Dataset cards covering large-scale molecular enumeration databases (GDB-11/13/17, ZINC-22) for virtual screening and drug discovery, and conformer ensemble datasets (GEOM, MARCEL) for molecular property prediction and 3D modeling.
| Year | Dataset | Key Idea |
|---|---|---|
| 2007 | GDB-11: Chemical Universe Database (26.4M Molecules) | Systematic enumeration of 26.4M small organic molecules up to 11 heavy atoms |
| 2009 | GDB-13: Chemical Universe Database (970M Molecules) | Extension to 970M molecules up to 13 heavy atoms |
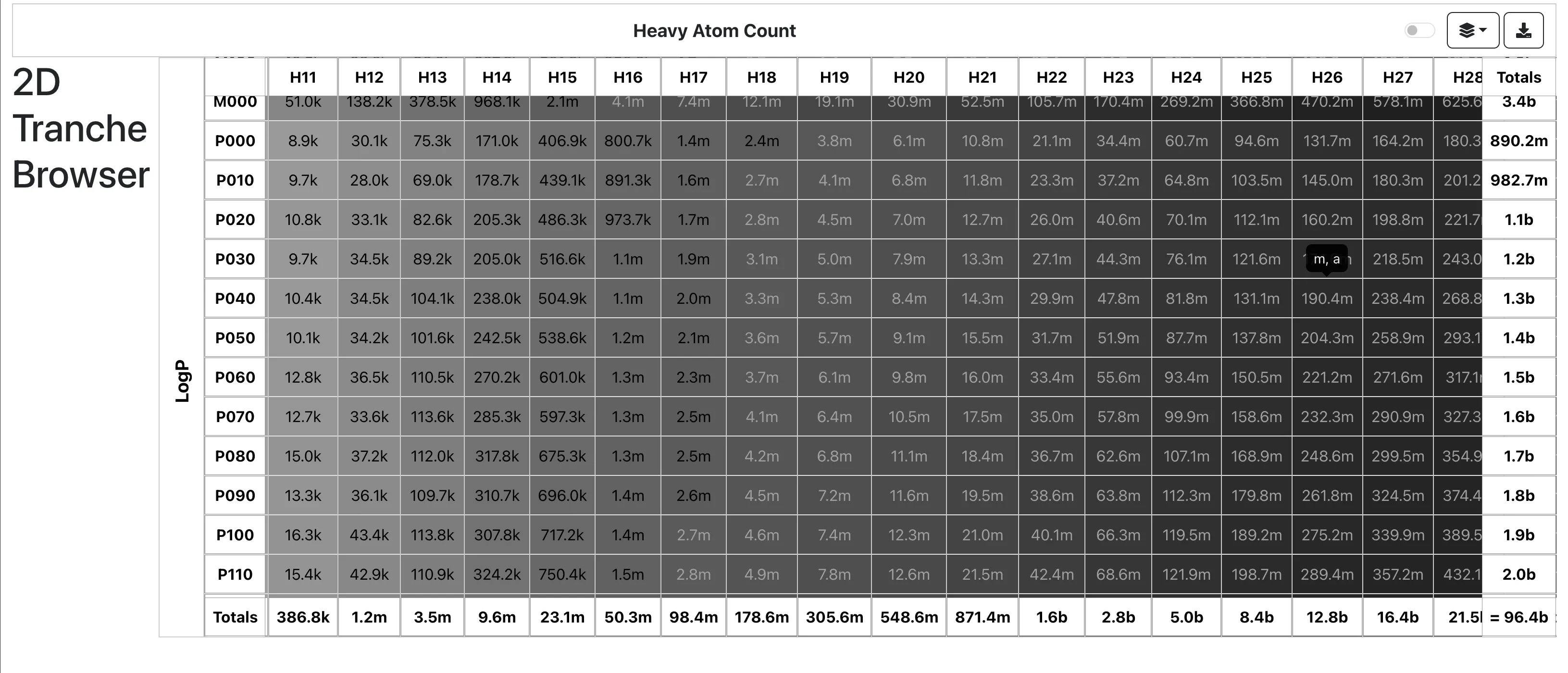
| 2012 | GDB-17: Chemical Universe Database (166.4B Molecules) | Largest enumeration database with 166.4B molecules up to 17 heavy atoms |
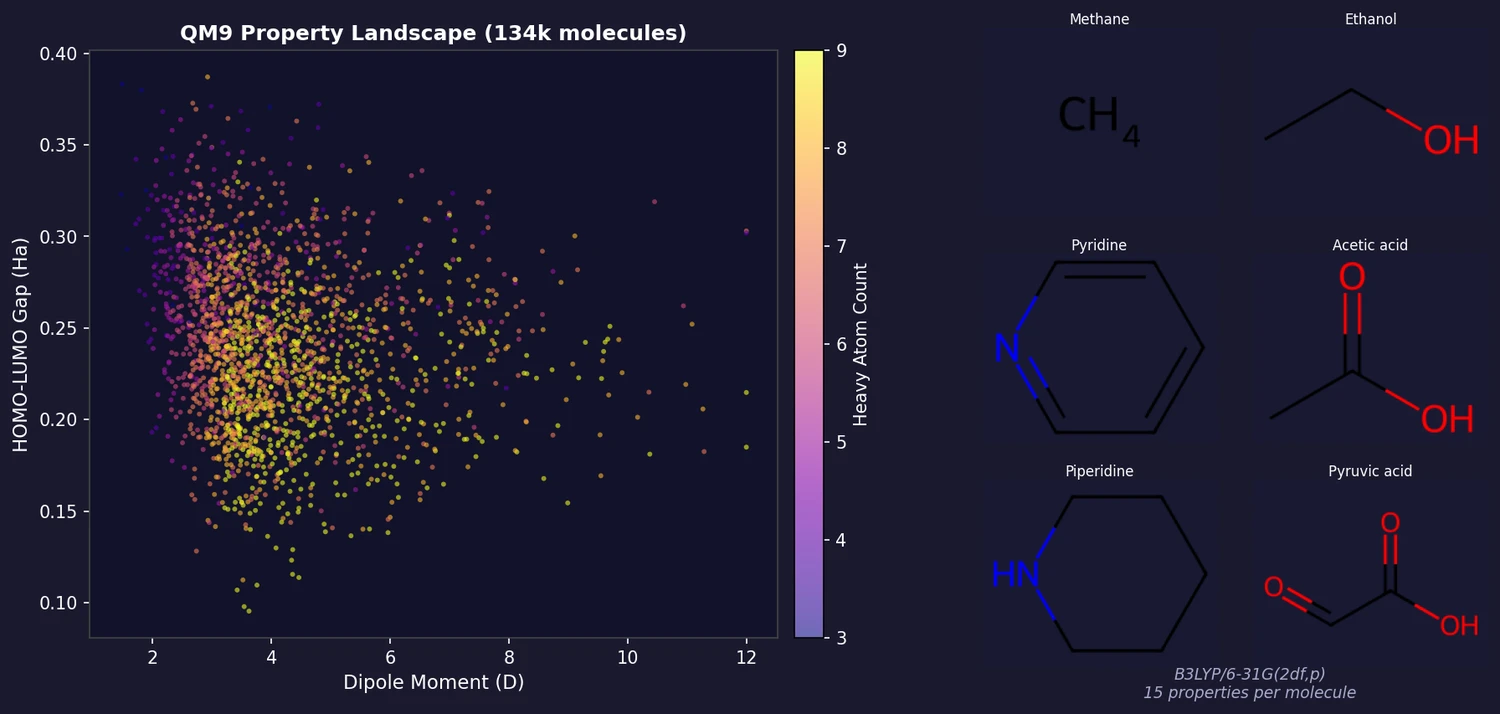
| 2014 | QM9: Quantum Chemistry Properties of 134k Molecules | DFT-computed properties for 134k small organic molecules from GDB-9 |
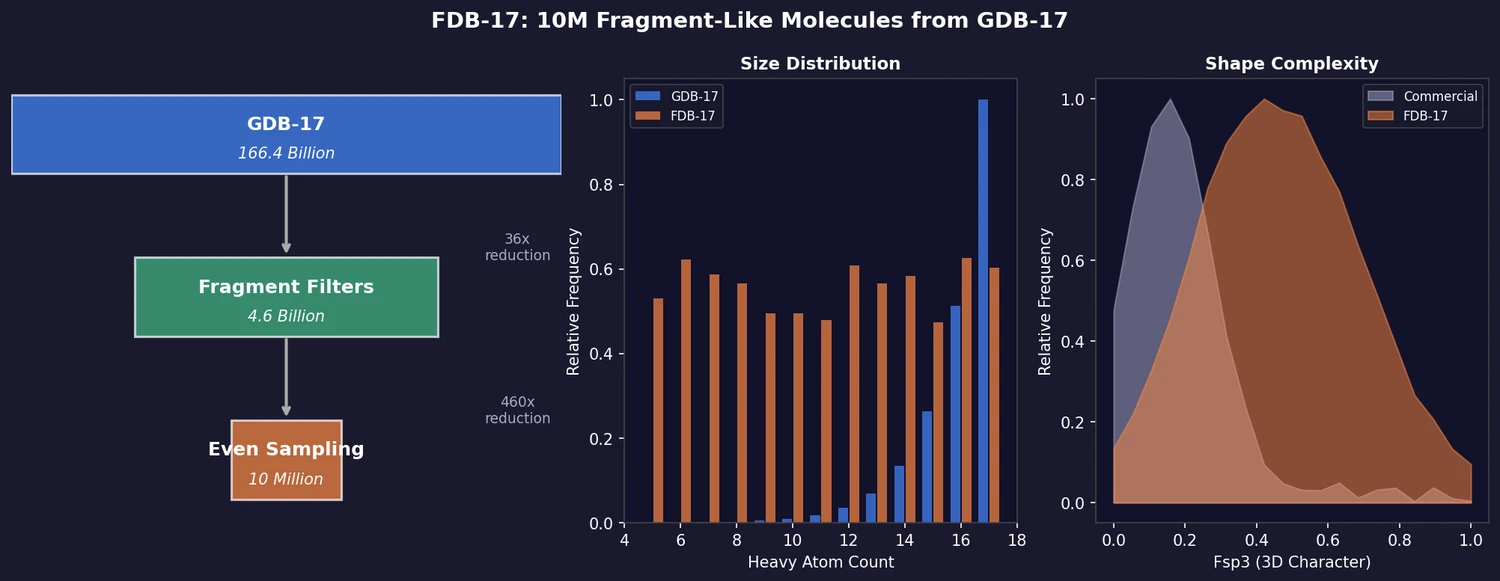
