMT) uses sub-word tokenization. This model processes InChI and predicts IUPAC names character-by-character.
- It demonstrates that character-level tokenization outperforms byte-pair encoding or unigram models for this specific chemical task.
- It uses InChI’s standardization to avoid the canonicalization issues inherent in SMILES-based approaches.
- The attention mechanism allows the decoder to align specific parts of the generated IUPAC name with corresponding structural features in the source InChI string, operating via the standard scaled dot-product attention: $$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
Methodology & Experimental Validation
- Training: The model was trained on 10 million InChI/IUPAC pairs sampled from PubChem using a character-level objective. The model is supervised using categorical cross-entropy loss across the vocabulary of characters: $$ \mathcal{L} = -\sum_{i=1}^{N} y_i \log(\hat{y}_i) $$
- Ablation Studies: The authors experimentally validated architecture choices, finding that LSTM models and sub-word tokenization (BPE) performed worse than the Transformer with character tokenization. They also optimized dropout rates.
- Performance Benchmarking: The model was evaluated on a held-out test set of 200,000 samples. Performance was quantified primarily by Whole-Name Accuracy and Normalized Edit Distance (based on the Damerau-Levenshtein distance, scaled by the maximum string length).
- Commercial Comparison: The authors compared their model against four major commercial packages (ACD/I-Labs, ChemAxon, Mestrelab, and PubChem’s Lexichem). However, this evaluation used a highly limited test set of only 100 molecules, restricting the statistical confidence of the external baseline.
- Error Analysis: They analyzed performance across different chemical classes (organics, charged species, macrocycles, inorganics) and visualized attention coefficients to interpret model focus.
Key Results and the Inorganic Challenge
- High Accuracy on Organics: The model achieved 91% whole-name accuracy on the test set, performing particularly well on organic compounds.
- Comparable to Commercial Tools: On the limited 100-molecule benchmark, the edit distance between the model’s predictions and commercial packages (15-23%) was similar to the variation found between the commercial packages themselves (16-21%).
- Limitations on Inorganics: The model performed poorly on inorganic (14% accuracy) and organometallic compounds (20% accuracy). This is attributed to inherent data limitations in the standard InChI format (which deliberately disconnects metal atoms from their ligands) and low training data coverage for those classes.
- Character-Level Superiority: Character-level tokenization was found to be essential; byte-pair encoding reduced accuracy significantly.
Reproducibility Details
Data
The dataset was derived from PubChem’s public FTP server (CID-SMILES.gz and CID-IUPAC.gz).
| Purpose | Dataset | Size | Notes |
|---|---|---|---|
| Raw | PubChem | 100M pairs | Filtered for length (InChI < 200 chars, IUPAC < 150 chars). 132k unparseable SMILES dropped. |
| Training | Subsampled | 10M pairs | Random sample from the filtered set. |
| Validation | Held-out | 10,000 samples | Limited to InChI length > 50 chars. |
| Test | Held-out | 200,000 samples | Limited to InChI length > 50 chars. |
| Tokenization | Vocab | InChI: 66 chars IUPAC: 70 chars | Character-level tokenization. Spaces treated as tokens. |
Algorithms
- Framework: OpenNMT-py 2.0.0 (using PyTorch). Training scripts and vocabularies are available as supplementary files to the original publication. Pre-trained model weights are hosted on Zenodo.
- Architecture Type: Transformer Encoder-Decoder.
- Optimization: ADAM optimizer ($\beta_1=0.9, \beta_2=0.998$).
- Learning Rate: Linear warmup over 8000 steps to 0.0005, then decayed by inverse square root of iteration.
- Regularization:
- Dropout: 0.1 (applied to dense and attentional layers).
- Label Smoothing: Magnitude 0.1.
- Training Strategy: Teacher forcing used for both training and validation.
- Gradient Accumulation: Gradients accumulated over 4 batches before updating parameters.
- Inference: Beam search with width 10 and length penalty 1.0.
