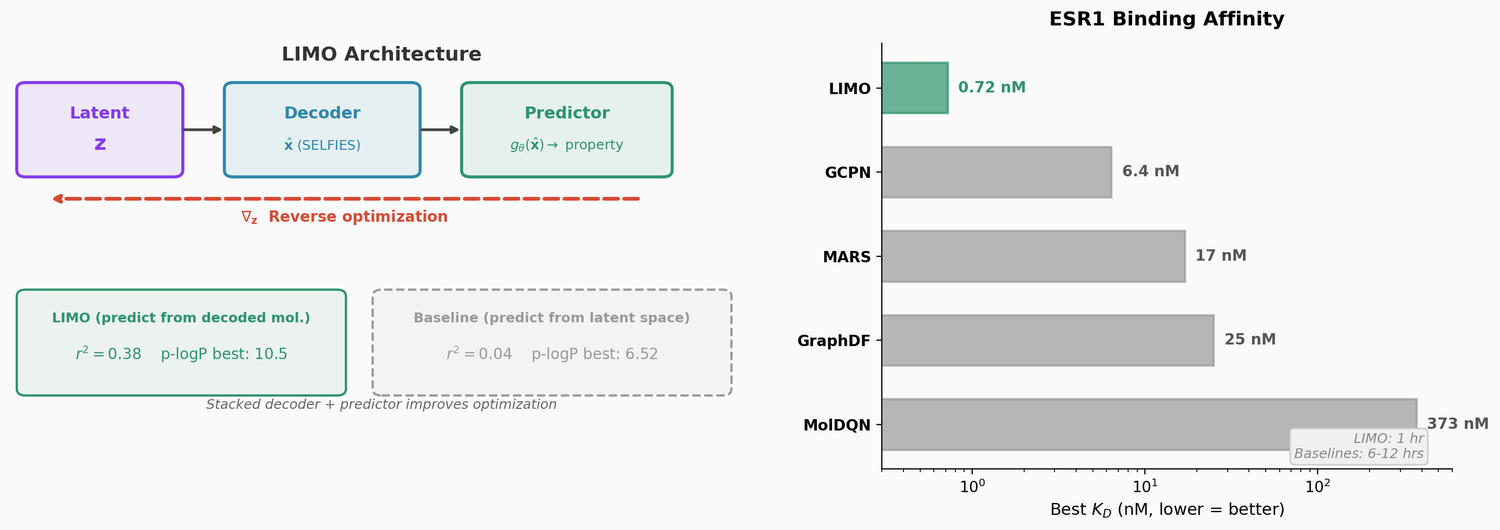
LIMO: Latent Inceptionism for Targeted Molecule Generation
LIMO combines a SELFIES-based VAE with a novel stacked property predictor architecture (decoder output as predictor input) and gradient-based reverse optimization on the latent space. It is 6-8x faster than RL baselines and 12x faster than sampling methods while generating molecules with nanomolar binding affinities, including a predicted KD of 6e-14 M against the human estrogen receptor.