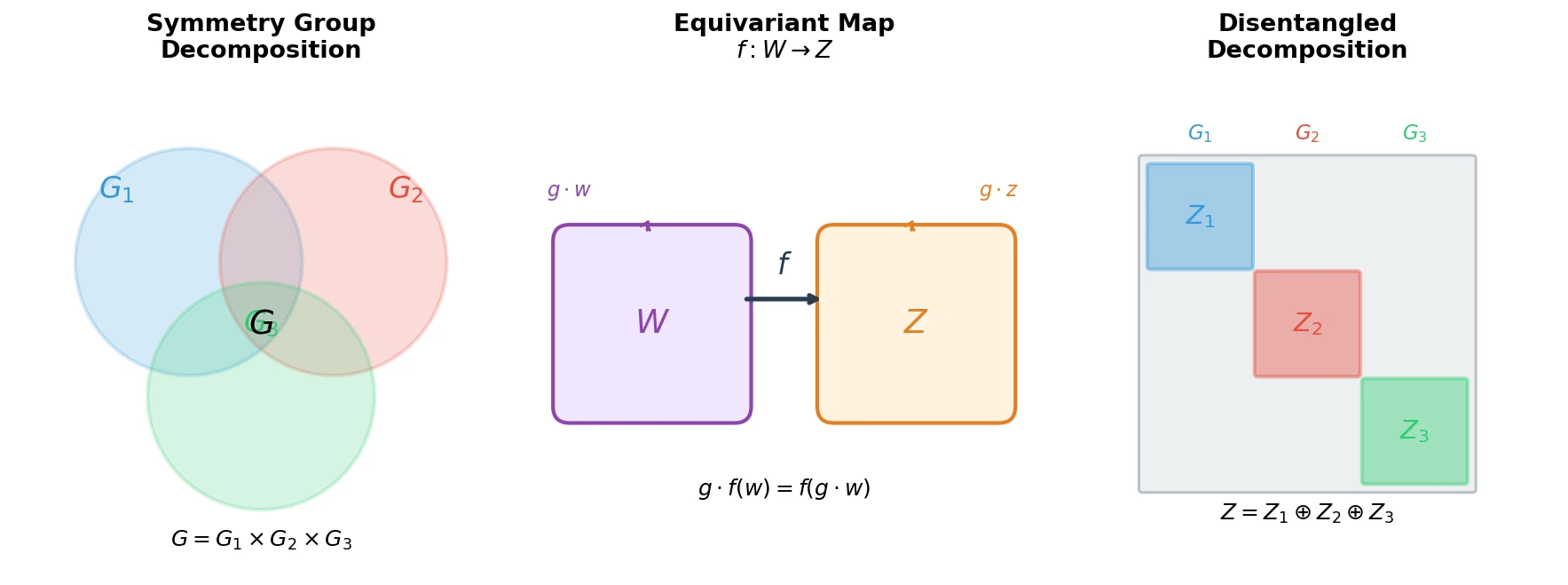
Defining Disentangled Representations via Group Theory
Proposes the first principled mathematical definition of disentangled representations by connecting symmetry group decompositions to independent subspaces in a representation’s vector space.
Proposes the first principled mathematical definition of disentangled representations by connecting symmetry group decompositions to independent subspaces in a representation’s vector space.
