Count Vectorization (AKA One-Hot Encoding)
If you haven’t already, check out my previous blog post on word embeddings: Introduction to Word Embeddings.
In that blog post, we talk about a lot of the different ways we can represent words to use in machine learning. It’s a high level overview that we will expand upon here and check out how we can actually use count vectorization on some real text data.
A Recap of Count Vectorization
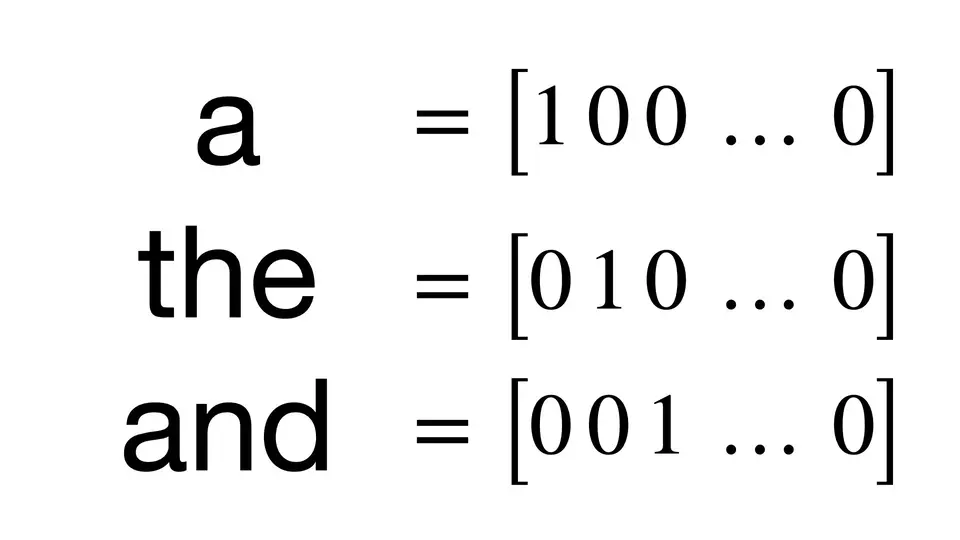
One-Hot Encoding: A visual representation of one-hot encoding for the words ‘a’, ’the’, and ‘and’
Today, we will be looking at one of the most basic ways we can represent text data numerically: one-hot encoding (or count vectorization). The idea is very simple.
We will be creating vectors that have a dimensionality equal to the size of our vocabulary, and if the text data features that vocab word, we will put a one in that dimension. Every time we encounter that word again, we will increase the count, leaving 0s everywhere we did not find the word even once.
The result of this will be very large vectors, if we use them on real text data, however, we will get very accurate counts of the word content of our text data. Unfortunately, this won’t provide use with any semantic or relational information, but that’s okay since that’s not the point of using this technique.
Today, we will be using the package from scikit-learn.
A Basic Example
Here is a basic example of using count vectorization to get vectors:
from sklearn.feature_extraction.text import CountVectorizer
# To create a Count Vectorizer, we simply need to instantiate one.
# There are special parameters we can set here when making the vectorizer, but
# for the most basic example, it is not needed.
vectorizer = CountVectorizer()
# For our text, we are going to take some text from our previous blog post
# about count vectorization
sample_text = ["One of the most basic ways we can numerically represent words "
"is through the one-hot encoding method (also sometimes called "
"count vectorizing)."]
