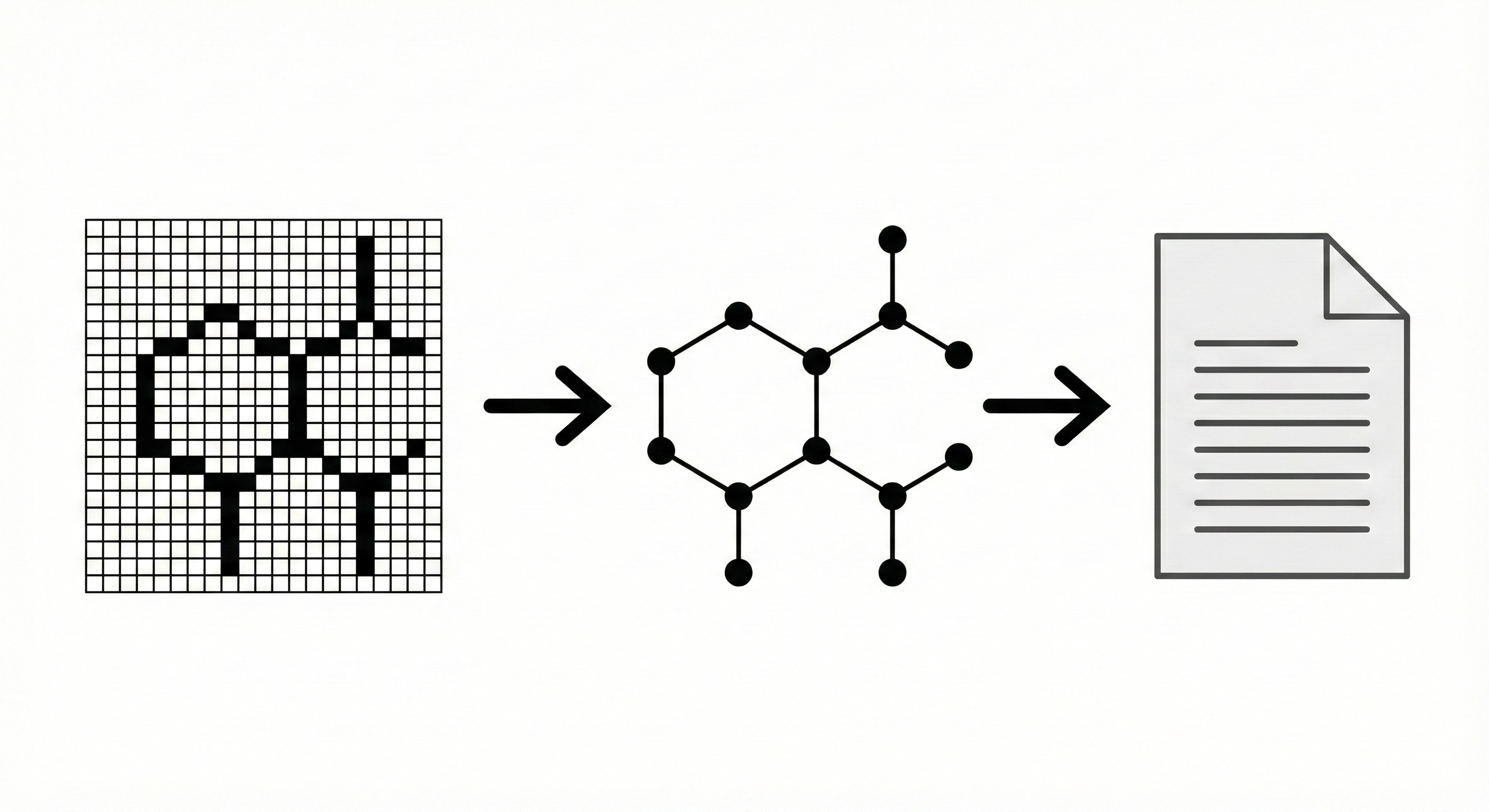
OCSR Methods: A Taxonomy of Approaches
A comprehensive categorization of OCSR methods, organizing techniques by their fundamental approach: deep learning, traditional ML, and rule-based systems.
A comprehensive categorization of OCSR methods, organizing techniques by their fundamental approach: deep learning, traditional ML, and rule-based systems.
This paper describes an early prototype system that digitizes chemical structure diagrams from scanned documents. It employs a multi-stage pipeline involving convex bounding polygon extraction, vectorization, and rule-based heuristics to generate MDL Molfiles.