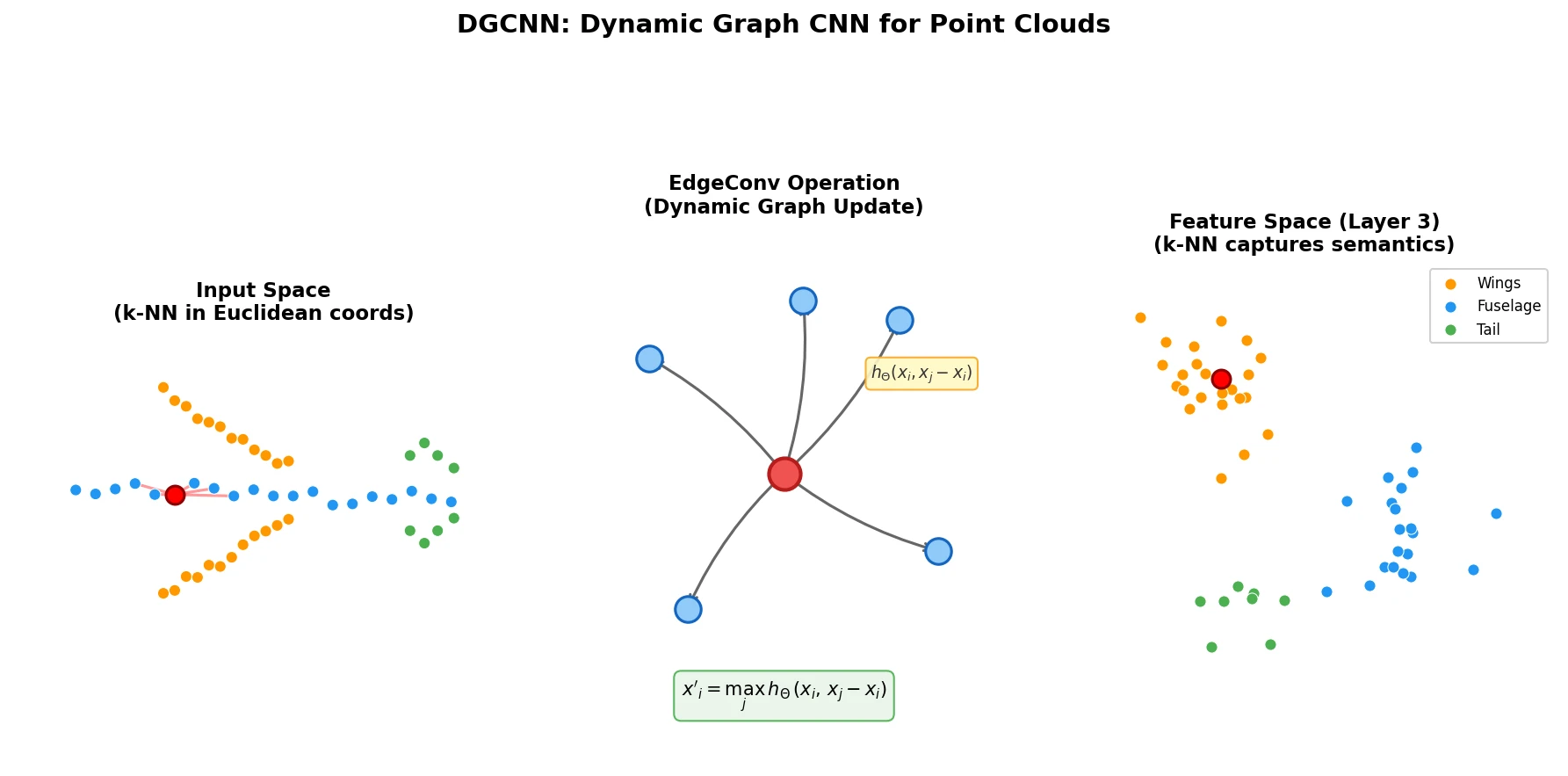
DGCNN introduces the EdgeConv operator, which constructs k-nearest neighbor graphs dynamically in feature space at each network layer. This enables the model to capture both local geometry and long-range semantic relationships for point cloud classification and segmentation.
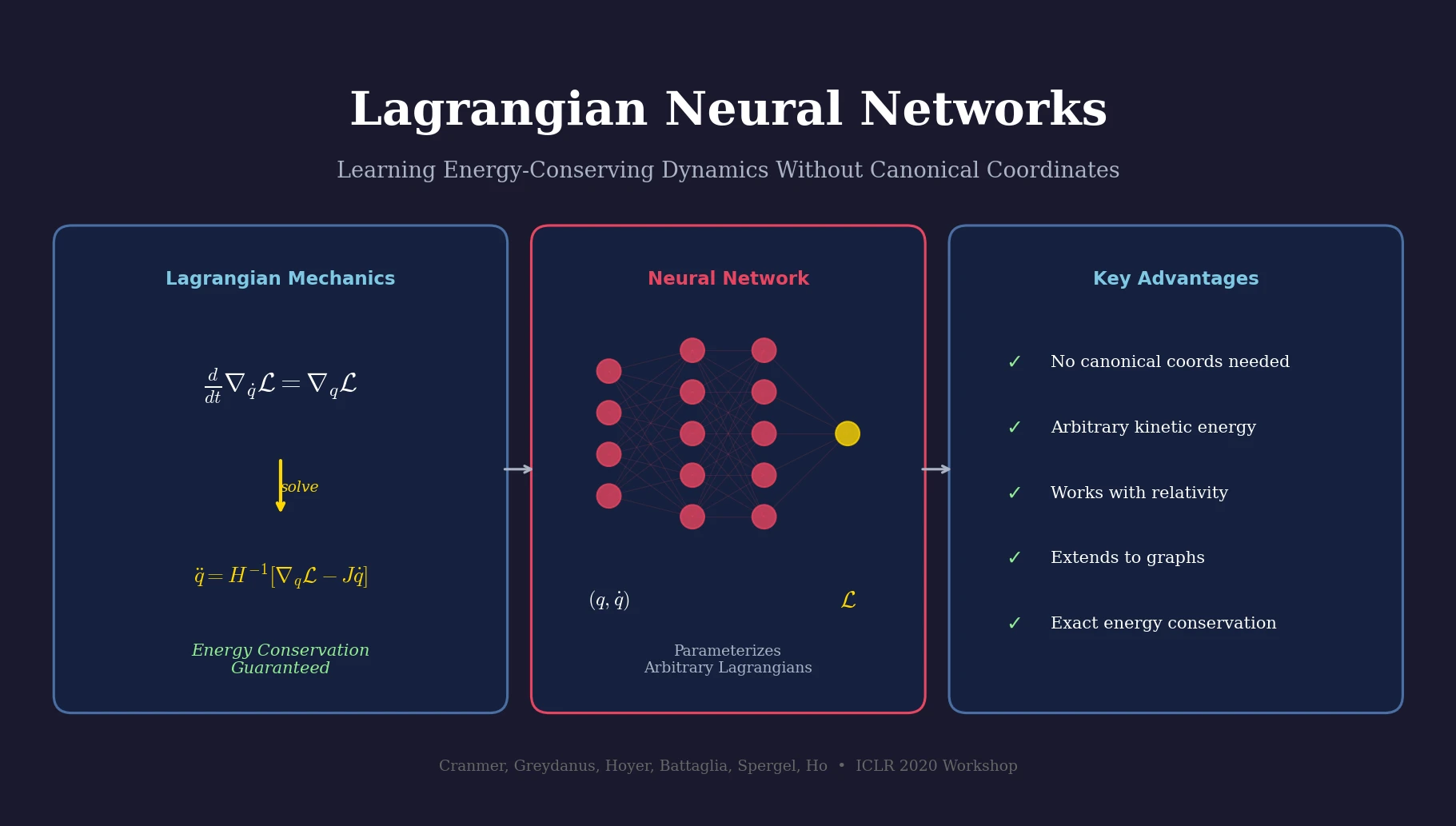
