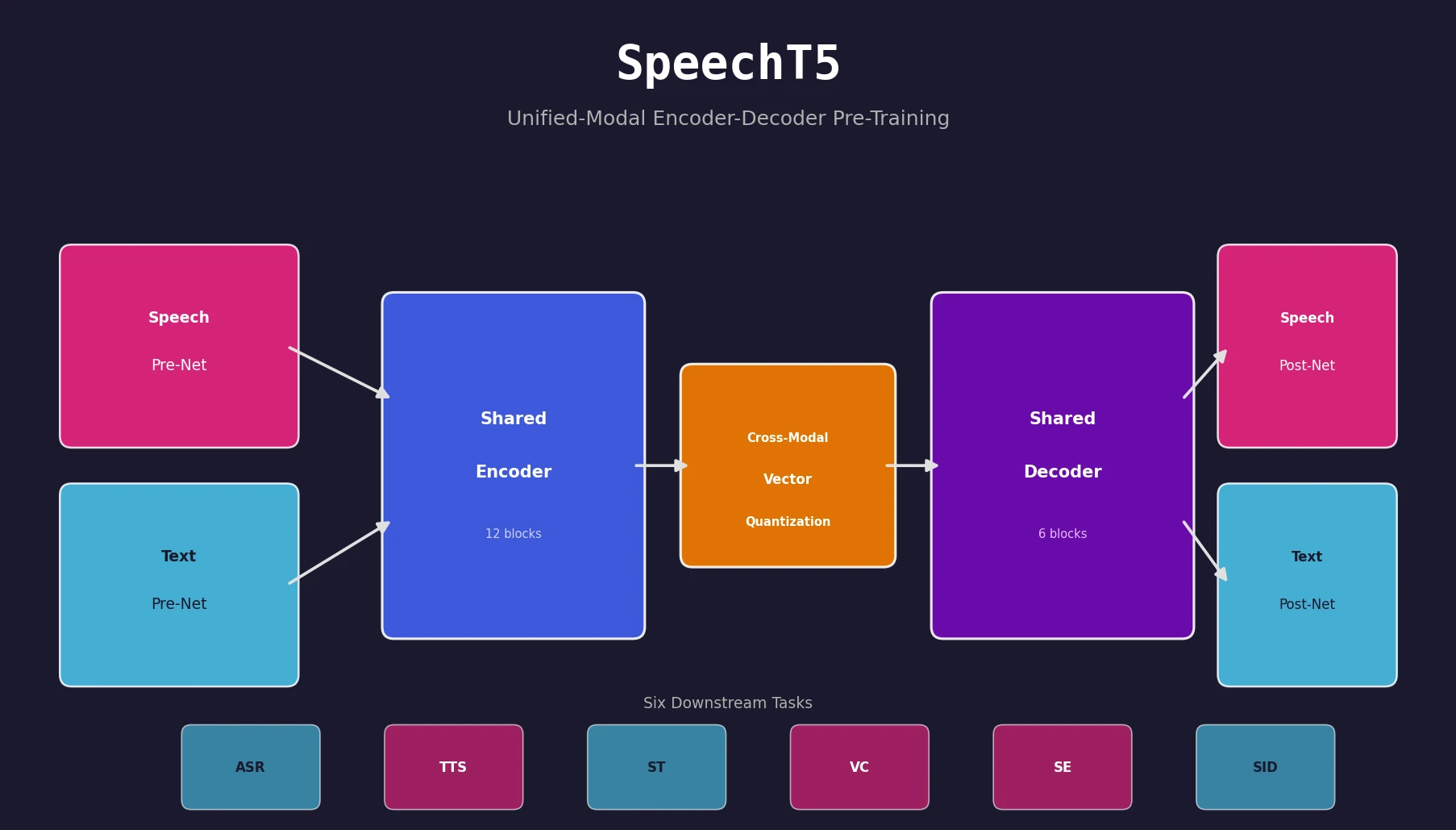
SpeechT5: Unified Speech-Text Pre-Training Framework
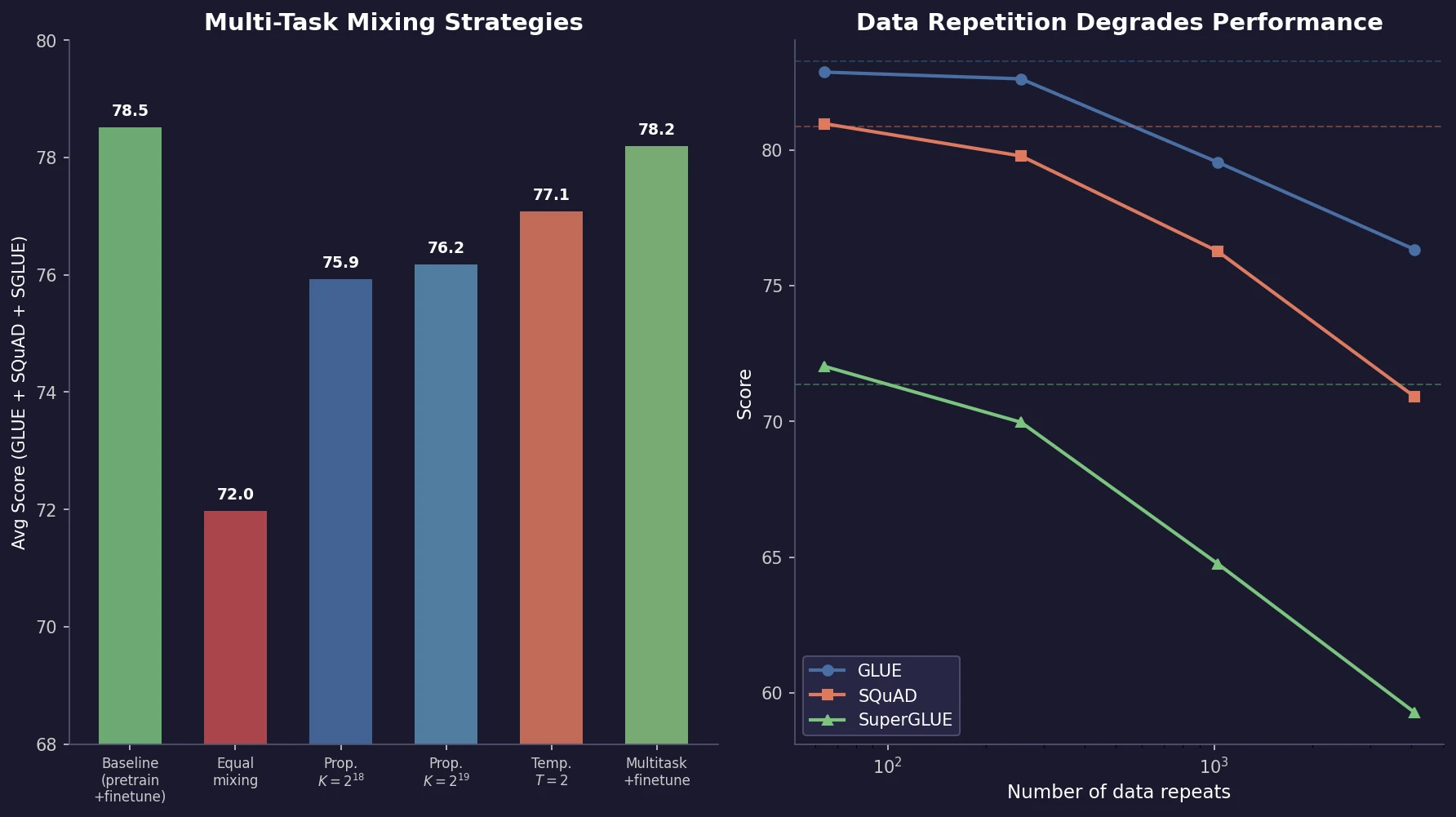
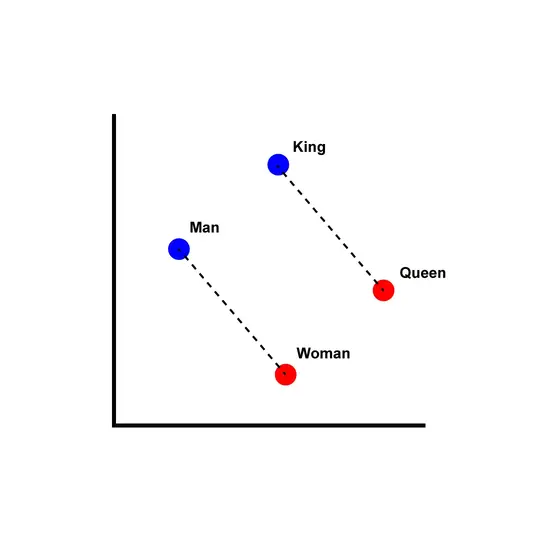
SpeechT5 proposes a unified encoder-decoder pre-training framework that jointly learns from unlabeled speech and text data, achieving strong results on ASR, TTS, speech translation, voice conversion, speech enhancement, and speaker identification.