This paper presents OSRA, the first open-source utility for converting graphical chemical structures from documents into machine-readable formats (SMILES/SD). It outlines a pipeline combining existing image processing tools with custom heuristics for bond and atom detection, establishing a foundation for accessible chemical information extraction.
This methodological paper proposes a comprehensive pipeline to digitize chemical structure images. It achieves 97% reconstruction accuracy on benchmarks by combining a topology-preserving vectorizer with a chemical knowledge validation module.
Performance evaluation of MolRec at the CLEF 2012 competition reveals a large performance gap between the automatic evaluation set (94-96% accuracy) and the manual evaluation set of complex patent structures (46-59% accuracy), with systematic analysis of failure modes including character grouping bugs, touching characters, and four-way junction vectorization.
Details the MolRec system for converting chemical diagram images into MOL files using vectorization, geometric rules, and graph construction. Achieved 95% accuracy on 1000 TREC 2011 benchmark images with comprehensive failure analysis of limitations.
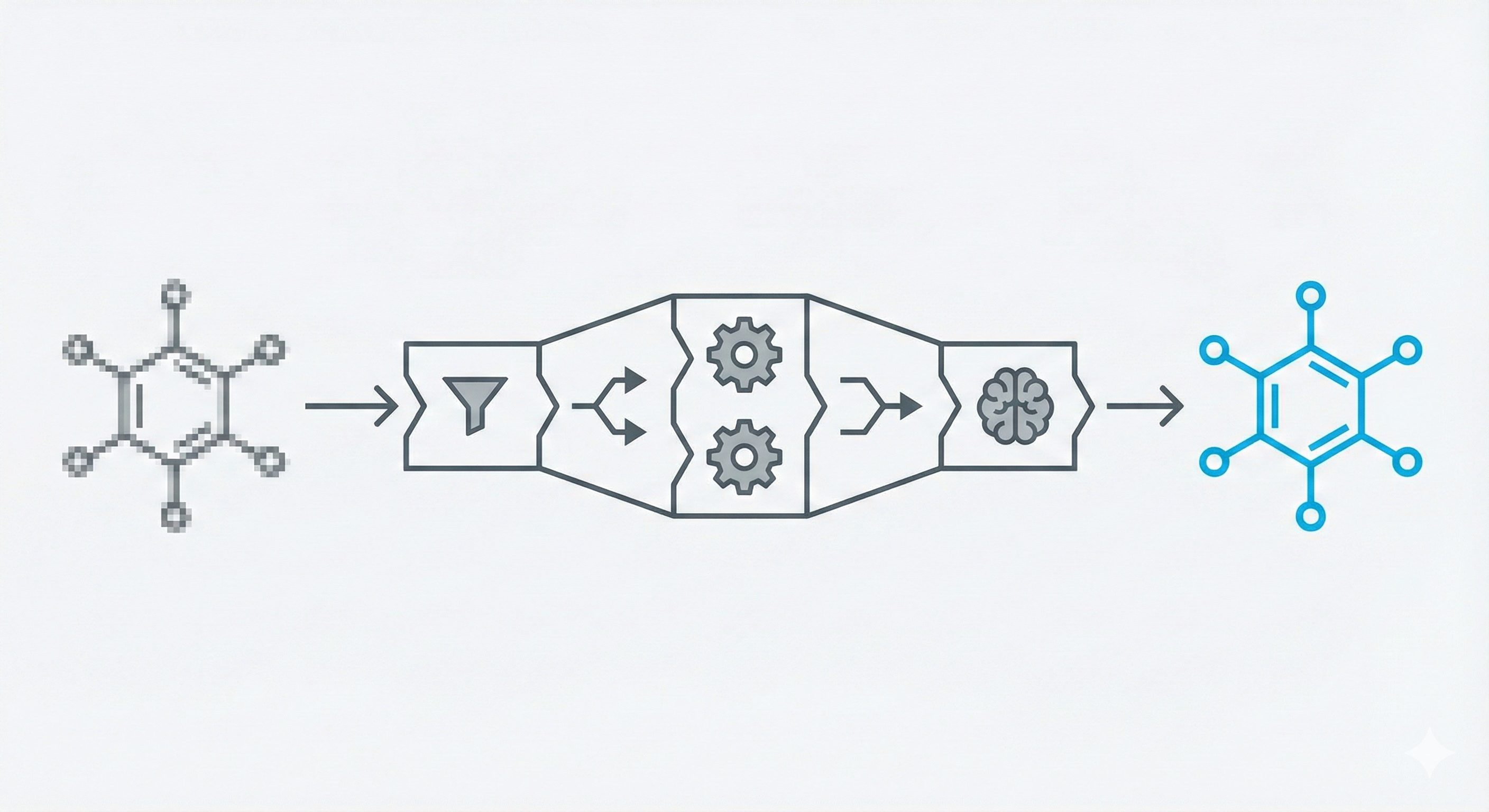
Discover how OCSR technology bridges the gap between molecular images and machine-readable data, evolving from rule-based systems to modern deep learning models for chemical knowledge extraction.
