Paper Classification: Method and Resource
This paper is a combination of Method (primary) and Resource (secondary).
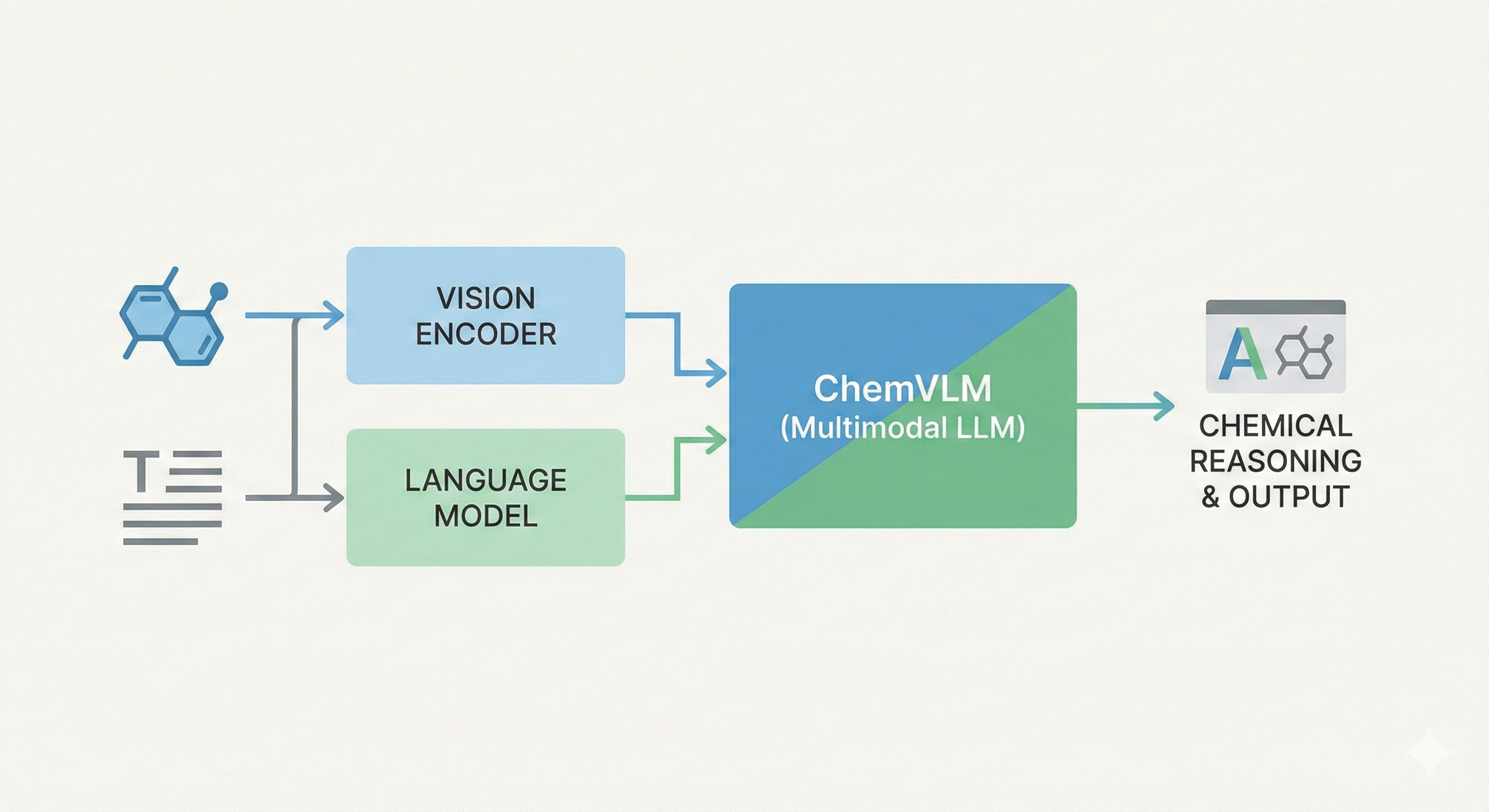
It is primarily a Method paper because it proposes ChemVLM, a novel multimodal architecture specifically tailored for the chemical domain, utilizing a “ViT-MLP-LLM” framework. The authors introduce a specific two-stage training strategy to align visual features with chemical text representations.
Secondarily, it is a Resource paper as it introduces a comprehensive suite of three new datasets: ChemOCR, MMCR-Bench, and MMChemBench, developed to rigorously evaluate multimodal capabilities in chemistry, covering OCR, reasoning, and property prediction.
Bridging the Visual Gap in Chemical LLMs
The primary motivation is the limitation of existing models in handling the multimodal nature of chemistry.
- Visual Data Gap: Chemical tasks heavily rely on visual information (molecular structures, reactions) which purely text-based chemical LLMs cannot process.
- Limitations of Generalist Models: General multimodal models (like GPT-4V or LLaVA) lack specialized chemical domain knowledge, leading to hallucinations or misinterpretations.