Lagrangian Neural Networks (LNNs) use neural networks to parameterize arbitrary Lagrangians, enabling energy-conserving learned dynamics without canonical coordinates. Unlike Hamiltonian approaches, LNNs handle relativistic systems and extend to graphs via Lagrangian Graph Networks.
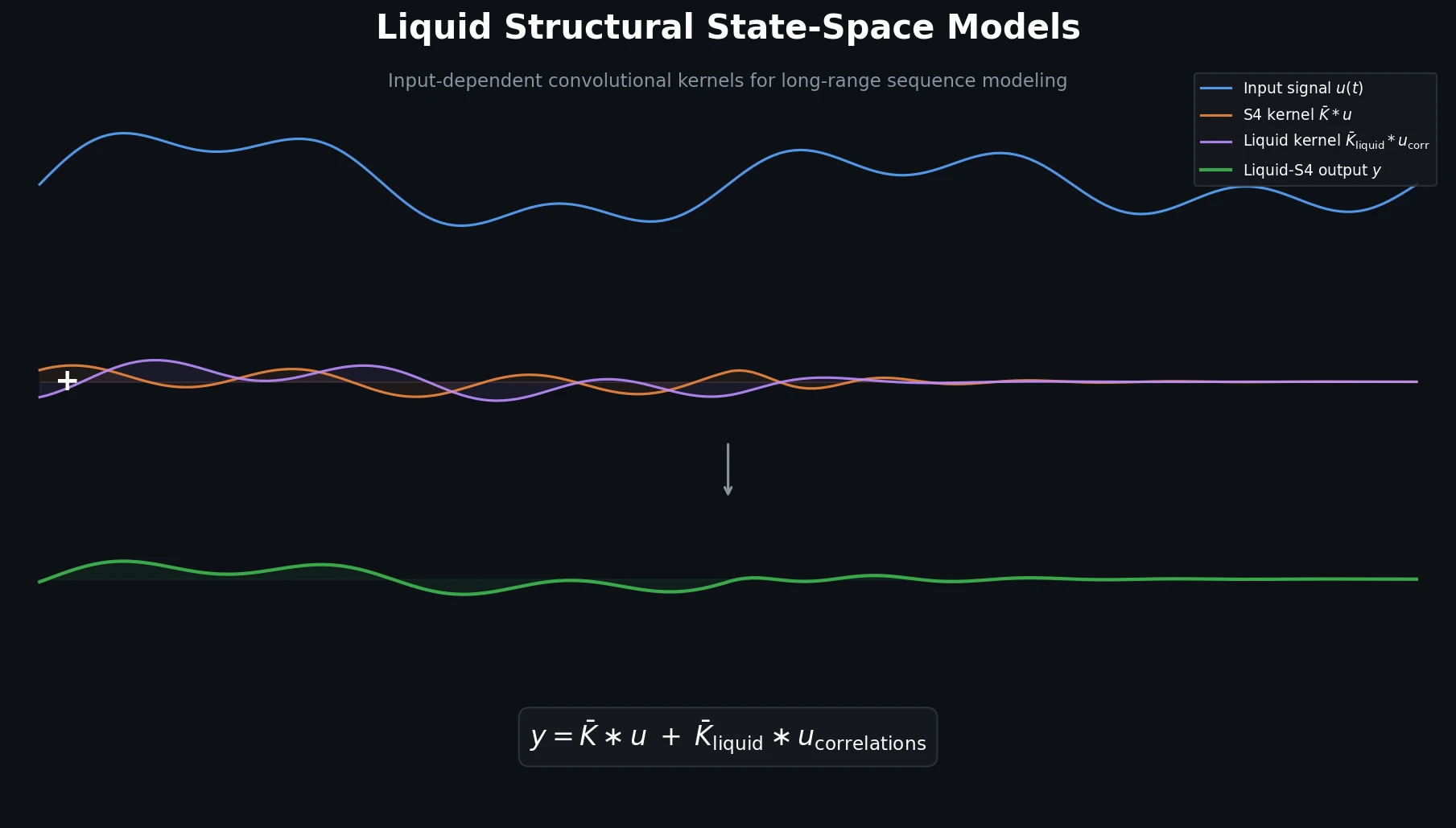
Liquid-S4 extends the S4 framework by incorporating a linearized liquid time-constant formulation that introduces