A 2024 deep learning system for optical chemical structure recognition designed specifically for biomedical literature mining, using ResNet-Transformer architecture to handle challenging conditions including low-resolution images, noise, distortions, and even hand-drawn molecular diagrams from scientific documents.
A 2011 rule-based OCSR system designed specifically for the challenging low-quality images in Japanese patent applications, using segment-based methods to handle pervasive problems like touching characters, merged atom labels with bonds, and broken lines.
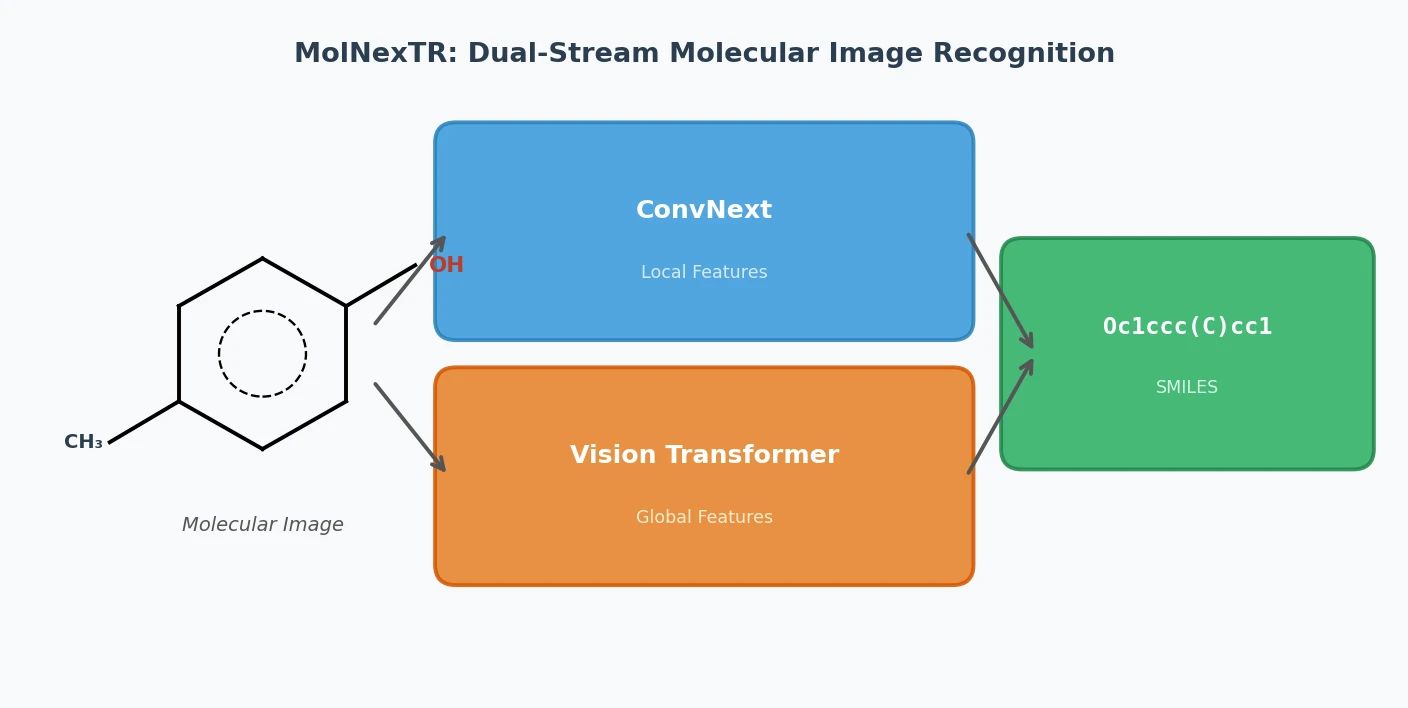
MolNexTR proposes a dual-stream architecture combining ConvNext and Vision Transformers to improve molecular image recognition (OCSR). It achieves 81-97% accuracy across diverse benchmarks utilizing simultaneous local and global feature extraction alongside specialized image contamination augmentations.