- Inadequacy of OCR Tools: Traditional chemical OCR tools (like MolScribe) excel at modality conversion (Image-to-SMILES) but fail at complex reasoning tasks.
Domain-Specific Data Curation and Benchmarking
- Data-Driven Alignment: The underlying “ViT-MLP-LLM” framework is standard in multimodal modeling, paralleling architectures like LLaVA. The core innovation here is the rigorous creation of a bilingual multimodal dataset spanning hand-drawn molecules, reactions, and exam questions augmented with style transfers. The training data pipeline heavily relies on generating synthetic variance using tools like RanDepict and RDKit to introduce distortions, rotations, and handwritten styles, alongside GPT-4 generated prompts to ensure linguistic diversity.
- Model Integration: ChemVLM merges InternViT-6B (a large-scale vision transformer) with ChemLLM-20B (a chemical language model). Visual features $X_v$ are mapped into the linguistic embedding space via an MLP projector, producing aligned token sequences alongside text instructions $X_q$. The joint multimodal sequence is trained using standard autoregressive next-token prediction: $$ \mathcal{L} = -\sum_{i} \log P(y_i \mid X_v, X_q, y_{<i}) $$
- Three Custom Benchmarks: The authors introduce tailored benchmarks to assess distinct competencies:
- ChemOCR: For image-to-SMILES conversion.
- MMCR-Bench: College entrance exam questions testing complex logical reasoning.
- MMChemBench: For molecule captioning and zero-shot property prediction.
Evaluating Chemical OCR and Reasoning
The authors benchmarked ChemVLM against both open-source (LLaVA, Qwen-VL, InternVL) and proprietary (GPT-4V) models across three primary domains:
- Chemical OCR: Evaluated on 1,000 image-text pairs from ChemOCR. The primary metric is the Tanimoto similarity between the Morgan fingerprints of the generated structure ($A$) and the ground-truth SMILES ($B$):
$$ T(A, B) = \frac{|A \cap B|}{|A| + |B| - |A \cap B|} $$
They report both the average Tanimoto similarity and the strict exact-match rate (
[email protected]). - Multimodal Chemical Reasoning (MMCR): Tested on MMCR-Bench (1,000 exam questions), ScienceQA, and CMMU. Performance was scored based on accuracy for multiple-choice and fill-in-the-blank questions.
- Multimodal Molecule Understanding: Evaluated on MMChemBench for molecule captioning and property prediction.
- Text-Only Reasoning: Tested on SciBench, a text-only benchmark for university-level science, to ensure the model retains fundamental linguistic reasoning.
- Generalization: Tested on non-chemistry subjects within the CMMU framework (Biology, Physics, Math) to assess cross-domain competence.
Performance Gains and Existing Limitations
- Multimodal Reasoning Leadership: ChemVLM achieved state-of-the-art results on MMCR-Bench (41.7%), surpassing generalist models like GPT-4V (40.1%). However, scoring for portions of these benchmarks relied heavily on an LLM-as-a-judge (the Qwen-max API), which can introduce bias as LLM evaluators often favor structural characteristics and verbosity produced by similar autoregressive models. Furthermore, the model was fine-tuned on 200,000 exam questions and tested on MMCR-Bench (also derived from Chinese college entrance exams). While the authors state the data was deduplicated, the potential for data leakage remains a significant unaddressed confounder.
- Superior Understanding: In molecule captioning and prediction, ChemVLM showed significant improvements over general baseline models, scoring 80.9% on prediction compared to GPT-4V’s 38.6%. This is a natural consequence of testing a custom-trained model on domain-specific benchmarks.
- OCR Capabilities vs. Dedicated Tools: ChemVLM outperformed generalist MLLMs in chemical structure recognition, achieving an average Tanimoto similarity of 71.0% (vs. GPT-4V’s 15.0%). However, it remains significantly inferior to pure structural OCR tools like MolScribe in strict modality conversion tasks, only achieving an exact structural match (
[email protected]) of 42.9% compared to MolScribe’s 89.1%. - Textual Retention and Generalization Claims: The authors claim the diverse training strategy imparts broad scientific reasoning, pointing to performance retention on non-chemistry subjects (Biology, Physics, Math) and strong results on the purely textual SciBench benchmark. However, this cross-domain generalization highly likely stems from the underlying base model (ChemLLM-20B/InternLM2) or the inclusion of 1.3 million “General” visual QA pairs in their training blend, rather than emergent general scientific skills originating purely from learning chemistry representations.