input-dependent state transitions. This yields an additional convolutional kernel capturing input correlations, improving generalization across long-range sequence tasks.
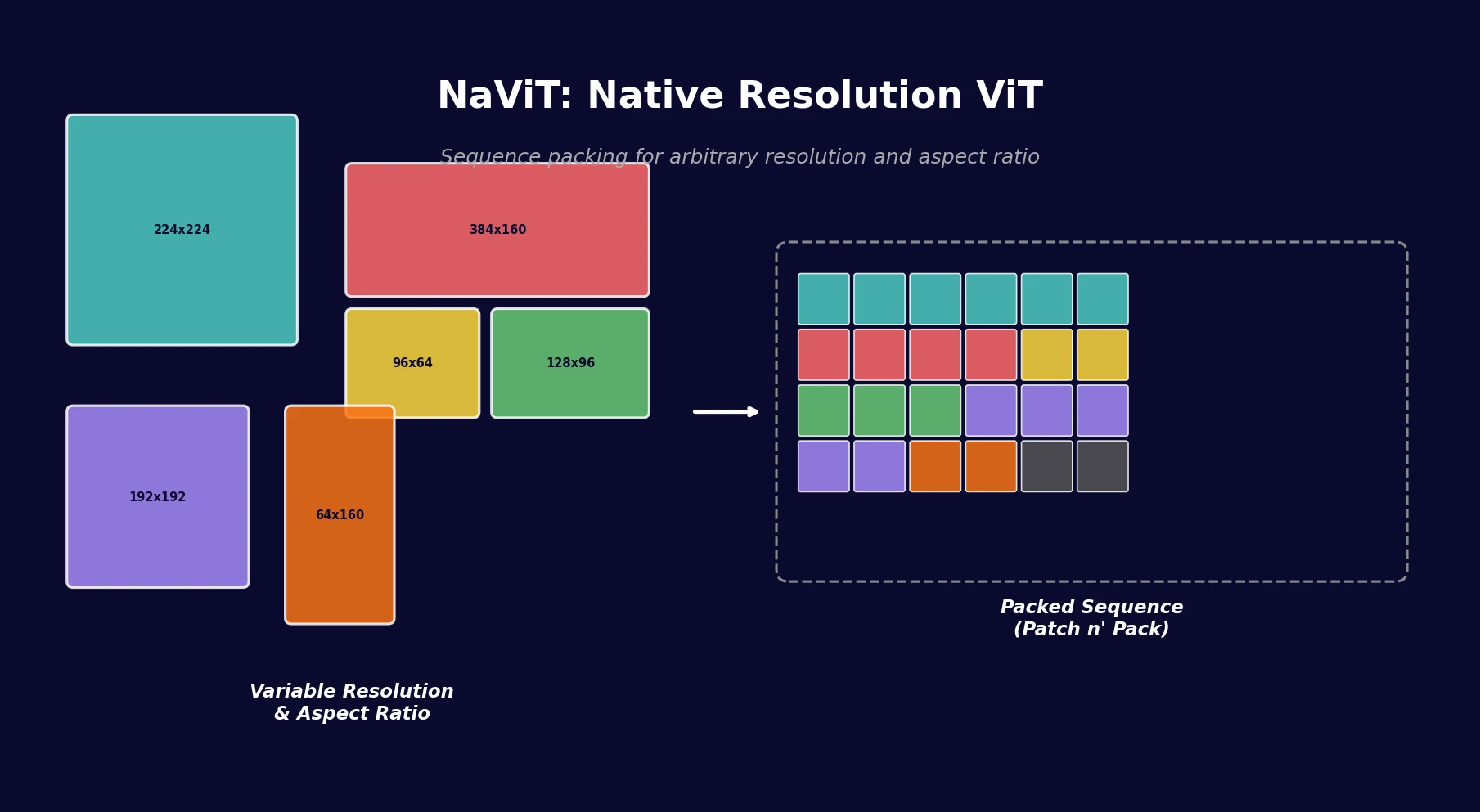
NaViT applies sequence packing (Patch n’ Pack) to Vision Transformers, enabling training on images of arbitrary resolution and aspect ratio while improving training efficiency by up to 4x over standard ViT.