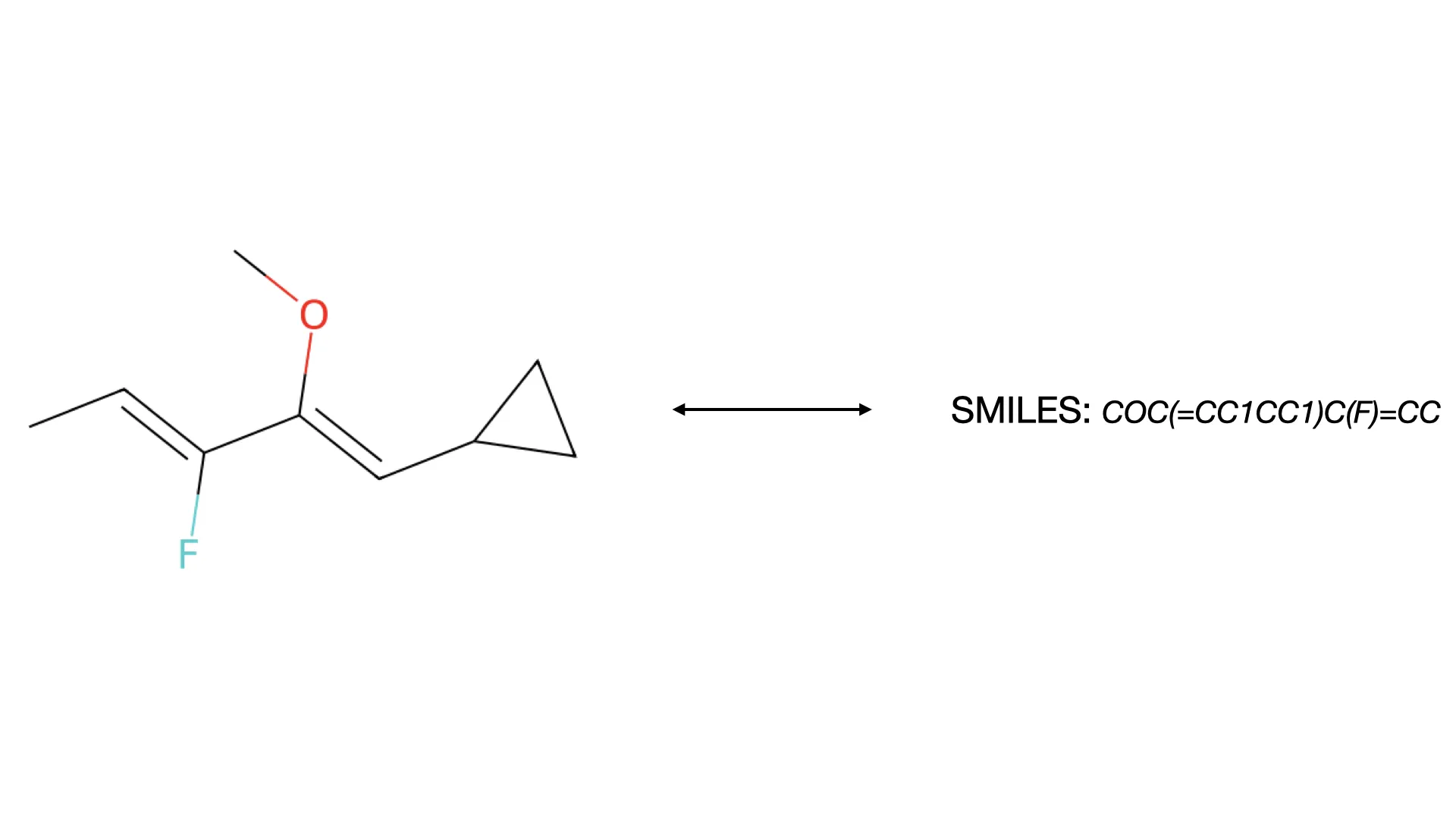
The MolParser project introduces two key datasets: MolParser-7M, the largest training dataset for Optical Chemical Structure Recognition (OCSR) with 7.7M pairs of images and E-SMILES strings, and WildMol, a new 20k-sample benchmark for evaluating models on challenging real-world data. The training data uniquely combines millions of diverse synthetic molecules with 400,000 manually annotated in-the-wild samples.
A 2025 end-to-end OCSR system addressing both technical and data challenges, introducing MolParser-7M (7M+ image-text pairs) and MolDet (YOLO-based detector) for extracting and recognizing molecular structures from real-world documents with diverse quality and styles.