| 2017 | FDB-17: Fragment Database (10M Molecules) | 10M fragment-like molecules evenly sampled from GDB-17 across size, polarity, and complexity |
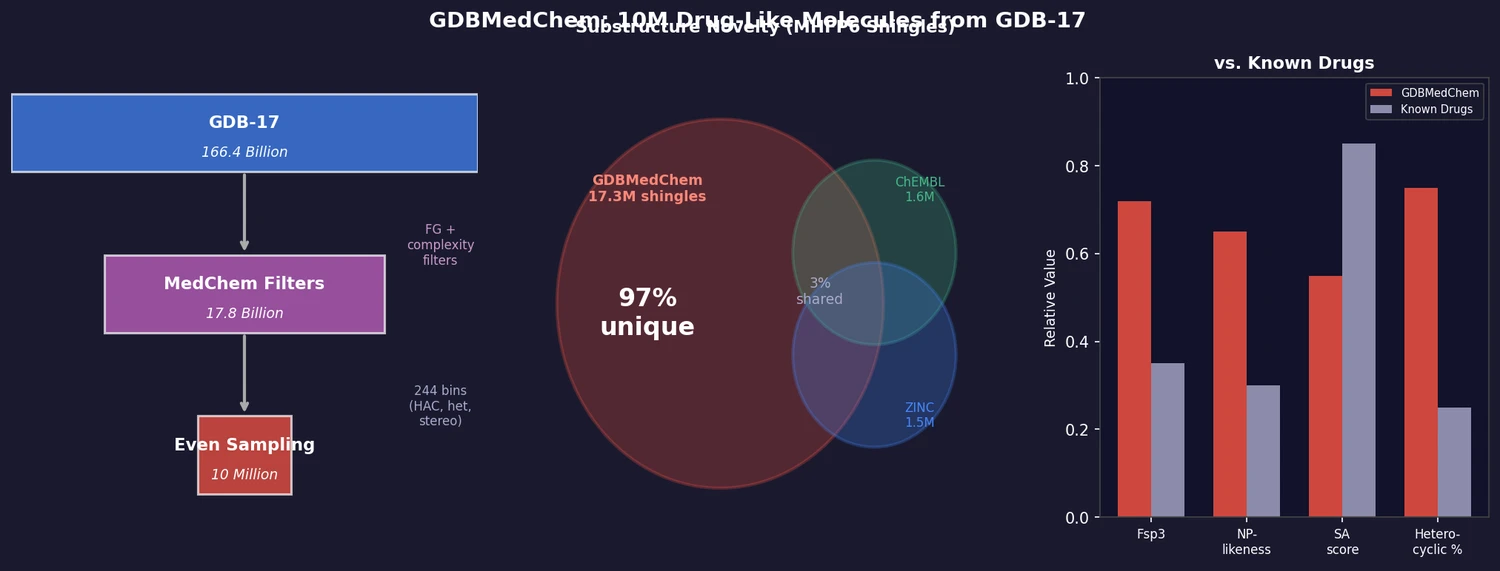
| 2019 | GDBMedChem: Drug-Like Subset of GDB-17 (10M Molecules) | 10M drug-like molecules from GDB-17 filtered by medicinal chemistry criteria, 97% novel substructures |
| 2022 | GEOM: Energy-Annotated Molecular Conformations Dataset | Energy-annotated molecular conformer ensembles for 3D modeling |