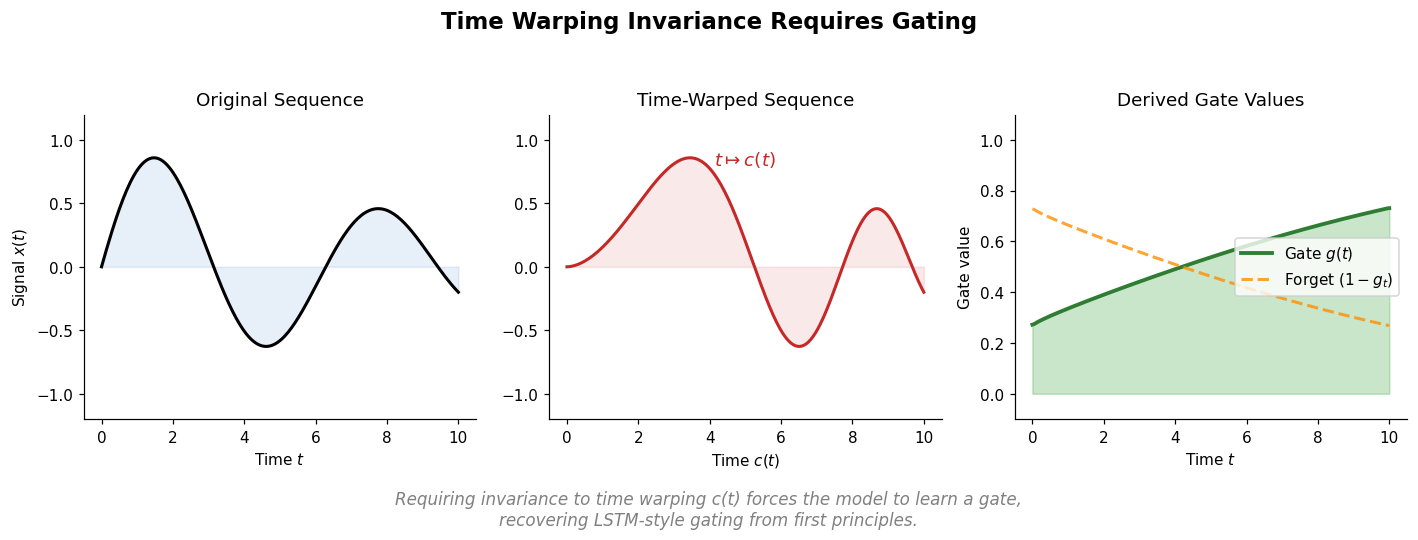
Tallec and Ollivier show that requiring invariance to time transformations in recurrent models leads to gating mechanisms, recovering key LSTM components from first principles. They propose the chrono initialization for gate biases that improves learning of long-term dependencies.
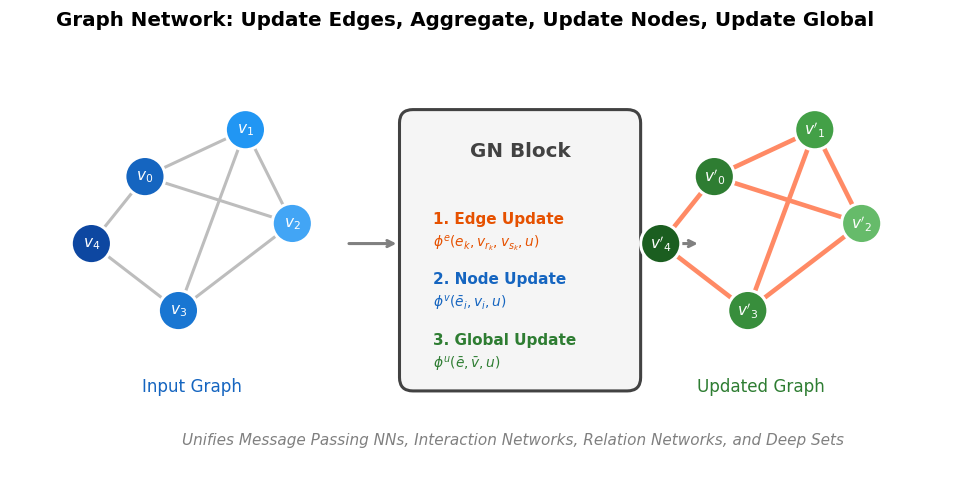
Battaglia et al. argue that combinatorial generalization requires structured representations, systematically analyze the relational inductive biases in standard deep learning architectures (MLPs, CNNs, RNNs), and present the graph network as a unifying framework that generalizes and extends prior graph neural network approaches.
