
GutenOCR: A Grounded Vision-Language Front-End for Documents
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
We explore the ‘Silent Failure’ mode of LLMs in production: the limits of 99% accuracy for reliability, how confidence decays in long documents, and why standard calibration techniques struggle to fix it.
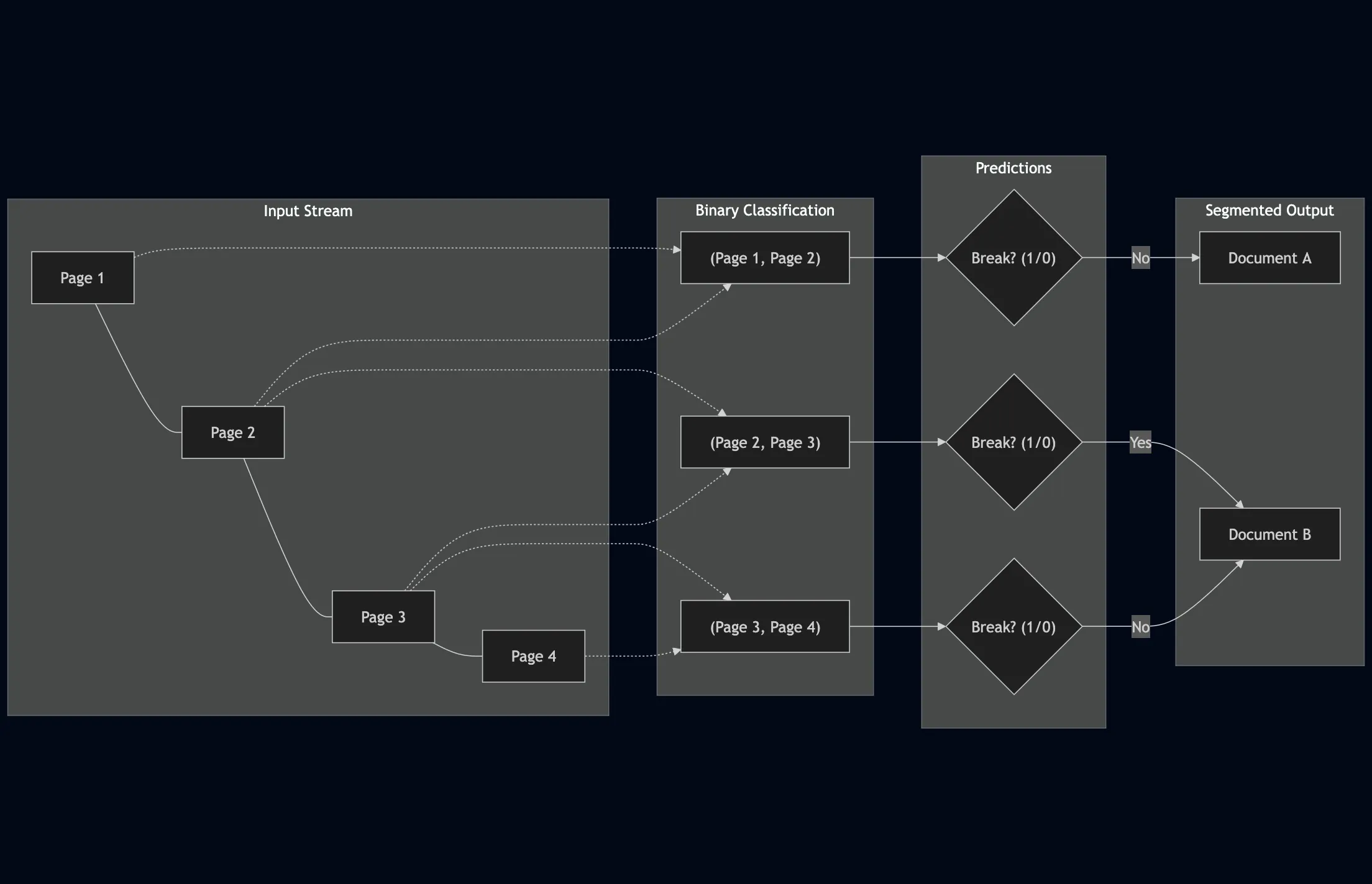
We trace the history of Page Stream Segmentation (PSS) through three eras (Heuristic, Encoder, and Decoder) and explain how privacy-preserving, localized LLMs enable true semantic processing.