# To actually create the vectorizer, we simply need to call fit on the text
# data that we wish to fix
vectorizer.fit(sample_text)
# Now, we can inspect how our vectorizer vectorized the text
# This will print out a list of words used, and their index in the vectors
print('Vocabulary: ')
print(vectorizer.vocabulary_)
# If we would like to actually create a vector, we can do so by passing the
# text into the vectorizer to get back counts
vector = vectorizer.transform(sample_text)
# Our final vector:
print('Full vector: ')
print(vector.toarray())
# Or if we wanted to get the vector for one word:
print('Hot vector: ')
print(vectorizer.transform(['hot']).toarray())
# Or if we wanted to get multiple vectors at once to build matrices
print('Hot and one: ')
print(vectorizer.transform(['hot', 'one']).toarray())
# We could also do the whole thing at once with the fit_transform method:
print('One swoop:')
new_text = ['Today is the day that I do the thing today, today']
new_vectorizer = CountVectorizer()
print(new_vectorizer.fit_transform(new_text).toarray())
Our output:
Vocabulary:
{'one': 12, 'of': 11, 'the': 15, 'most': 9, 'basic': 1, 'ways': 18, 'we': 19,
'can': 3, 'numerically': 10, 'represent': 13, 'words': 20, 'is': 7,
'through': 16, 'hot': 6, 'encoding': 5, 'method': 8, 'also': 0,
'sometimes': 14, 'called': 2, 'count': 4, 'vectorizing': 17}
Full vector:
[[1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 2 1 1 1 1 1]]
Hot vector:
[[0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
Hot and one:
[[0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0]]
One swoop:
[[1 1 1 1 2 1 3]]
Using Count Vectorization on Real Data
So let’s use it on some real data! We will check out the 20 News Group dataset that comes with scikit-learn.
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
# Create our vectorizer
vectorizer = CountVectorizer()
# Let's fetch all the possible text data
newsgroups_data = fetch_20newsgroups()
# Why not inspect a sample of the text data?
print('Sample 0: ')
print(newsgroups_data.data[0])
print()
# Create the vectorizer
vectorizer.fit(newsgroups_data.data)
# Let's look at the vocabulary:
print('Vocabulary: ')
print(vectorizer.vocabulary_)
print()
# Converting our first sample into a vector
v0 = vectorizer.transform([newsgroups_data.data[0]]).toarray()[0]
print('Sample 0 (vectorized): ')
print(v0)
print()
# It's too big to even see...
# What's the length?
print('Sample 0 (vectorized) length: ')
print(len(v0))
print()
# How many words does it have?
print('Sample 0 (vectorized) sum: ')
print(np.sum(v0))
print()
# What if we wanted to go back to the source?
print('To the source:')
print(vectorizer.inverse_transform(v0))
print()
# So all this data has a lot of extra garbage... Why not strip it away?
newsgroups_data = fetch_20newsgroups(remove=('headers', 'footers', 'quotes'))
# Why not inspect a sample of the text data?
print('Sample 0: ')
print(newsgroups_data.data[0])
print()
# Create the vectorizer
vectorizer.fit(newsgroups_data.data)
# Let's look at the vocabulary:
print('Vocabulary: ')
print(vectorizer.vocabulary_)
print()
# Converting our first sample into a vector
v0 = vectorizer.transform([newsgroups_data.data[0]]).toarray()[0]
print('Sample 0 (vectorized): ')
print(v0)
print()
# It's too big to even see...
# What's the length?
print('Sample 0 (vectorized) length: ')
print(len(v0))
print()
# How many words does it have?
print('Sample 0 (vectorized) sum: ')
print(np.sum(v0))
print()
# What if we wanted to go back to the source?
print('To the source:')
print(vectorizer.inverse_transform(v0))
print()
Our output:
Sample 0:
From: [email protected] (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small. In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
Thanks,
- IL
---- brought to you by your neighborhood Lerxst ----
Vocabulary:
{'from': 56979, 'lerxst': 75358, 'wam': 123162, 'umd': 118280, 'edu': 50527,
'where': 124031, 'my': 85354, 'thing': 114688, 'subject': 111322,
'what': 123984, 'car': 37780, 'is': 68532, 'this': 114731, 'nntp': 87620,
'posting': 95162, 'host': 64095, 'rac3': 98949, 'organization': 90379,
'university': 118983, 'of': 89362, 'maryland': 79666,
'college': 40998, ... } (Abbreviated...)
