High-Performance Word2Vec in Pure PyTorch
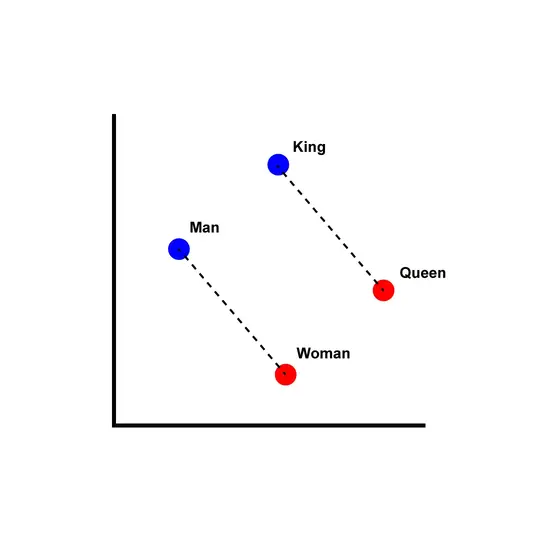
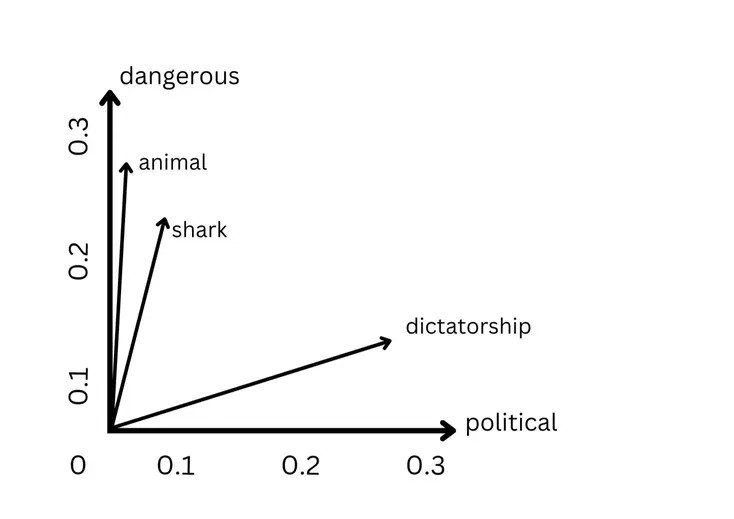
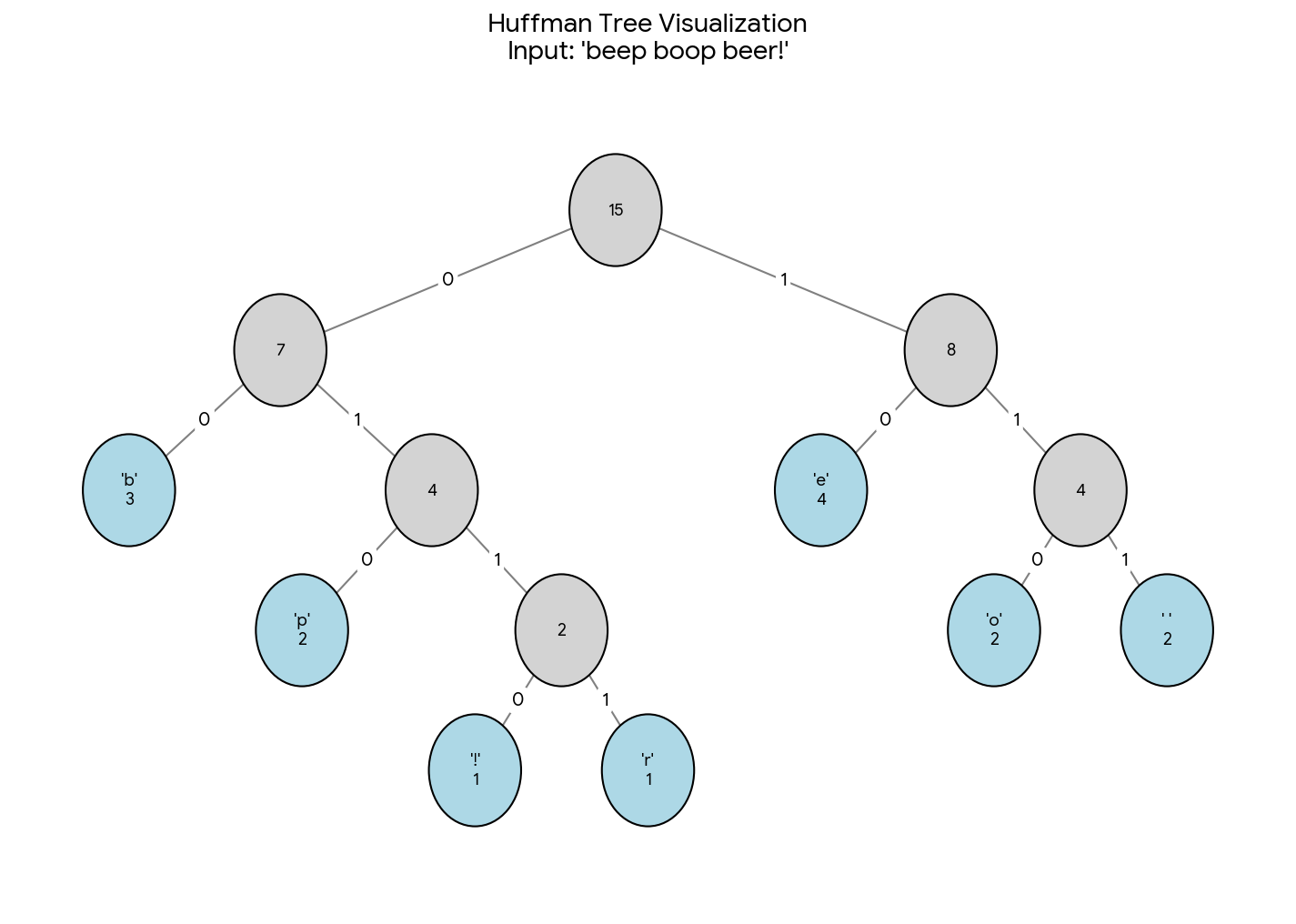
A ground-up PyTorch implementation of Word2Vec treating it as a systems engineering challenge, with “tensorized tree” architecture converting pointer-chasing Hierarchical Softmax into dense GPU operations, infinite streaming datasets with Zipfian subsampling, and torch.compile compatibility for production-grade efficiency.