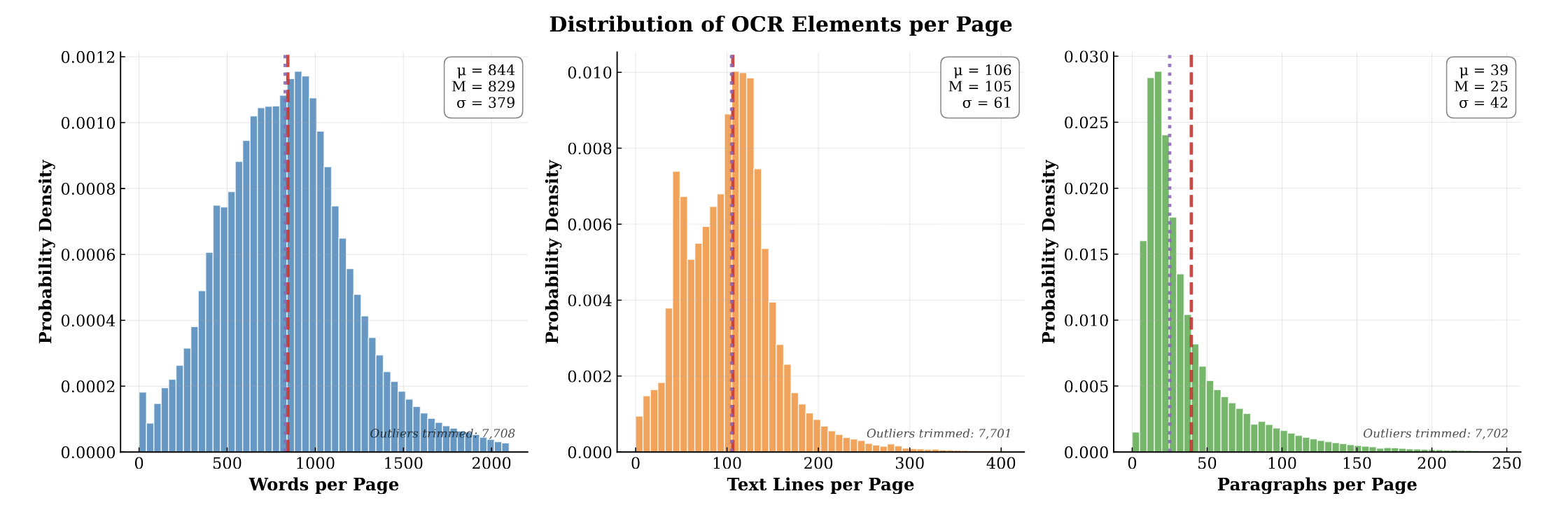
PubMed-OCR provides 1.5M pages of scientific articles with comprehensive OCR annotations and bounding boxes to support layout-aware modeling and document analysis.
We explore LLM applications for page stream segmentation in insurance document processing, demonstrating that parameter-efficient fine-tuning achieves strong accuracy but revealing significant calibration challenges that limit deployment confidence.
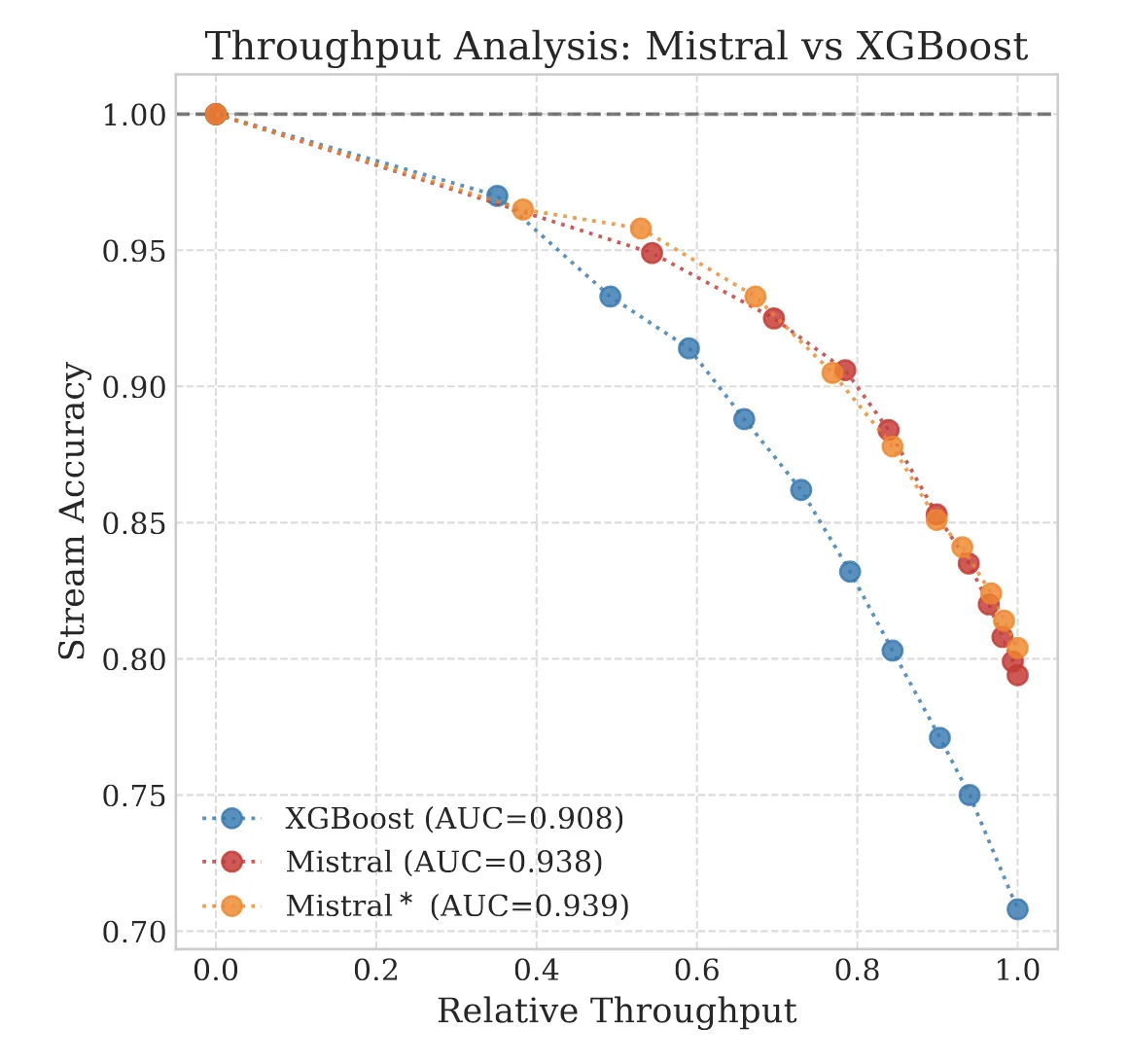
We create TabMe++, an enhanced page stream segmentation benchmark with commercial-grade OCR, and show that parameter-efficiently fine-tuned decoder-based LLMs like Mistral-7B achieve 80% straight-through processing rates, dramatically outperforming encoder-based models.