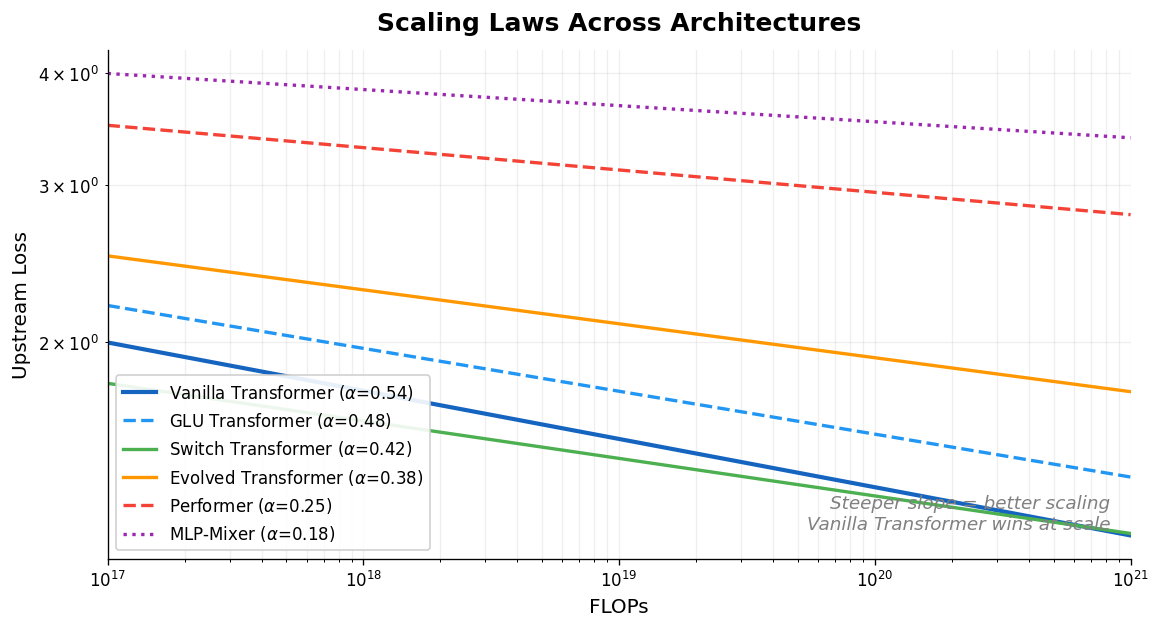
Tay et al. systematically compare scaling laws across ten diverse architectures (Transformers, Switch Transformers, Performers, MLP-Mixers, and others), finding that the vanilla Transformer has the best scaling coefficient and that the best-performing architecture changes across compute regions.

Fuchs et al. introduce the SE(3)-Transformer, which combines self-attention with SE(3)-equivariance for 3D point clouds and graphs. Invariant attention weights modulate equivariant value messages from tensor field networks, resolving angular filter constraints while enabling data-adaptive, anisotropic processing.
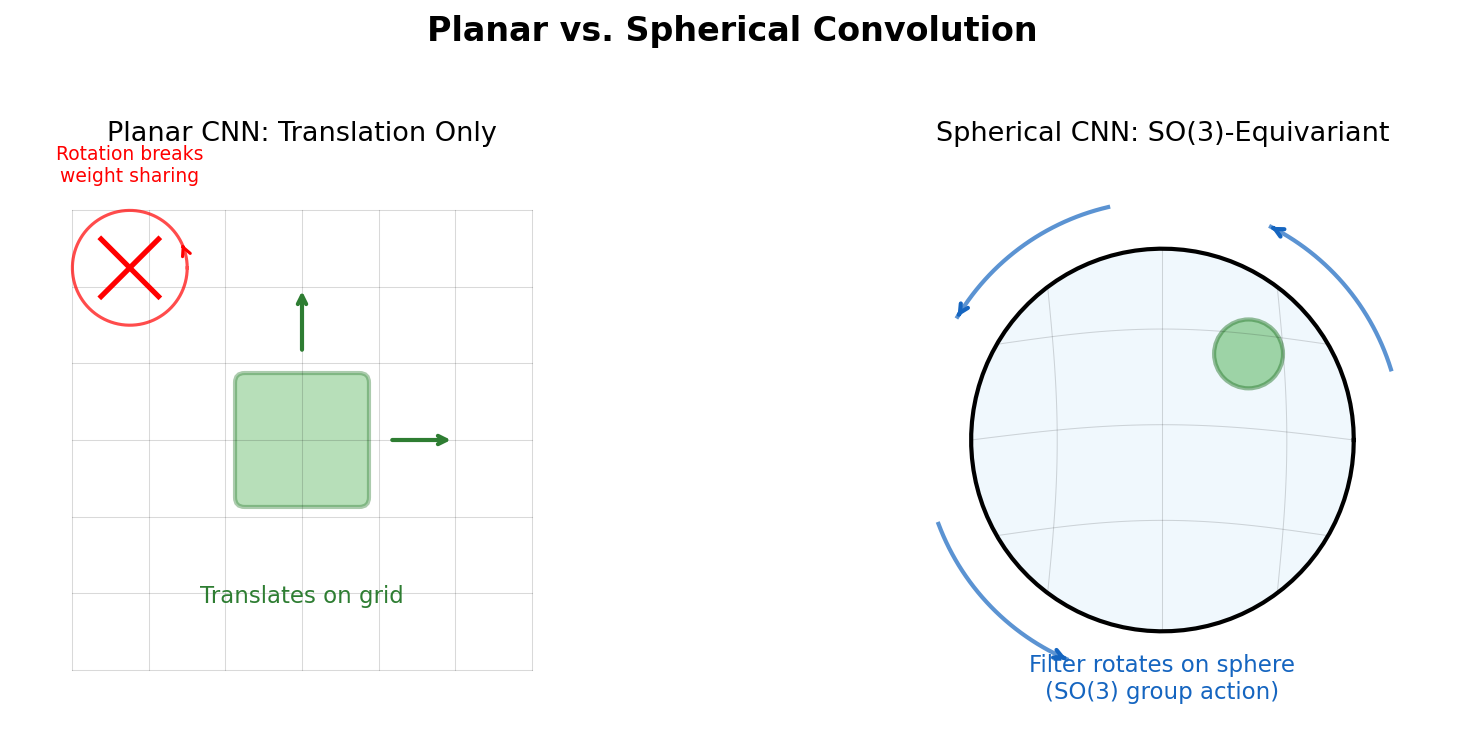
Cohen et al. introduce Spherical CNNs that achieve SO(3)-equivariance by defining cross-correlation on the sphere and rotation group, computed efficiently via generalized FFT algorithms from non-commutative harmonic analysis.
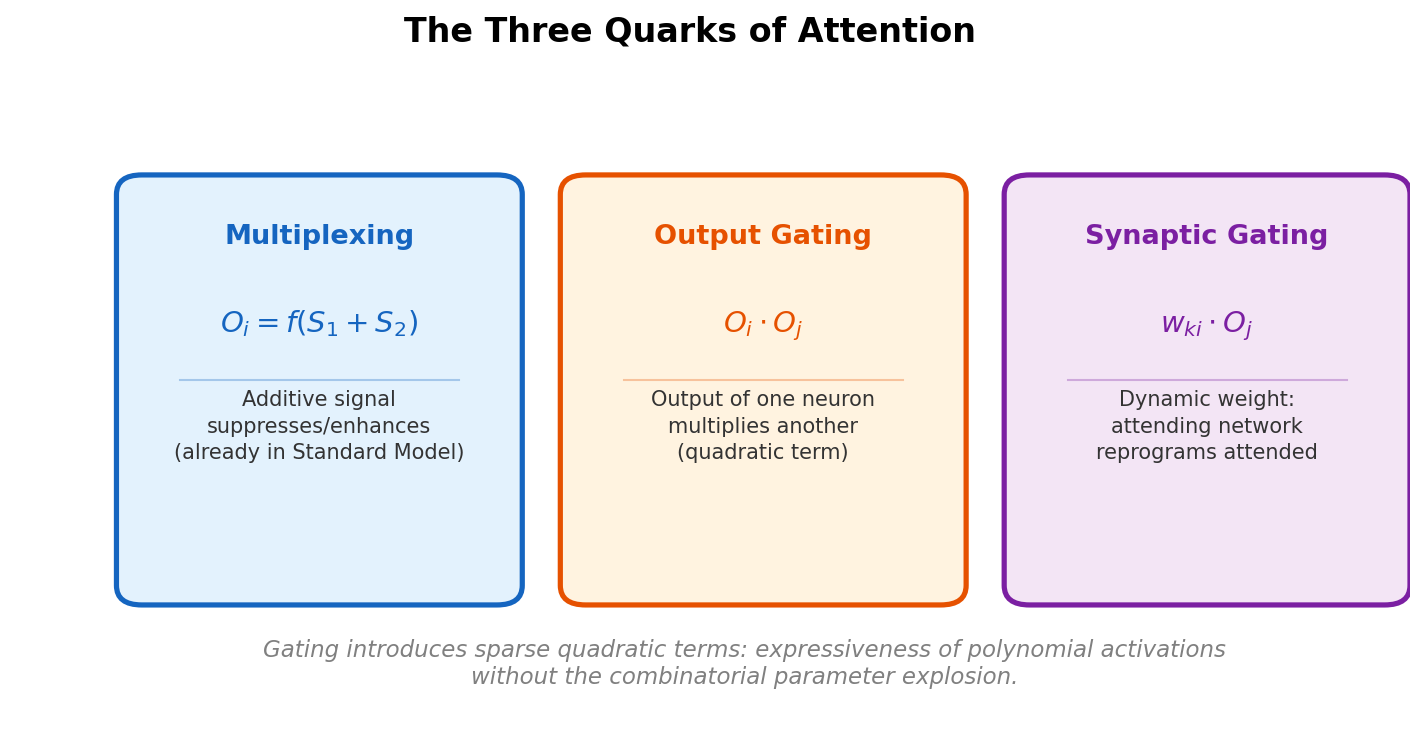
Baldi and Vershynin systematically classify the fundamental building blocks of attention (activation attention, output gating, synaptic gating) by source, target, and mechanism, then prove capacity bounds showing that gating introduces quadratic terms sparsely, gaining expressiveness without the full cost of polynomial activations.
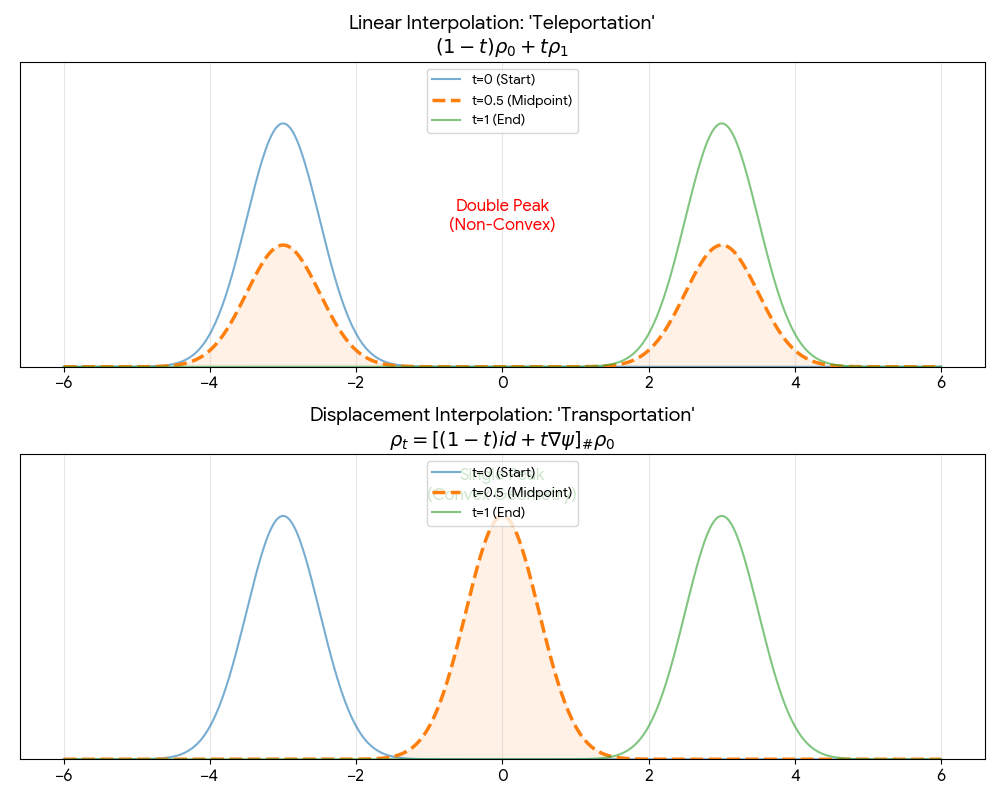
A theoretical paper that introduces displacement interpolation (optimal transport) to establish a new convexity principle for energy functionals. It proves the uniqueness of ground states for interacting gases and generalizes the Brunn-Minkowski inequality, providing mathematical tools later used in flow matching and optimal transport-based generative models.