Reproducibility Details
Data
The training and evaluation data relied on a mix of open-source repositories and custom curation. Many of the curated datasets have been formally released by the authors on Hugging Face (di-zhang-fdu/chemvlm-sft-datasets).
| Purpose | Dataset | Source/Notes |
|---|---|---|
| Training (Molecule) | DECIMER HDM | 7,000+ hand-drawn molecular images. |
| Training (Molecule) | MolScribe Data | Scanned/photographed images from literature. |
| Training (Molecule) | Synthetic | Generated via ChemDraw, RDKit, and Indigo with style transfer (blurring, rotation, handwritten styles). |
| Training (Reaction) | PEACE & USPTO-50K | Inorganic and organic reaction schemes. |
| Training (Reasoning) | Exam Questions | 200,000 questions from OpenDataLab (Chinese education level). Available on Hugging Face. |
| Evaluation | ChemOCR | 1,000 bilingual image-text pairs for SMILES recognition. Released via Google Drive link in repo. |
| Evaluation | MMCR-Bench | 1,000 multimodal chemistry exam questions. Requires emailing authors directly for access. |
| Evaluation | MMChemBench | Extension of ChemBench for captioning and property prediction. Released via Google Drive link in repo. |
Preprocessing: Images were augmented using RanDepict for style variation. Text data (SMILES) was validated and cleaned. Prompts were diversified using GPT-4 to generate different linguistic styles.
Algorithms
- Architecture: “ViT-MLP-LLM” structure.
- Vision Encoder: InternViT-6B, processing images at $448 \times 448$ resolution. Images are segmented into tiles (max 12).
- Projector: Multi-Layer Perceptron (MLP) initialized randomly to map visual features to text embedding space.
- LLM: ChemLLM-20B, a domain-specific model.
- Training Strategy: Two-stage supervised fine-tuning.
- Modal Alignment: Freeze LLM and base Vision Encoder weights. Train only the randomly initialized MLP projector and LoRA layers (rank 32) of the Vision Encoder. Uses diverse multimodal data.
- Supervised Fine-Tuning (SFT): Keep LLM and Vision Encoder base weights frozen, but add LoRA (rank 16) to the LLM and retain LoRA (rank 32) on the Vision Encoder. The MLP projector is fully trained. Data includes specialized chemistry and general corpora.
- Optimization:
- Optimizer: AdamW
- Context Length: 2048 tokens
- Chat Template: InternLM2 dialogue schema
Models
- ChemVLM-26B: The primary model released. It combines the 6B parameter vision encoder and the 20B parameter language model. Weights are fully available at
AI4Chem/ChemVLM-26B-1-2. An 8B version is also available. - Baselines: Comparisons were made against GPT-4V, Qwen-VL-Chat, LLaVA-v1.5-13B, InternVL-v1.5, and Yi-VL-Plus.
Evaluation
Performance was measured across three distinct task types. Exact evaluation scripts have been released in the official repository.
| Metric | Task | Method |
|---|---|---|
| Tanimoto Similarity | ChemOCR | Comparison of generated SMILES vs. ground truth using RDKit. Reports Average Similarity and [email protected] (exact match). |
| Accuracy | MMCR (Reasoning) | +1 point for correct multiple-choice/fill-in-the-blank; 0 otherwise. Scored via Qwen-max API prompting. |
| Prediction Score | Property Prediction | Evaluated on MMChemBench subsets. |
Hardware
- Training Compute: Training utilized 16 NVIDIA A100 (80GB) GPUs.
- Configuration:
- Batch size: 4 (per GPU, resulting in an effective global batch size of 256)
- Gradient Accumulation: 4 iterations
- Precision: Deepspeed bfloat16 (bf16) with ZeRO-3 offloading strategy
- Framework: Training runs on the InternVL-v1.5 codebase rather than standalone scripts.
- Inference Compute: Evaluating the 26B model requires at least one 80GB A100 GPU (with Flash Attention + bfloat16). The 8B variant requires a GPU with at least 48GB of VRAM.
Artifacts
| Artifact | Type | License | Notes |
|---|---|---|---|
| ChemVLM-26B | Model | MIT | Original 26B model weights |
| ChemVLM-26B-1-2 | Model | Apache-2.0 | Updated 26B model weights |
| chemvlm-sft-datasets | Dataset | Unknown | SFT training data (~51.7k rows) |
| ChemVlm (GitHub) | Code | Unknown | Training, evaluation, and inference code |
Paper Information
Citation: Li, J., et al. (2025). ChemVLM: Exploring the Power of Multimodal Large Language Models in Chemistry Area. Proceedings of the AAAI Conference on Artificial Intelligence, 39(1), 415-423. https://doi.org/10.1609/aaai.v39i1.32020
Publication: AAAI 2025
@inproceedings{li2025chemvlm,
title={ChemVLM: Exploring the Power of Multimodal Large Language Models in Chemistry Area},
author={Li, Junxian and Zhang, Di and Wang, Xunzhi and Hao, Zeying and Lei, Jingdi and Tan, Qian and Zhou, Cai and Liu, Wei and Yang, Yaotian and Xiong, Xinrui and Wang, Weiyun and Chen, Zhe and Wang, Wenhai and Li, Wei and Su, Mao and Zhang, Shufei and Ouyang, Wanli and Li, Yuqiang and Zhou, Dongzhan},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={39},
number={1},
pages={415--423},
year={2025},
url={https://doi.org/10.1609/aaai.v39i1.32020},
doi={10.1609/aaai.v39i1.32020}
}
Additional Resources: