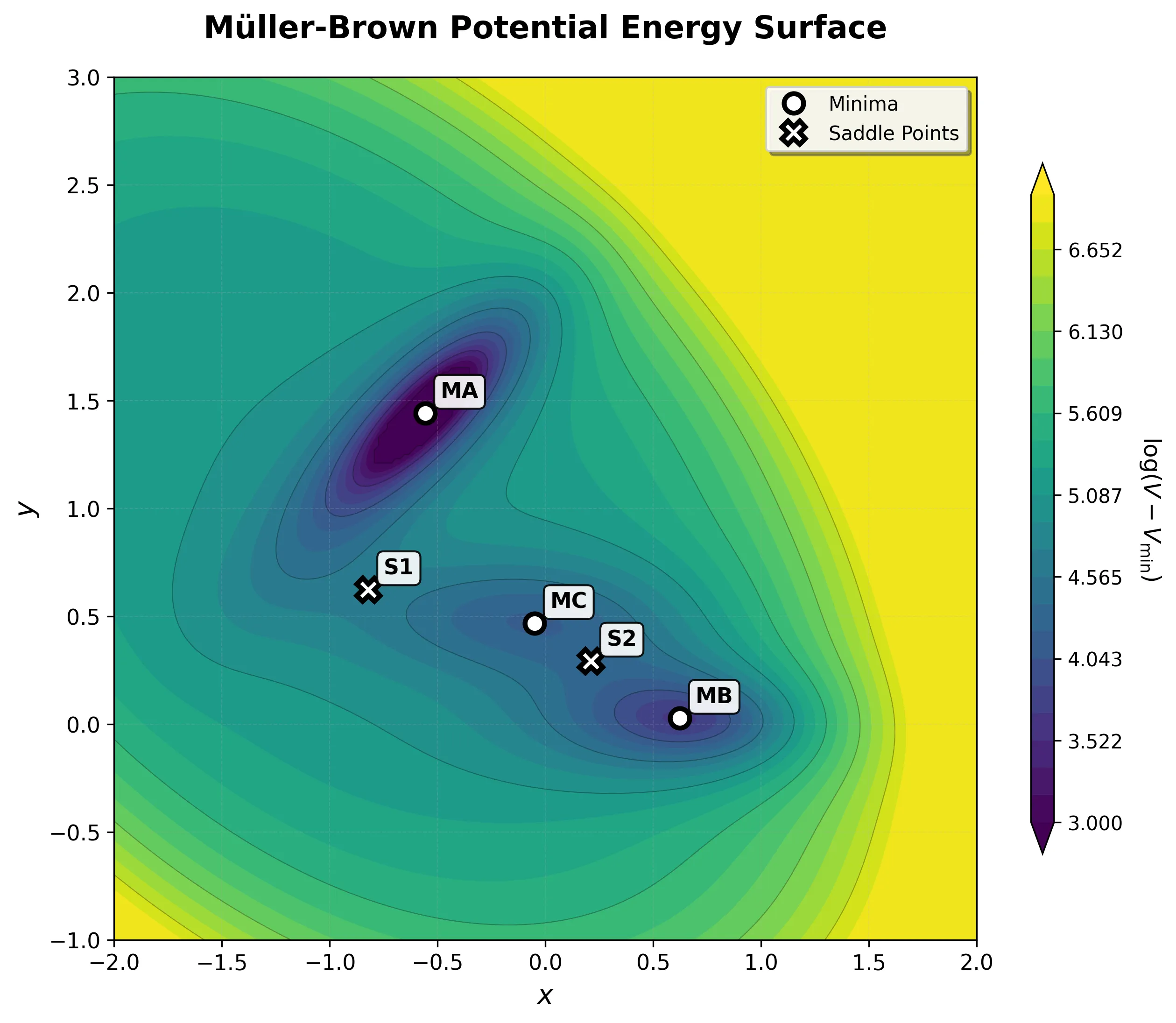
Progress in computational chemistry depends on shared, reproducible evaluation targets. This section collects notes on benchmark problems and datasets used to assess new methods, from classic analytical potential energy surfaces like the Muller-Brown surface to standardized generative modeling platforms like MOSES. These resources matter because they define what “better” means in practice, and understanding their design choices is essential for interpreting results reported in the literature.
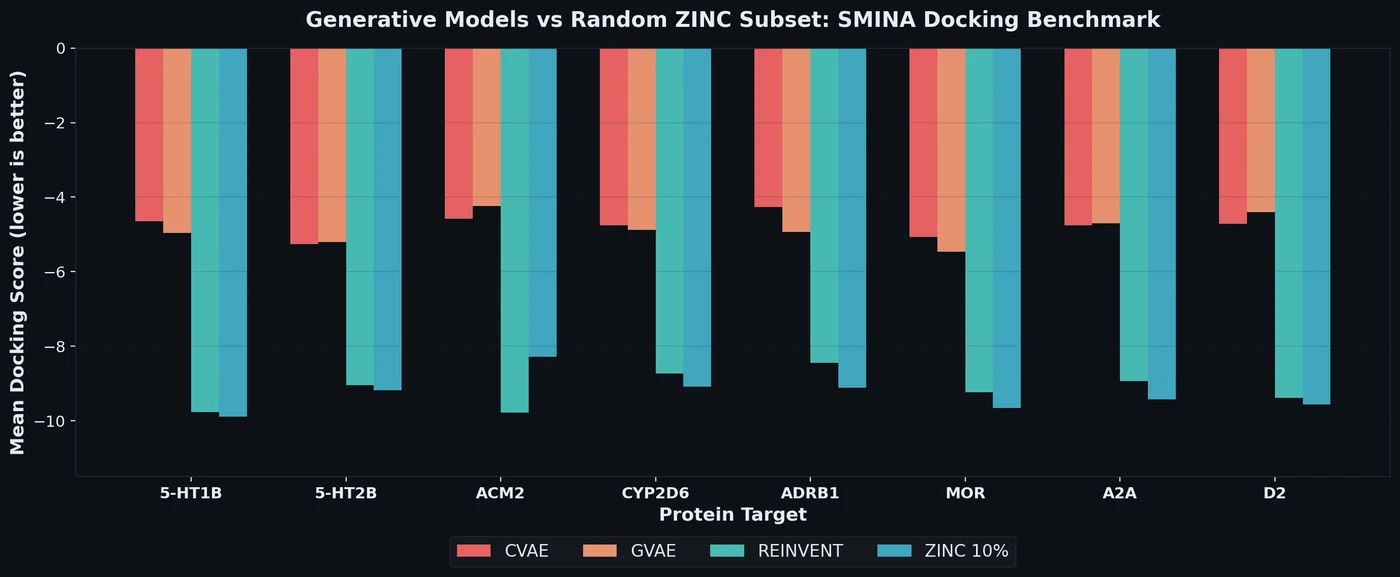
SMINA Docking Benchmark for De Novo Drug Design Models
Proposes a benchmark for de novo drug design using SMINA docking scores across eight drug targets, revealing that popular generative models fail to outperform random ZINC subsets.