| 2023 | ZINC-22: A Multi-Billion Scale Database for Ligand Discovery | Over 37B make-on-demand molecules for virtual screening |
| 2024 | MARCEL: Molecular Conformer Ensemble Learning Benchmark | 722K+ conformers across 76K+ molecules for conformer ensemble learning |
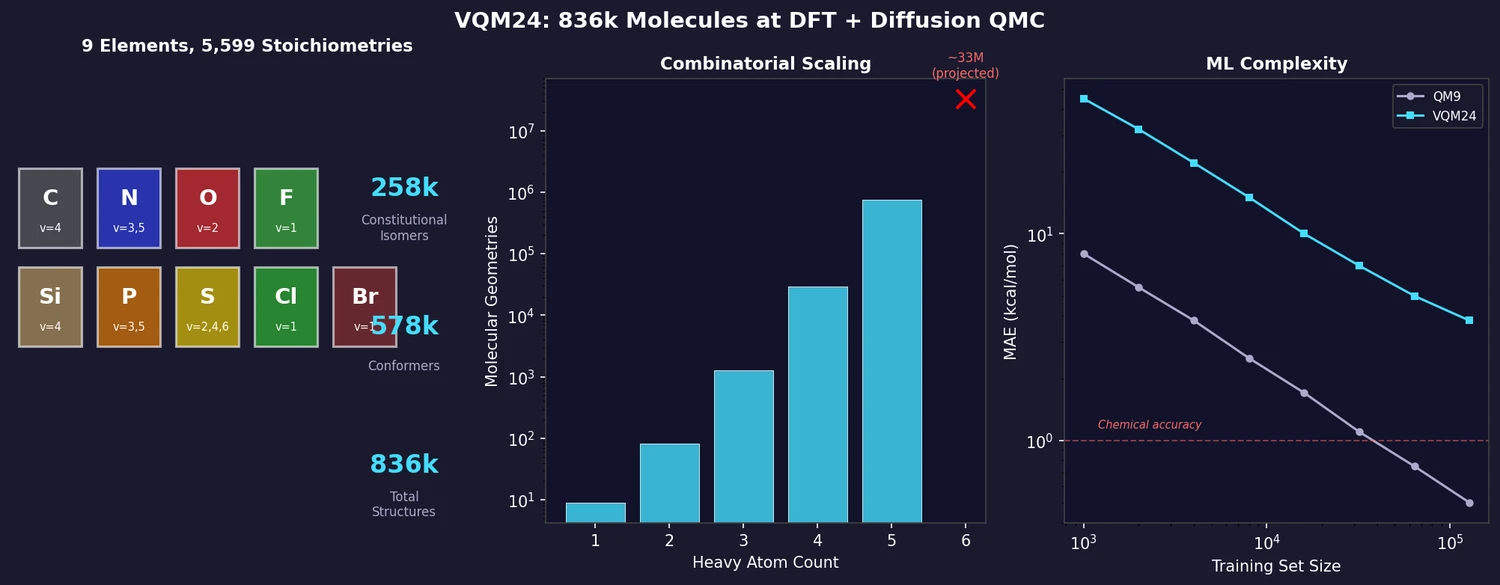
| 2025 | VQM24: 836k Molecules at DFT and Diffusion QMC | Exhaustive enumeration of 836k molecules (9 elements, up to 5 heavy atoms) with DFT and DMC properties |