Models
- Structure: 6 layers in encoder, 6 layers in decoder.
- Attention: 8 heads per attention sub-layer.
- Dimensions:
- Feed-forward hidden state size: 2048.
- Embedding vector length: 512.
- Initialization: Glorot’s method.
- Position: Positional encoding added to word vectors.
Evaluation
Metrics reported include Whole-Name Accuracy (percentage of exact matches) and Normalized Edit Distance (Damerau-Levenshtein, scale 0-1).
| Metric | Value | Baseline | Notes |
|---|---|---|---|
| Accuracy (All) | 91% | N/A | Test set of 200k samples. |
| Accuracy (Inorganic) | 14% | N/A | Limited by InChI format and data. |
| Accuracy (Organometallic) | 20% | N/A | Limited by InChI format and data. |
| Accuracy (Charged) | 79% | N/A | Test set subset. |
| Accuracy (Rajan) | 72% | N/A | Comparative ML model (STOUT). |
| Edit Dist (Organic) | $0.02 \pm 0.03$ | N/A | Very high similarity for organics. |
| Edit Dist (Inorganic) | $0.32 \pm 0.20$ | N/A | Poor performance on inorganics. |
| Edit Dist (Organometallic) | $0.37 \pm 0.24$ | N/A | Poor performance on organometallics. |
Hardware
- GPU: Tesla K80.
- Training Time: 7 days.
- Throughput: ~6000 tokens/sec (InChI) and ~3800 tokens/sec (IUPAC).
- Batch Size: 4096 tokens (approx. 30 compounds).
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| InChI to IUPAC model | Model | CC BY 4.0 | Pre-trained Transformer weights (551 MB), requires OpenNMT-py 2.0.0 |
| PubChem FTP | Dataset | Public Domain | Source data: CID-SMILES.gz and CID-IUPAC.gz |
| Training scripts & vocabularies | Code | Unknown | Included as supplementary files with the publication |
Paper Information
Citation: Handsel, J., Matthews, B., Knight, N. J., & Coles, S. J. (2021). Translating the InChI: Adapting Neural Machine Translation to Predict IUPAC Names from a Chemical Identifier. Journal of Cheminformatics, 13(1), 79. https://doi.org/10.1186/s13321-021-00535-x
Publication: Journal of Cheminformatics 2021
@article{handselTranslatingInChIAdapting2021a,
title = {Translating the {{InChI}}: Adapting Neural Machine Translation to Predict {{IUPAC}} Names from a Chemical Identifier},
shorttitle = {Translating the {{InChI}}},
author = {Handsel, Jennifer and Matthews, Brian and Knight, Nicola J. and Coles, Simon J.},
year = 2021,
month = oct,
journal = {Journal of Cheminformatics},
volume = {13},
number = {1},
pages = {79},
issn = {1758-2946},
doi = {10.1186/s13321-021-00535-x},
urldate = {2025-12-20},
abstract = {We present a sequence-to-sequence machine learning model for predicting the IUPAC name of a chemical from its standard International Chemical Identifier (InChI). The model uses two stacks of transformers in an encoder-decoder architecture, a setup similar to the neural networks used in state-of-the-art machine translation. Unlike neural machine translation, which usually tokenizes input and output into words or sub-words, our model processes the InChI and predicts the IUPAC name character by character. The model was trained on a dataset of 10 million InChI/IUPAC name pairs freely downloaded from the National Library of Medicine's online PubChem service. Training took seven days on a Tesla K80 GPU, and the model achieved a test set accuracy of 91\%. The model performed particularly well on organics, with the exception of macrocycles, and was comparable to commercial IUPAC name generation software. The predictions were less accurate for inorganic and organometallic compounds. This can be explained by inherent limitations of standard InChI for representing inorganics, as well as low coverage in the training data.},
langid = {english},
keywords = {Attention,GPU,InChI,IUPAC,seq2seq,Transformer}
}