Sample 0 (vectorized):
[0 0 0 ... 0 0 0]
Sample 0 (vectorized) length:
130107
Sample 0 (vectorized) sum:
122
To the source:
[array(['15', '60s', '70s', 'addition', 'all', 'anyone', 'be', 'body',
'bricklin', 'brought', 'bumper', 'by', 'called', 'can', 'car',
'college', 'could', 'day', 'door', 'doors', 'early', 'edu',
'engine', 'enlighten', 'from', 'front', 'funky', 'have', 'history',
'host', 'if', 'il', 'in', 'info', 'is', 'it', 'know', 'late',
'lerxst', 'lines', 'looked', 'looking', 'made', 'mail', 'maryland',
'me', 'model', 'my', 'name', 'neighborhood', 'nntp', 'of', 'on',
'or', 'organization', 'other', 'out', 'park', 'please', 'posting',
'production', 'rac3', 'really', 'rest', 'saw', 'separate', 'small',
'specs', 'sports', 'subject', 'tellme', 'thanks', 'the', 'there',
'thing', 'this', 'to', 'umd', 'university', 'wam', 'was', 'were',
'what', 'whatever', 'where', 'wondering', 'years', 'you', 'your'],
dtype='<U180')]
Sample 0:
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small. In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
Vocabulary:
{'was': 95844, 'wondering': 97181, 'if': 48754, 'anyone': 18915, 'out': 68847,
'there': 88638, 'could': 30074, 'enlighten': 37335, 'me': 60560, 'on': 68080,
'this': 88767, 'car': 25775, 'saw': 80623, 'the': 88532, 'other': 68781,
'day': 31990, 'it': 51326, 'door': 34809, 'sports': 84538, 'looked': 57390,
'to': 89360, 'be': 21987, 'from': 41715, 'late': 55746, '60s': 9843,
'early': 35974, '70s': 11174, 'called': 25492, 'bricklin': 24160, 'doors': 34810,
'were': 96247, 'really': 76471, ... } (Abbreviated...)
Sample 0 (vectorized):
[0 0 0 ... 0 0 0]
Sample 0 (vectorized) length:
101631
Sample 0 (vectorized) sum:
85
To the source:
[array(['60s', '70s', 'addition', 'all', 'anyone', 'be', 'body',
'bricklin', 'bumper', 'called', 'can', 'car', 'could', 'day',
'door', 'doors', 'early', 'engine', 'enlighten', 'from', 'front',
'funky', 'have', 'history', 'if', 'in', 'info', 'is', 'it', 'know',
'late', 'looked', 'looking', 'made', 'mail', 'me', 'model', 'name',
'of', 'on', 'or', 'other', 'out', 'please', 'production', 'really',
'rest', 'saw', 'separate', 'small', 'specs', 'sports', 'tellme',
'the', 'there', 'this', 'to', 'was', 'were', 'whatever', 'where',
'wondering', 'years', 'you'], dtype='<U81')]
Now What?
So, you may be wondering what now? We know how to vectorize these things based on counts, but what can we actually do with any of this information?
Well, for one, we could do a bunch of analysis. We could look at term frequency, we could remove stop words, we could visualize things, and we could try and cluster. Now that we have these numeric representations of this textual data, there is so much we can do that we couldn’t do before!
But let’s make this more concrete. We’ve been using this text data from the 20 News Group dataset. Why not use it on a task?
The 20 News Group dataset is a dataset of posts on a board, split up into 20 different categories. Why not use our vectorization to try and categorize this data?
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
# Create our vectorizer
vectorizer = CountVectorizer()
# All data
newsgroups_train = fetch_20newsgroups(subset='train',
remove=('headers', 'footers', 'quotes'))
newsgroups_test = fetch_20newsgroups(subset='test',
remove=('headers', 'footers', 'quotes'))
# Get the training vectors
vectors = vectorizer.fit_transform(newsgroups_train.data)
# Build the classifier
clf = MultinomialNB(alpha=.01)
# Train the classifier
clf.fit(vectors, newsgroups_train.target)
# Get the test vectors
vectors_test = vectorizer.transform(newsgroups_test.data)
# Predict and score the vectors
pred = clf.predict(vectors_test)
acc_score = metrics.accuracy_score(newsgroups_test.target, pred)
f1_score = metrics.f1_score(newsgroups_test.target, pred, average='macro')
print('Total accuracy classification score: {}'.format(acc_score))
print('Total F1 classification score: {}'.format(f1_score))
Our output:
Total accuracy classification score: 0.6460435475305364
Total F1 classification score: 0.6203806145034193
Hmmm… So not super fantastic, but we are just using count vectors! A richer representation would do wonders for our scores!